Начнём с привычной ловушки. Когда на столе лежит «сырое» CPUE и график по годам, очень хочется увидеть в нём прямое отражение численности запаса и, тем самым, штурвал управления промыслом. Это эффект удобной истории: мозг мгновенно дорисовывает причинность там, где в данных много посторонней вариации — сезон, район, глубина, тип орудий, «почерк» судна, длительность постановок. Если эту вариацию не отделить, CPUE превращается в градусник, который меняет показания температуры тела вместе с погодой в комнате. Наша задача в этом занятии — аккуратно «изолировать» измерение: стандартизировать CPUE так, чтобы оно преимущественно отражало динамику запаса, а не всё остальное.
Что именно мы стандартизируем. CPUE — это маркер доступной части популяции при данных условиях промысла. Мы хотим извлечь из него индекс, сопоставимый между годами, сведя к «норме» всё, что не про численность или биомассу запаса: различия по месяцам, районам, глубинам, орудиям, судам. Ключ — заранее определить целевой «эталон»: к чему приводим? К маргинальным средним по дизайну (сбалансированная виртуальная съёмка) или к фиксированному референс‑уровню (базовый месяц/район/судно)? Первый вариант лучше отражает «среднедоступную» систему, второй — удобен для прозрачной интерпретации. Оба корректны, если оговорены и последовательно применяются.
Почему GLM/GAM/GAMM. GLM с гамма‑распределением и лог‑ссылкой — рабочая лошадка для положительных, правоскошенных величин; лог‑связь естественно переводит эффекты в относительные (мультипликативные) изменения. GAM добавляет гибкость: там, где линейные контрасты по глубине или температуре ломают картину, гладкие функции честно показывают оптимумы и изгибы. GAMM вводит случайные эффекты (например, по судну), отделяя структурные тенденции от «личной биографии» флотилии — то, что в фиксированных эффектах превращается в лишний шум и завышенную уверенность. Выбор не догматичен: начинаем с простого GLM, расширяем до GAM, добавляем случайные эффекты только тогда, когда это подтверждается диагностикой и улучшает калибровку индекса.
Про подводные камни, которые мы будем ловить. Во‑первых, нули и «почти нули»: для гамма‑семейства понадобится аккуратная положительная поправка; если нулей много, разумна двухступенчатая дельта‑постановка (биномиальная часть + положительная часть). Во‑вторых, дрейф уловистости (q‑drift): изменение орудий и практик может имитировать «падение запаса». Мы не устраняем его магией, но делаем явным — через факторы/ковариаты и, при необходимости, случайные эффекты. В‑третьих, утечка информации из будущего: сравнивая индексы, мы придерживаемся блокировок по годам и не «подмешиваем» композиционные сдвиги выборки (например, если флот переместился в другой район). В‑четвёртых, concurvity/мультиколлинеарность: GAM может «переобъяснить» одно и то же несколькими гладкими — проверяем concurvity и упрощаем формулу. И, конечно, диагностика остатков (DHARMa), проверка дисперсии и влияния наблюдений — обязательна перед любыми управленческими выводами.
Как читать результат. Стандартизированный индекс — это не абсолютная биомасса и не прогноз улова; это аккуратно отчищенный маркер относительной доступности/численности, сопоставимый между годами при прочих равных. Он публикуется с доверительными интервалами и явной оговоркой о референсе (маргинальные средние или фиксированный профиль). Нормирование «к среднему» или «к первому году» — это про удобство сравнения, а не про «истинную шкалу». Чувствительность к выбору формулы (GLM vs GAM vs GAMM), к набору факторов и к способу усреднения — часть честного отчёта: если индексы согласованы, доверие растёт; если нет — разбираем, где скрыт драйвер расхождений.
Что делаем по шагам. Загружаем и чистим данные (включая корректную работу с нулями и факторами), строим GLM (Gamma‑log) с ключевыми факторами (год, сезон, район, судно), проверяем остатки и считаем маргинальные индексы с интервалами. Затем ставим GAM там, где предметная логика допускает нелинейности, и повторяем диагностику (gam.check, concurvity). После — GAMM со случайным эффектом по судну, чтобы отделить «командный почерк» от тренда, и оцениваем индекс через предсказания на сбалансированной сетке и бутстреп‑интервалы. Финально сводим индексы на одном графике вместе с фактическими медианами CPUE и сравниваем модели по AIC/BIC и адекватности остатков. Если «сложнее» не лучше — остаёмся на более простой, но калиброванной модели.
И напоследок — про уверенность. Хорошая стандартизация CPUE — это не способ «победить» неопределённость, а способ честно на неё смотреть. Мы покажем не только линию, но и ленту интервалов; не только медиану, но и альтернативы формул; не только тренд, но и диагностику. Это ровно тот прогресс, который работает в долгую: меньше иллюзий контроля, больше прозрачности, лучше решения.
Установите необходимые пакеты : install.packages(c("readxl", "tidyverse, "mgcv", "gamm4", "DHARMa" ))и др.
10.2 Пошаговое описание скрипта
Скрипт начинается с загрузки необходимых пакетов для обработки данных, построения моделей и визуализации результатов. Среда настраивается путем установки рабочей директории и фиксации случайного зерна для обеспечения воспроизводимости всех последующих вычислений.
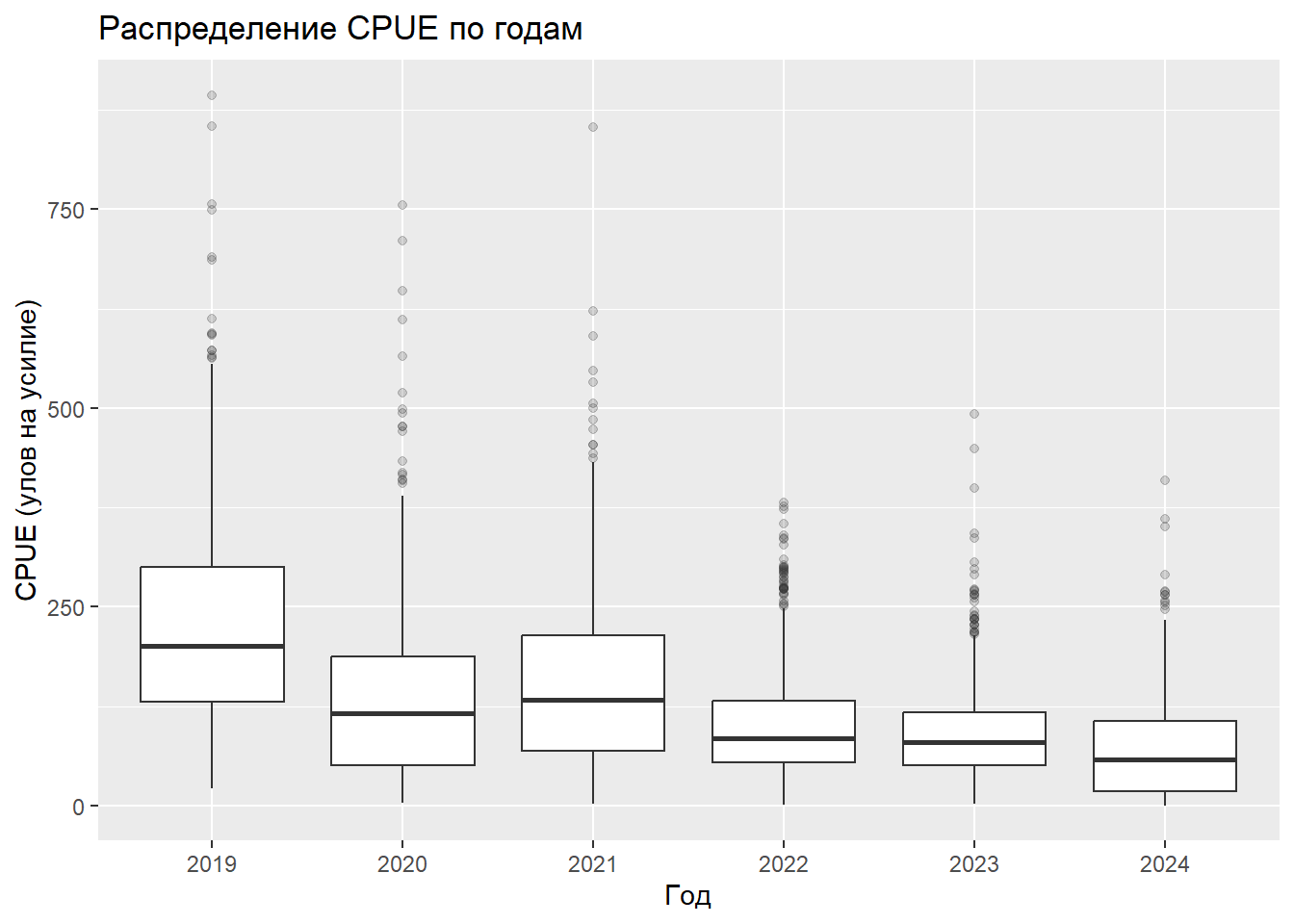
На следующем этапе происходит загрузка исходных данных из файла Excel. Данные представляют собой промысловую статистику, содержащую информацию о году, месяце, судне, районе, величине улова на усилие (CPUE) и др. Выполняется их предварительная обработка: фильтрация по осенним месяцам, преобразование типов переменных в факторы и числовой формат, а также удаление пропущенных значений. Поскольку для моделирования с гамма-распределением требуются строго положительные значения, для нулевых и отрицательных величин CPUE рассчитывается и добавляется малая поправка. Для первичного ознакомления с данными строится диаграмма размаха, показывающая распределение CPUE по годам.
Далее определяются вспомогательные функции. Одна функция предназначена для нормировки рассчитанных индексов либо на среднее значение, либо на значение первого года. Другая функция использует метод маргинальных средних для расчета стандартизированных индексов и их доверительных интервалов на основе подобранной модели. Третья функция реализует расчет индексов и оценку неопределенности через бутстреп для моделей со сложной структурой.
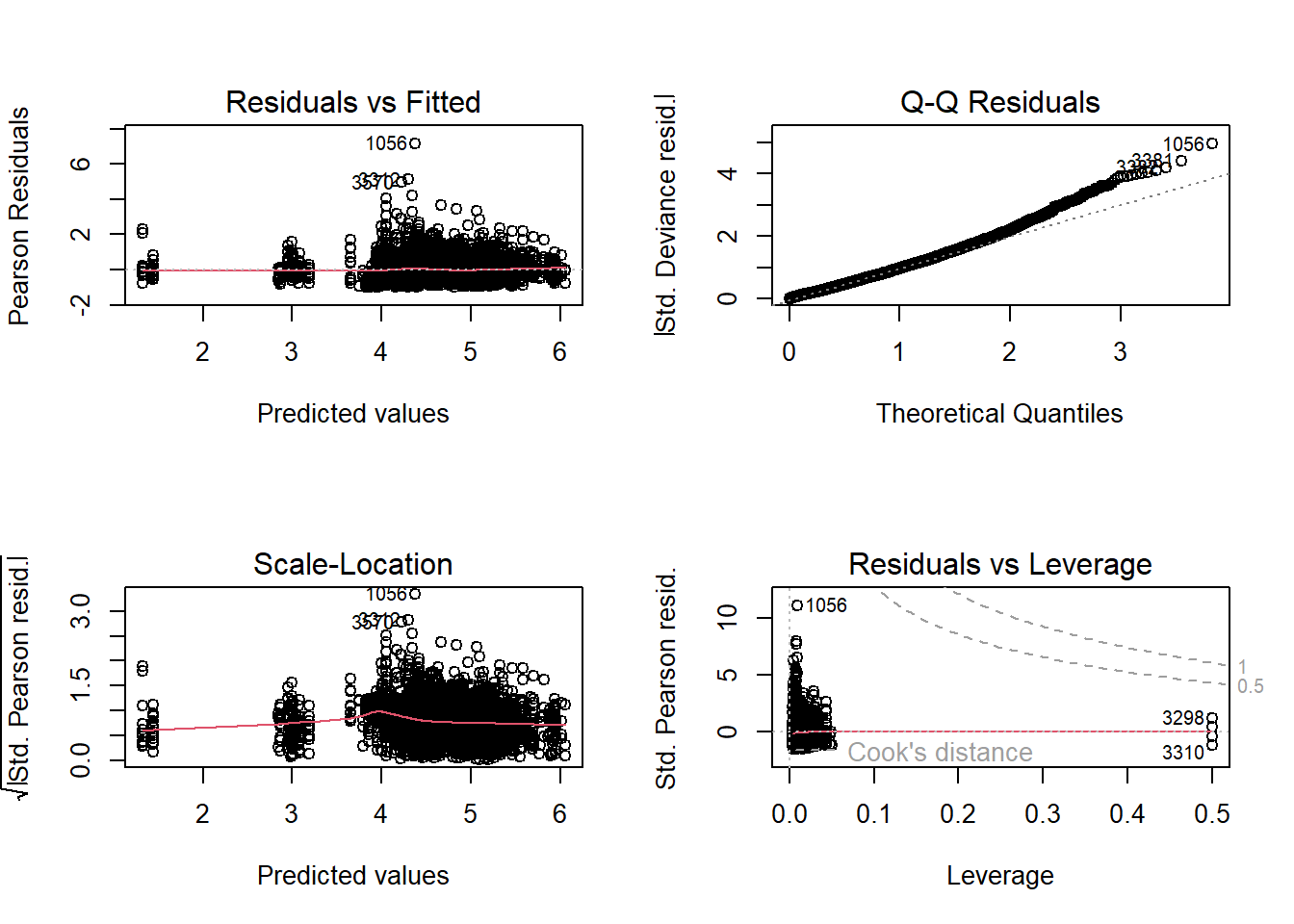
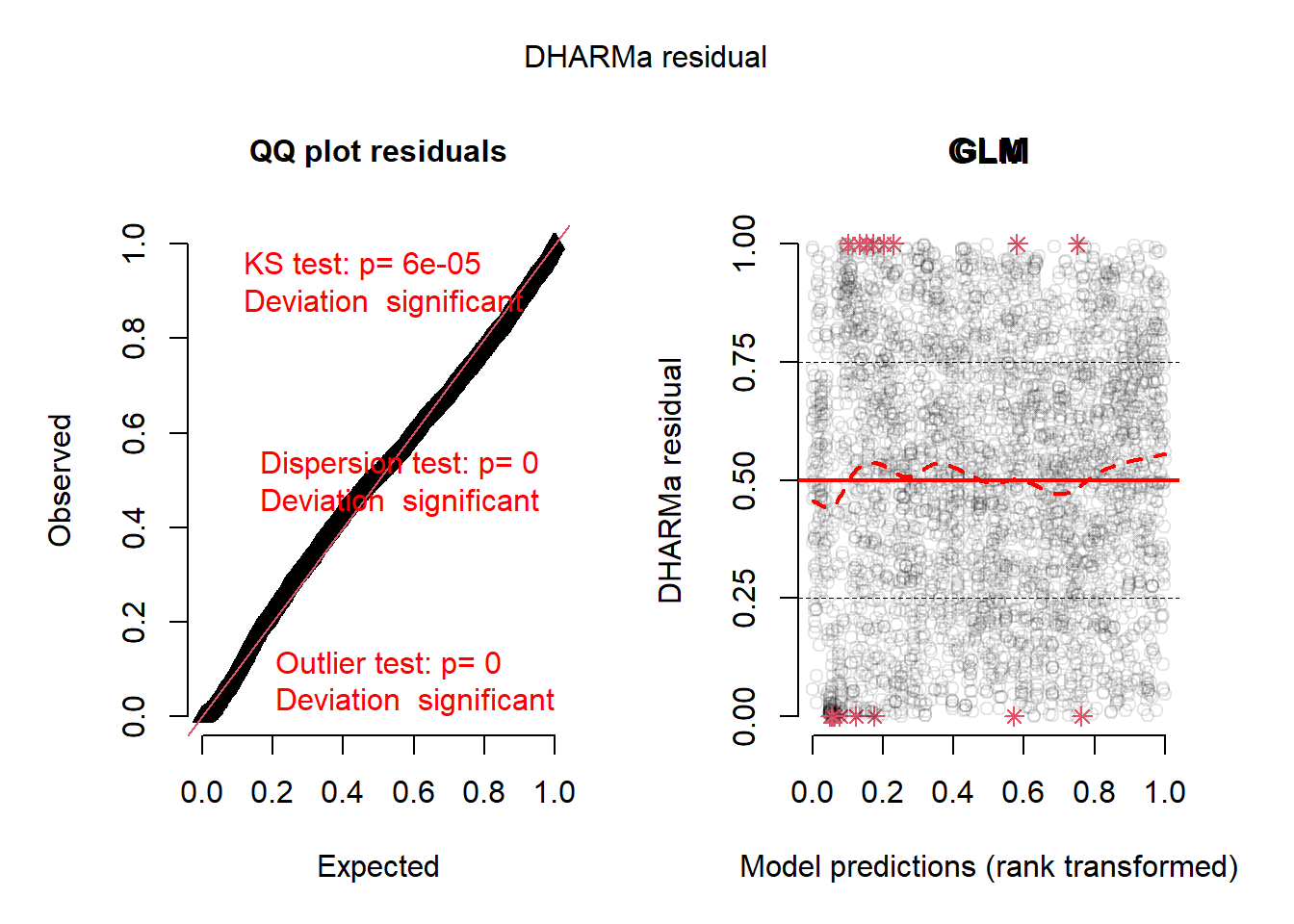
Основная часть скрипта посвящена построению и анализу трех типов моделей. Первой подбирается обобщенная линейная модель (GLM) с гамма-распределением ошибок и логарифмической связью. В качестве предикторов используются факторы: год, месяц, судно и район. Для визуальной и численной диагностики адекватности модели выводятся ее сводка, таблица коэффициентов, стандартные диагностические графики и графики остатков, проверенные с помощью пакета DHARMa.
Следующей строится обобщенная аддитивная модель (GAM). На этом этапе используется та же формула и семейство распределений, что и в GLM, но метод подбора гиперпараметров отличается. Проводится аналогичная диагностика модели с помощью функций summary и gam.check.
Затем подбирается обобщенная аддитивная смешанная модель (GAMM), которая дополнительно включает случайный эффект от судна. Это позволяет учесть вариацию, вызванную индивидуальными особенностями каждого судна, которые не описываются другими факторами. Диагностика этой модели более сложна и включает анализ остатков, проверку случайных эффектов и тест на гетероскедастичность.
После построения всех моделей для каждой из них рассчитываются стандартизированные индексы CPUE и их доверительные интервалы. Для GLM и GAM это делается с помощью функции, основанной на маргинальных средних, а для GAMM применяется метод бутстрепа.
Финальный этап включает объединение результатов всех трех моделей в единую таблицу и их визуальное сравнение на графике. На этот же график добавляются фактические медианные значения CPUE по годам из исходных данных для сопоставления со стандартизированными кривыми. В заключение модели сравниваются по информационным критериям (AIC, BIC) и другим метрикам, чтобы дать рекомендации по выбору наиболее адекватной из них.
Ниже приводится скрипт, а ниже скрипта - описание результатов моделирования.
# ========================================================================================================================# ПРАКТИЧЕСКОЕ ЗАНЯТИЕ: СТАНДАРТИЗАЦИЯ CPUE С ИСПОЛЬЗОВАНИЕМ GLM, GAM И GAMM# Курс: "Оценка водных биоресурсов в среде R (для начинающих)"# Автор: Баканев С.В. # Дата: 20.08.2025# # Структура:# 1) Загрузка пакетов и настройка среды# 2) Загрузка и предварительная обработка данных# 3) Вспомогательные функции для расчета индексов# 4) Моделирование GLM (Gamma с лог-ссылкой)# 5) Моделирование GAM (обобщенная аддитивная модель)# 6) Моделирование GAMM (смешанная модель со случайными эффектами)# 7) Сравнение моделей и финальная визуализация результатов# ========================================================================================================================# ==============================================================================# БЛОК 1: ЗАГРУЗКА ПАКЕТОВ И НАСТРОЙКА СРЕДЫ# ==============================================================================# Отключаем вспомогательные сообщения при загрузке пакетовsuppressPackageStartupMessages({library(tidyverse) # Основные пакеты для обработки данных и визуализацииlibrary(readxl) # Чтение данных из Excel-файловlibrary(mgcv) # Обобщенные аддитивные модели (GAM)library(gamm4) # GAM со смешанными эффектамиlibrary(emmeans) # Расчет маргинальных средних и контрастовlibrary(broom) # Преобразование результатов моделей в таблицыlibrary(broom.mixed) # Поддержка смешанных моделей для broomlibrary(DHARMa) # Диагностика остатков обобщенных моделейlibrary(knitr) # Форматирование таблиц для отчетов})# Установка рабочей директорииsetwd("C:/GLM/")# Фиксируем случайное зерно для воспроизводимости результатовset.seed(42)# ==============================================================================# БЛОК 2: ЗАГРУЗКА И ПРЕДОБРАБОТКА ДАННЫХ# ==============================================================================# Определяем путь к файлу с даннымиDATA_PATH <-"C:/GLM/data/KARTOGRAPHIC.xlsx"# Чтение данных из листа "FISHERY" и фильтрация осенних месяцевDATA <-read_excel(DATA_PATH, sheet ="FISHERY") %>%as_tibble() %>%# Преобразуем в современный формат таблицыfilter(MONTH >8& MONTH <12) # Сентябрь-ноябрь (осенний сезон)# Преобразование типов переменных и обработка пропусковDATA <- DATA %>%mutate(YEAR =as.factor(YEAR), # Год как категориальная переменнаяMONTH =as.factor(MONTH), # Месяц как факторCALL =as.factor(CALL), # Идентификатор суднаREGION =as.factor(REGION), # Рыбохозяйственный районVESSELNUMBER =as.factor(VESSELNUMBER), # Номер суднаCPUE =as.numeric(CPUE) # Целевой показатель - улов на усилие ) %>%filter(!is.na(CPUE)) # Удаление строк с пропусками в CPUE# Обработка нулевых значений CPUE для Gamma-моделейif (any(DATA$CPUE <=0, na.rm =TRUE)) { min_pos <-min(DATA$CPUE[DATA$CPUE >0], na.rm =TRUE) # Минимальный положительный улов offset <- min_pos /2# Величина поправки DATA <- DATA %>%mutate(CPUE_POS =if_else(CPUE <=0, CPUE + offset, CPUE)) # Добавляем поправку} else { DATA <- DATA %>%mutate(CPUE_POS = CPUE) # Исходные данные если нулей нет}# Рассчитываем медианные значения CPUE по годам из исходных данныхactual_medians <- DATA %>%group_by(YEAR) %>%summarise(median_cpue =median(CPUE, na.rm =TRUE))# Рассчитываем медианные значения CPUE по годам из исходных данных для последующих графиковactual_medians
# A tibble: 6 x 2
YEAR median_cpue
<fct> <dbl>
1 2019 200.
2 2020 116.
3 2021 132.
4 2022 84
5 2023 79.4
6 2024 58.3
# Экспресс-визуализация распределения CPUE по годамDATA %>%ggplot(aes(x = YEAR, y = CPUE)) +geom_boxplot(outlier.alpha =0.2) +labs(title ="Распределение CPUE по годам", x ="Год", y ="CPUE (улов на усилие)")
# ==============================================================================# БЛОК 3: ВСПОМОГАТЕЛЬНЫЕ ФУНКЦИИ ДЛЯ РАСЧЕТА ИНДЕКСОВ# ==============================================================================# Функция нормировки индексовscale_to_index <-function(values, method =c("mean", "first")) { method <-match.arg(method)if (method =="mean") {# Нормировка на среднее значениеreturn(as.numeric(values) /mean(as.numeric(values), na.rm =TRUE)) }if (method =="first") {# Нормировка на значение первого годаreturn(as.numeric(values) /as.numeric(values[1])) }}# Функция расчета индексов для GLM/GAM через маргинальные средниеemmeans_standardized_index <-function(model, variable ="YEAR") { out <-suppressWarnings(emmeans(model, specs =as.formula(paste0("~ ", variable)), type ="response") ) df <-as_tibble(out) %>%select(!!sym(variable), response = response, lower.CL, upper.CL)colnames(df) <-c("YEAR", "value", "lcl", "ucl") df}# Функция расчета индексов для GAMM через бутстрепcompute_standardized_index <-function(model, base_data, year_levels, predict_fun,response_transform = identity, n_boot =200L, seed =7L) {set.seed(seed) acc <-vector("list", length(year_levels))for (i inseq_along(year_levels)) { newdata <- base_data newdata$YEAR <-factor(year_levels[i], levels =levels(base_data$YEAR)) preds <-suppressWarnings(predict_fun(model, newdata)) mu <-mean(response_transform(preds), na.rm =TRUE)# Бутстреп для оценки неопределенности boot_vals <-replicate(n_boot, { idx <-sample.int(nrow(base_data), nrow(base_data), replace =TRUE) bd <- newdata[idx, , drop =FALSE] p <-suppressWarnings(predict_fun(model, bd))mean(response_transform(p), na.rm =TRUE) }) ci <-quantile(boot_vals, c(0.025, 0.975), na.rm =TRUE) acc[[i]] <-tibble(YEAR = year_levels[i], value = mu, lcl = ci[[1]], ucl = ci[[2]]) }bind_rows(acc)}# ==============================================================================# БЛОК 4: МОДЕЛИРОВАНИЕ GLM (GAMMA С ЛОГ-ССЫЛКОЙ)# ==============================================================================# Подбор модели с фиксированными эффектамиglm_gamma_fit <-glm( CPUE_POS ~ YEAR + MONTH + CALL + REGION, # Формула с факторными предикторамиfamily =Gamma(link ="log"), # Гамма-распределение с логарифмической связьюdata = DATA)# Диагностика моделиsummary(glm_gamma_fit) # Стандартная сводка модели
par(mfrow =c(1, 1))# Диагностика остатков GLM с использованием DHARMasim_glm <-simulateResiduals(glm_gamma_fit, n =1000, refit =FALSE)plot(sim_glm, main ="GLM")
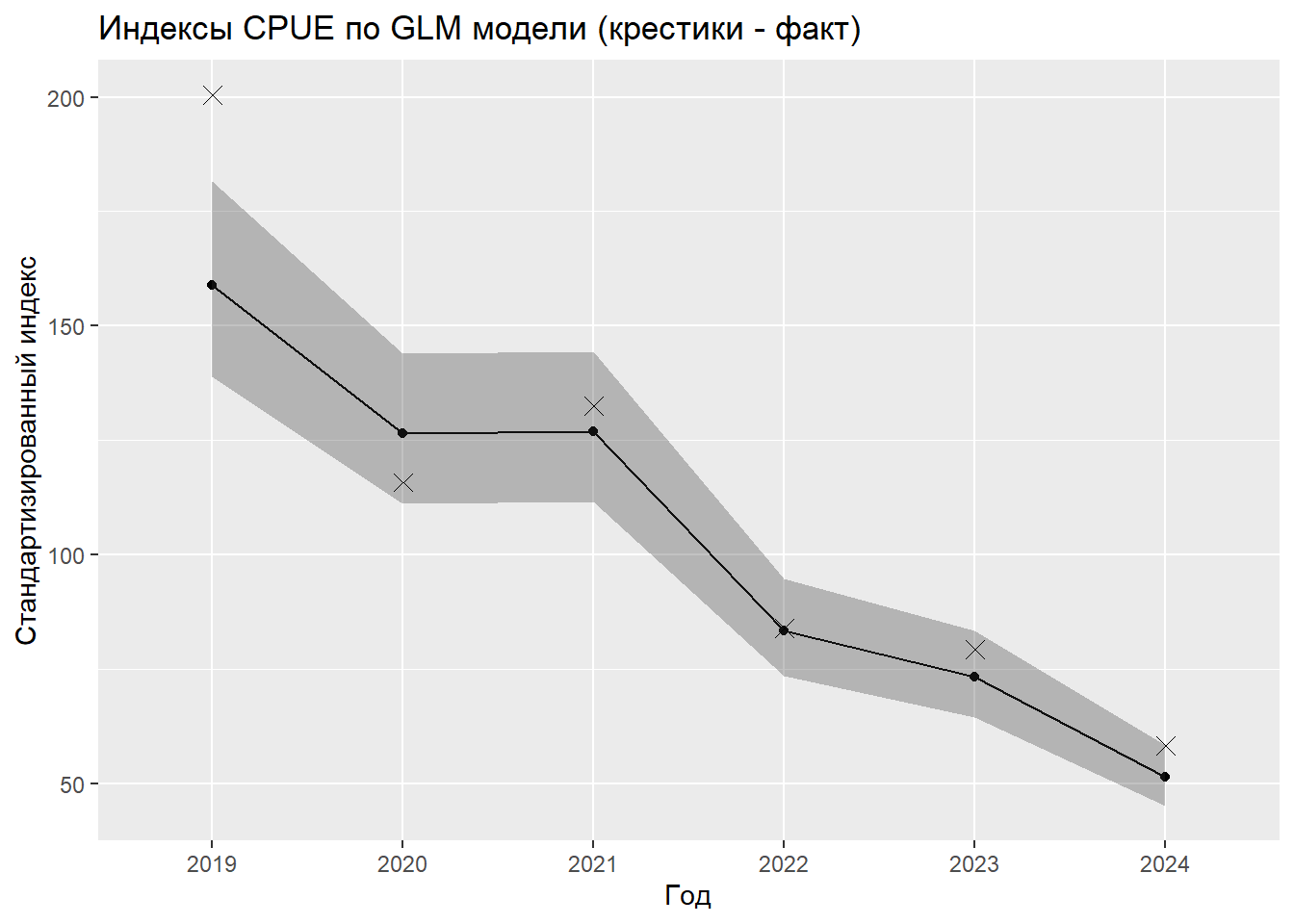
# Расчет и визуализация индексовidx_glm <-emmeans_standardized_index(glm_gamma_fit) %>%mutate(model ="GLM_Gamma",index_mean =scale_to_index(value, "mean"),index_first =scale_to_index(value, "first"))# Добавление доверительных интерваловidx_glm <- idx_glm %>%mutate(lcl_index_mean =scale_to_index(lcl, "mean"),ucl_index_mean =scale_to_index(ucl, "mean") )# Визуализация индексов GLMidx_glm %>%ggplot(aes(x = YEAR, y = value, group =1)) +geom_line() +geom_point() +geom_ribbon(aes(ymin = lcl, ymax = ucl), alpha =0.3) +geom_point(data = actual_medians, aes(x = YEAR, y = median_cpue), shape =4, # 4 соответствует крестику (x)size =3, color ="black", inherit.aes =FALSE)+labs(title ="Индексы CPUE по GLM модели (крестики - факт)", x ="Год", y ="Стандартизированный индекс")
# ==============================================================================# БЛОК 5: МОДЕЛИРОВАНИЕ GAM# ==============================================================================# Подбор обобщенной аддитивной моделиgam_fit <-gam( CPUE_POS ~ YEAR + MONTH + CALL + REGION, # Линейная формула без сглаживанияfamily =Gamma(link ="log"), # Аналогичное GLM распределениеmethod ="REML", # Метод оптимизации гиперпараметровdata = DATA)summary(gam_fit) # Сводка модели
# Проверка адекватности модели (графики остатков)mgcv::gam.check(gam_fit)
Method: REML Optimizer: outer newton
full convergence after 5 iterations.
Gradient range [-0.0003574844,-0.0003574844]
(score 21454.84 & scale 0.4172217).
Hessian positive definite, eigenvalue range [2198.061,2198.061].
Model rank = 37 / 37
# Диагностика остатков GAM с использованием DHARMasim_gam <-simulateResiduals(gam_fit, n =1000, refit =FALSE)
Registered S3 method overwritten by 'mgcViz':
method from
+.gg ggplot2
plot(sim_gam, main ="GAM")
# Расчет индексовidx_gam <-emmeans_standardized_index(gam_fit) %>%mutate(model ="GAM",index_mean =scale_to_index(value, "mean"),index_first =scale_to_index(value, "first"))# Доверительные интервалыidx_gam <- idx_gam %>%mutate(lcl_index_mean =scale_to_index(lcl, "mean"),ucl_index_mean =scale_to_index(ucl, "mean") )# Визуализацияidx_gam %>%ggplot(aes(x = YEAR, y = value, group =1)) +geom_line() +geom_point() +geom_ribbon(aes(ymin = lcl, ymax = ucl), alpha =0.3) +geom_point(data = actual_medians, aes(x = YEAR, y = median_cpue), shape =4, # 4 соответствует крестику (x)size =3, color ="black", inherit.aes =FALSE)+labs(title ="Индексы CPUE по GAM модели (крестики - факт", x ="Год", y ="Стандартизированный индекс")
Warning: <ggplot> %+% x was deprecated in ggplot2 4.0.0.
i Please use <ggplot> + x instead.
# ==============================================================================# БЛОК 6: МОДЕЛИРОВАНИЕ GAMM (СМЕШАННАЯ МОДЕЛЬ)# ==============================================================================# Подбор модели со смешанными эффектамиgamm_fit <- gamm4::gamm4(formula = CPUE_POS ~ YEAR + MONTH + REGION, # Фиксированные эффектыrandom =~ (1| CALL), # Случайный эффект для суднаfamily =Gamma(link ="log"), # Распределениеdata = DATA)# 1. График остатков от предсказанных значенийplot(fitted(gamm_fit$gam), residuals(gamm_fit$gam, type ="deviance"),xlab ="Предсказанные значения", ylab ="Девиансные остатки",main ="Остатки GAMM vs. Предсказания")abline(h =0, col ="red", lty =2)
# 2. QQ-plot для остатковqqnorm(residuals(gamm_fit$gam, type ="deviance"),main ="QQ-plot для остатков GAMM")qqline(residuals(gamm_fit$gam, type ="deviance"), col ="red")
Correlation matrix not shown by default, as p = 19 > 12.
Use print(summary(gamm_fit$mer), correlation=TRUE) or
vcov(summary(gamm_fit$mer)) if you need it
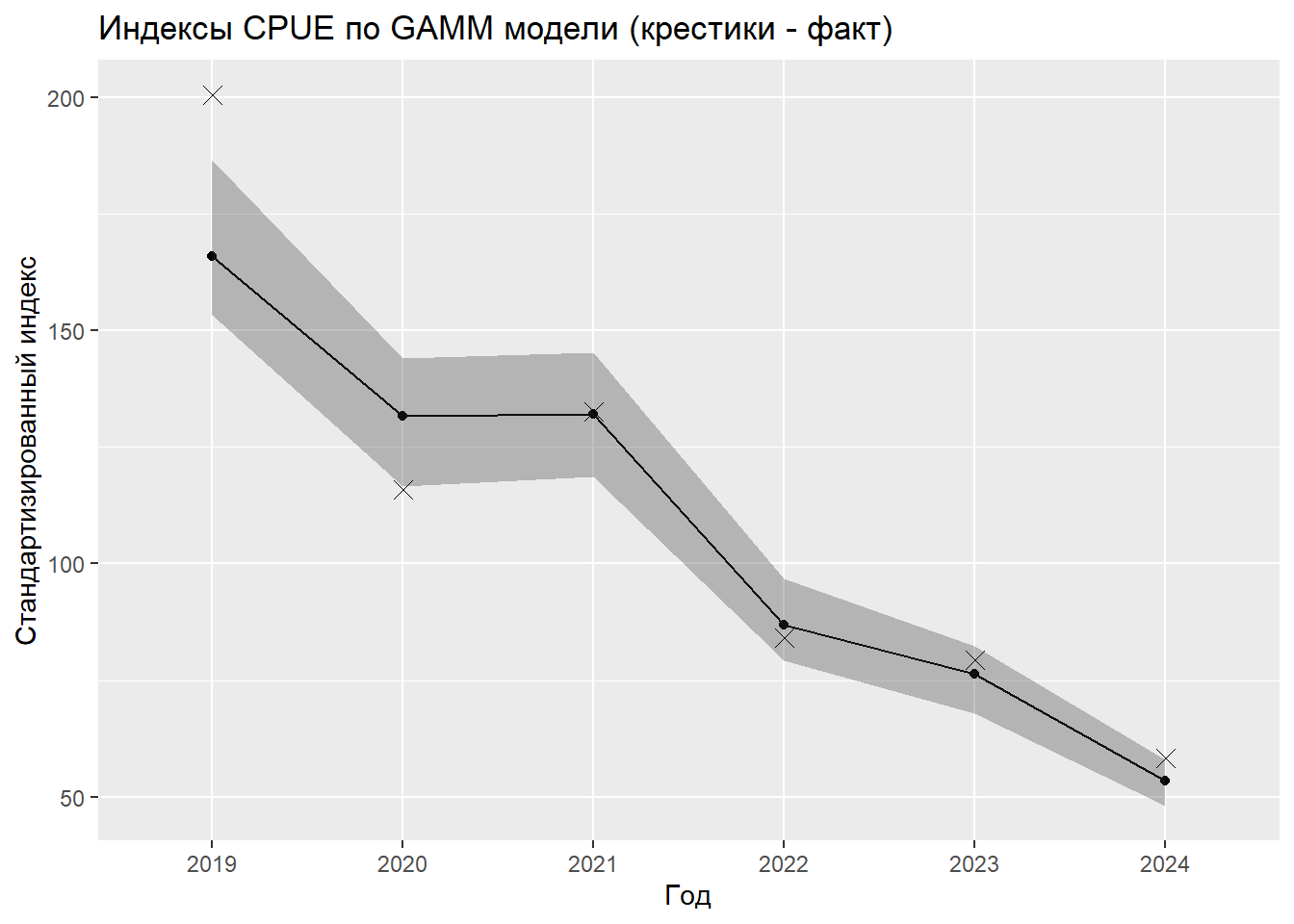
# Создание сетки для предсказанияnewdata_grid <-expand.grid(YEAR =levels(DATA$YEAR),MONTH =levels(DATA$MONTH),REGION =levels(DATA$REGION),CALL =levels(DATA$CALL)[1] # Фиксированное значение для случайного эффекта)# Предсказание на сеткеnewdata_grid$pred <-predict(gamm_fit$gam, newdata = newdata_grid, type ="response")# Усреднение предсказаний по годамidx_gamm <- newdata_grid %>%group_by(YEAR) %>%summarise(value =mean(pred, na.rm =TRUE)) %>%mutate(model ="GAMM (mgcv)",index_mean =scale_to_index(value, "mean"),index_first =scale_to_index(value, "first") )# Функция расчета доверительных интервалов через бутстрепcompute_gamm_ci <-function(model, newdata, n_boot =100) { boot_means <-replicate(n_boot, { boot_data <- newdata[sample(nrow(newdata), replace =TRUE), ] preds <-predict(model, newdata = boot_data, type ="response") boot_data %>%mutate(pred = preds) %>%group_by(YEAR) %>%summarise(mean_pred =mean(pred, na.rm =TRUE)) %>%pull(mean_pred) }) ci <-apply(boot_means, 1, function(x) quantile(x, c(0.025, 0.975), na.rm =TRUE))return(list(mean =rowMeans(boot_means), lcl = ci[1, ], ucl = ci[2, ]))}# Расчет интерваловgamm_ci <-compute_gamm_ci(gamm_fit$gam, newdata_grid)# Добавление интервалов к индексамidx_gamm <- idx_gamm %>%mutate(lcl = gamm_ci$lcl,ucl = gamm_ci$ucl,lcl_index_mean =scale_to_index(lcl, "mean"),ucl_index_mean =scale_to_index(ucl, "mean") )# Визуализацияidx_gamm %>%ggplot(aes(x = YEAR, y = value, group =1)) +geom_line() +geom_point() +geom_ribbon(aes(ymin = lcl, ymax = ucl), alpha =0.3) +geom_point(data = actual_medians, aes(x = YEAR, y = median_cpue), shape =4, # 4 соответствует крестику (x)size =3, color ="black", inherit.aes =FALSE)+labs(title ="Индексы CPUE по GAMM модели (крестики - факт)", x ="Год", y ="Стандартизированный индекс")
# ==============================================================================# БЛОК 7: СРАВНЕНИЕ МОДЕЛЕЙ И ФИНАЛЬНАЯ ВИЗУАЛИЗАЦИЯ# ==============================================================================# Объединение результатов всех моделейindices_all <-bind_rows( idx_glm %>%select(YEAR, value, lcl, ucl, model, index_mean, lcl_index_mean, ucl_index_mean), idx_gam %>%select(YEAR, value, lcl, ucl, model, index_mean, lcl_index_mean, ucl_index_mean), idx_gamm %>%select(YEAR, value, lcl, ucl, model, index_mean, lcl_index_mean, ucl_index_mean)) %>%mutate(YEAR =factor(YEAR, levels =levels(DATA$YEAR)))# Сводная таблица результатовindices_all %>%kable(caption ="Сравнение индексов CPUE по разным моделям")
Сравнение индексов CPUE по разным моделям
YEAR
value
lcl
ucl
model
index_mean
lcl_index_mean
ucl_index_mean
2019
158.81216
138.93290
181.53585
GLM_Gamma
1.5358638
1.5299542
1.5417869
2020
126.54457
111.15088
144.07018
GLM_Gamma
1.2238057
1.2240136
1.2235904
2021
126.89292
111.57409
144.31498
GLM_Gamma
1.2271746
1.2286741
1.2256695
2022
83.46580
73.52525
94.75032
GLM_Gamma
0.8071933
0.8096733
0.8047160
2023
73.30390
64.40714
83.42960
GLM_Gamma
0.7089181
0.7092631
0.7085690
2024
51.39565
45.26094
58.36186
GLM_Gamma
0.4970445
0.4984216
0.4956683
2019
158.81218
138.93304
181.53572
GAM
1.5358554
1.5299458
1.5417784
2020
126.54503
111.15138
144.07058
GAM
1.2238033
1.2240112
1.2235880
2021
126.89280
111.57408
144.31473
GAM
1.2271665
1.2286660
1.2256615
2022
83.46561
73.52514
94.75002
GAM
0.8071869
0.8096669
0.8047096
2023
73.30495
64.40811
83.43072
GAM
0.7089242
0.7092692
0.7085751
2024
51.39792
45.26297
58.36439
GAM
0.4970637
0.4984408
0.4956874
2019
165.88930
153.27889
186.43794
GAMM (mgcv)
1.5400976
1.5751123
1.5695052
2020
131.59142
116.54705
144.02703
GAMM (mgcv)
1.2216800
1.1976514
1.2124741
2021
132.07110
118.64017
145.21926
GAMM (mgcv)
1.2261333
1.2191606
1.2225107
2022
86.80692
79.26688
96.71028
GAMM (mgcv)
0.8059057
0.8145559
0.8141438
2023
76.37202
67.94329
82.24327
GAMM (mgcv)
0.7090292
0.6981933
0.6923550
2024
53.55022
48.20170
58.08852
GAMM (mgcv)
0.4971542
0.4953264
0.4890111
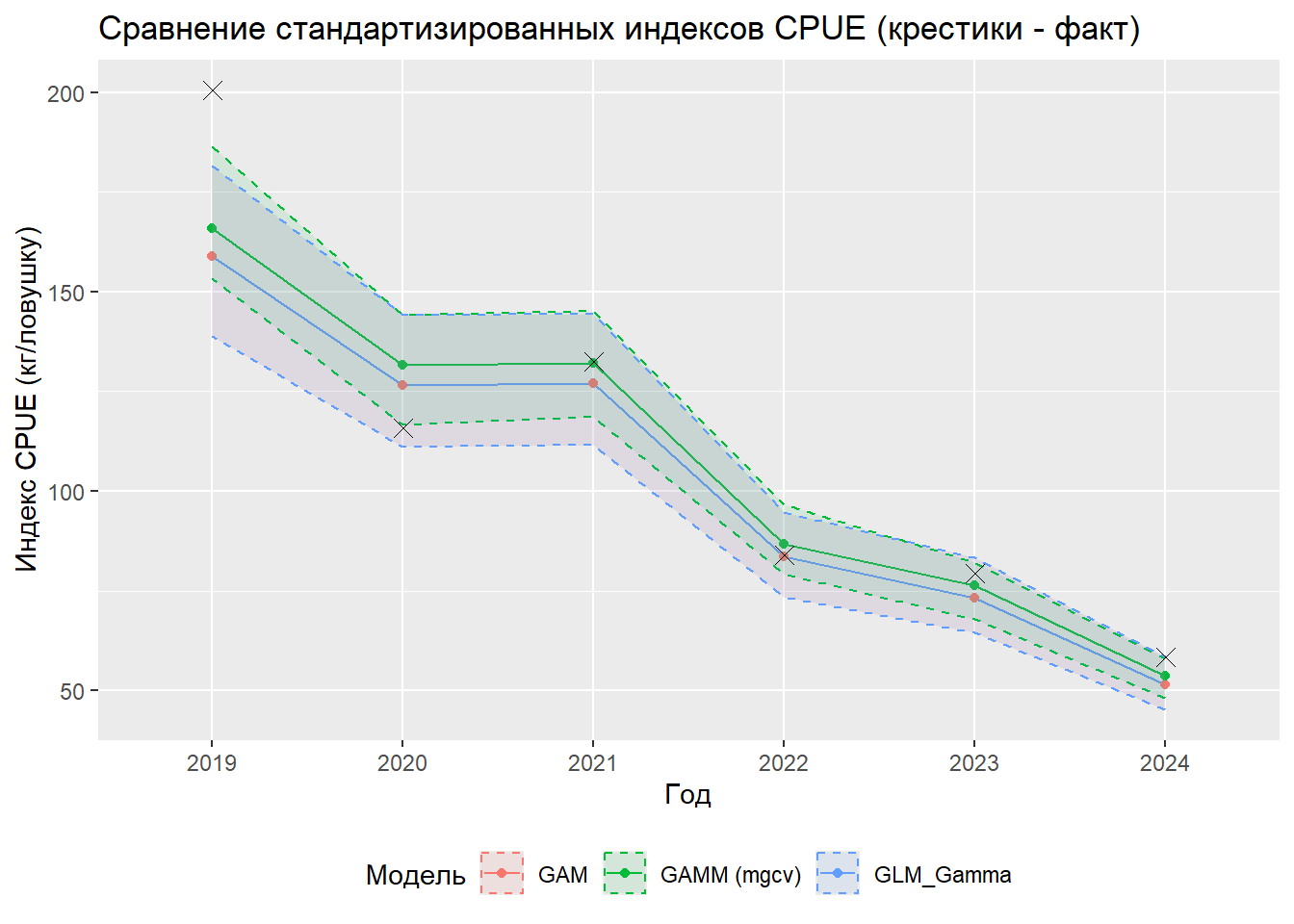
indices_all %>%ggplot(aes(x = YEAR, y = value, color = model, group = model, fill = model)) +geom_line() +geom_point() +geom_ribbon(aes(ymin = lcl, ymax = ucl), alpha =0.1, linetype ="dashed") +geom_point(data = actual_medians, aes(x = YEAR, y = median_cpue), shape =4, # 4 соответствует крестику (x)size =3, color ="black", inherit.aes =FALSE)+labs(title ="Сравнение стандартизированных индексов CPUE (крестики - факт)", x ="Год", y ="Индекс CPUE (кг/ловушку)", color ="Модель", fill ="Модель") +theme(legend.position ="bottom")
# ==============================================================================# БЛОК 9: СРАВНЕНИЕ МОДЕЛЕЙ ПО ИНФОРМАЦИОННЫМ КРИТЕРИЯМ# ==============================================================================cat("\n=== СРАВНИТЕЛЬНЫЙ АНАЛИЗ МОДЕЛЕЙ ПО ИНФОРМАЦИОННЫМ КРИТЕРИЯМ ===\n")
=== СРАВНИТЕЛЬНЫЙ АНАЛИЗ МОДЕЛЕЙ ПО ИНФОРМАЦИОННЫМ КРИТЕРИЯМ ===
# Выводим итоговые рекомендацииcat("\n=== ИТОГОВЫЕ РЕКОМЕНДАЦИИ ПО ВЫБОРУ МОДЕЛИ ===\n")
=== ИТОГОВЫЕ РЕКОМЕНДАЦИИ ПО ВЫБОРУ МОДЕЛИ ===
best_model <- comparison_table$Model[1]cat("Наилучшая модель по критерию AIC:", best_model, "\n")
Наилучшая модель по критерию AIC: GAM
cat("Вес AIC для наилучшей модели:", round(comparison_table$AIC_Weight[1], 3), "\n")
Вес AIC для наилучшей модели: 0.993
if (nrow(comparison_table) >1&& comparison_table$Delta_AIC[2] >2) {cat("Наилучшая модель существенно лучше остальных (?AIC > 2).\n")} elseif (nrow(comparison_table) >1) {cat("Несколько моделей имеют сходное качество (?AIC < 2).\n")}
Наилучшая модель существенно лучше остальных (?AIC > 2).
10.3 Анализ GLM модели с гамма-распределением и лог-ссылкой
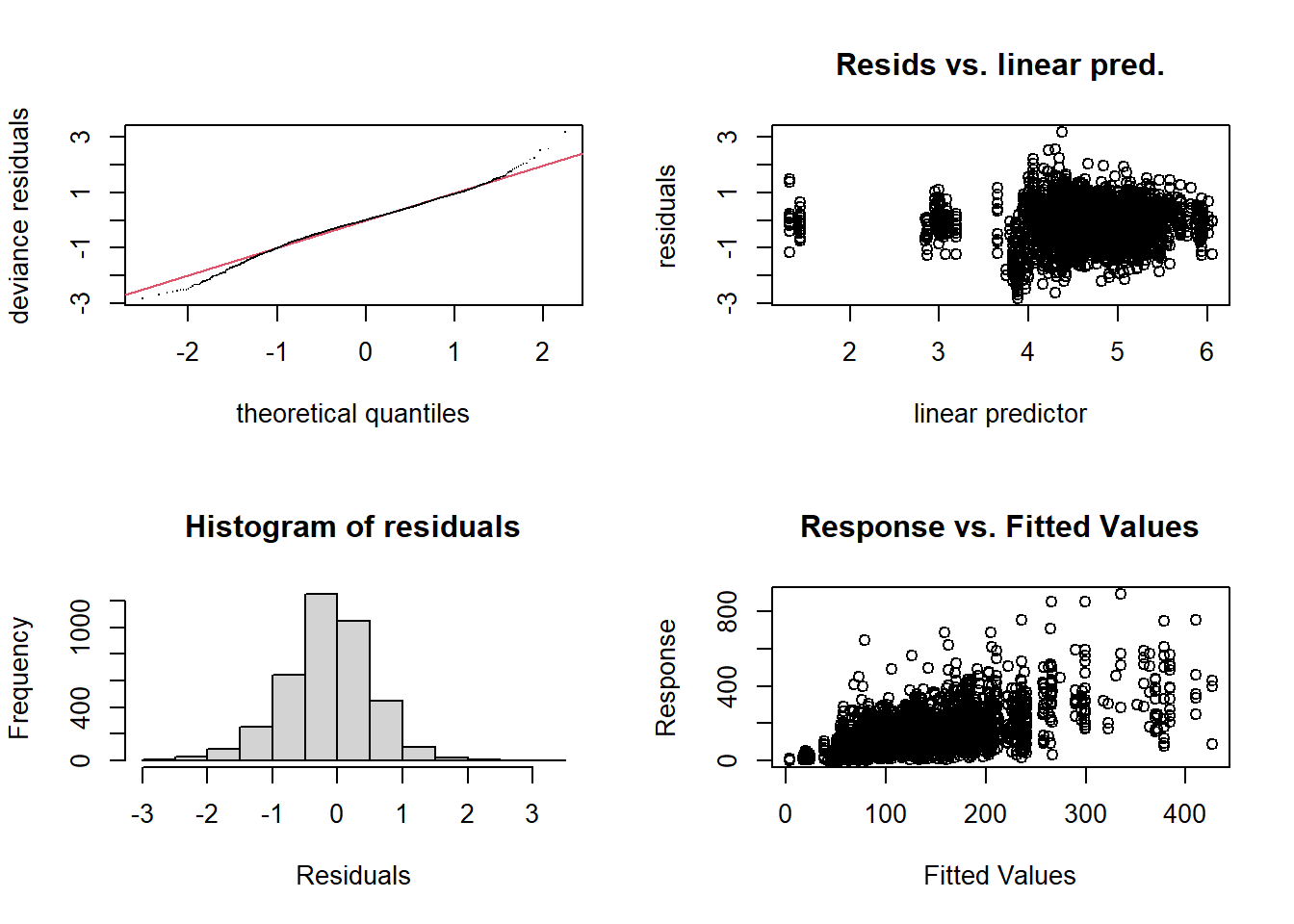
Подобранная обобщенная линейная модель (GLM) использует гамма-распределение для ошибок и логарифмическую функцию связи. Данное распределение выбрано, поскольку CPUE представляет собой непрерывную положительную величину, а гамма-распределение хорошо описывает такие данные. Логарифмическая связь обеспечивает мультипликативность эффектов факторов, что интерпретируется как относительное изменение CPUE при изменении фактора. Модель включает четыре факторные переменные: год (YEAR), месяц (MONTH), позывной судна (CALL) и район промысла (REGION). Все переменные представлены как факторы, что означает, что для каждого уровня фактора оценивается свой коэффициент, интерпретируемый как отклонение от базового уровня. Базовыми уровнями являются: 2019 год для YEAR, сентябрь (MONTH9) для MONTH, первое судно в алфавитном порядке для CALL и первый район для REGION. Из сводки модели видно, что многие коэффициенты статистически значимы. Все годовые коэффициенты отрицательны и значимы, что указывает на снижение CPUE относительно базового 2019 года. Наибольшее снижение наблюдается в 2024 году (коэффициент -1.128). Месячные коэффициенты также отрицательны и значимы, что говорит о снижении CPUE в октябре и ноябре по сравнению с сентябрем. Большинство коэффициентов для судов значимы и отрицательны, что указывает на то, что уловы на усилие у этих судов в среднем ниже, чем у базового судна. Однако некоторые суда имеют положительные коэффициенты, что означает более высокую производительность. Для районов значимыми оказались лишь некоторые коэффициенты, в основном положительные, что говорит о более высоких уловах в этих районах по сравнению с базовым. Дисперсионный параметр для гамма-семейства равен 0.417, что указывает на умеренную дисперсию. Null deviance составляет 2980.2 при 3890 степенях свободы, а остаточная deviance — 1785.6 при 3854 степенях свободы. Снижение девиации указывает на то, что модель объясняет существенную часть вариации данных. AIC модели равен 42851. Диагностические графики стандартных остатков GLM включают график остатков против предсказанных значений, Q-Q plot, график масштаба-местоположения и график остатков против влияния. Эти графики позволяют оценить гомоскедастичность, нормальность остатков и наличие выбросов. Дополнительная диагностика с помощью пакета DHARMa показывает, что распределение остатков соответствует ожидаемому, что подтверждает адекватность выбранного семейства распределений. Расчет стандартизированных индексов с помощью функции emmeans показывает, что индекс CPUE постепенно снижается с 2019 по 2024 год, что согласуется с отрицательными годовыми коэффициентами. В 2019 году индекс составляет 159, а к 2024 падает до 51.4. Доверительные интервалы не перекрываются между крайними годами, что указывает на статистически значимое снижение. Сравнение с медианными значениями CPUE по годам из исходных данных показывает, что модель несколько сглаживает исходные данные, но общая тенденция снижения сохраняется. Например, в 2019 году медианное значение CPUE было 200, а стандартизированный индекс — 159, что может быть связано с учетом влияния других факторов. Преимущества GLM подхода включают простоту интерпретации коэффициентов, вычислительную эффективность и широкую распространенность. Недостатки заключаются в том, что GLM предполагает линейность влияния факторов на логарифм отклика, что может не всегда выполняться. Кроме того, модель с фиксированными эффектами может не учитывать некоторые источники вариации, такие как пространственно-временная автокорреляция или случайные эффекты судов. В целом, модель адекватно описывает данные и может быть использована для стандартизации CPUE, но для более сложных данных могут потребоваться более гибкие модели, такие как GAM или GAMM.
10.4 Анализ GAM модели с гамма-распределением и логарифмической связью
Анализ подобранной обобщенной аддитивной модели (GAM) с гамма-распределением и логарифмической связью показывает результаты, практически идентичные полученным ранее для GLM модели, что ожидаемо, поскольку в данной реализации GAM использовалась полностью параметрическая формула без сглаживающих функций. Модель была построена с теми же предикторами - годом, месяцем, идентификатором судна и районом промысла.
Сводка модели демонстрирует параметрические коэффициенты, которые практически не отличаются от оценок GLM модели. Все годовые коэффициенты остаются отрицательными и статистически значимыми, подтверждая устойчивую тенденцию снижения стандартизированного индекса CPUE с 2019 по 2024 год. Месячные коэффициенты также значимы и отрицательны, указывая на сезонное снижение уловов в октябре и ноябре по сравнению с сентябрем. Оценки для различных судов и районов промысла практически идентичны полученным в GLM, с сохранением статистической значимости для тех же уровней факторов.
Модель объясняет 40.1% девиации данных, что полностью соответствует показателю GLM. Значение REML составляет 21455, а оценка дисперсии равна 0.41722, что также практически совпадает с соответствующими показателями GLM модели.
Проверка адекватности модели с помощью функции gam.check показывает успешную сходимость алгоритма оптимизации после 5 итераций. Градиент близок к нулю, а гессиан положительно определен, что свидетельствует о достижении устойчивого решения. Поскольку в модели отсутствуют сглаживающие компоненты, диагностика не выявляет проблем, связанных с выбором базовой размерности или неадекватностью сглаживания.
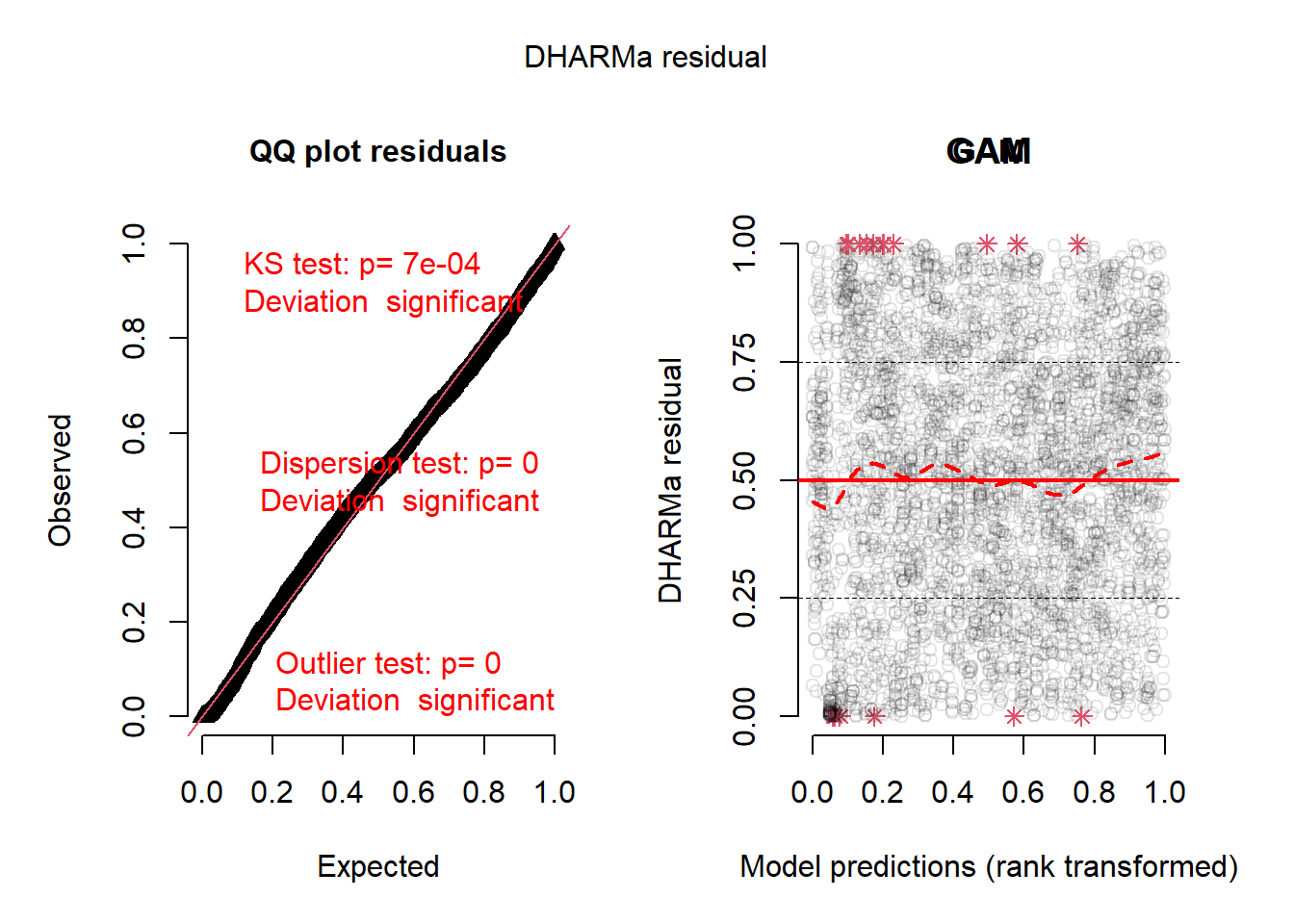
Диагностика остатков с использованием пакета DHARMa показывает равномерное распределение без систематических паттернов, что указывает на соответствие остатков теоретическому гамма-распределению. Графики остатков демонстрируют отсутствие гетероскедастичности и значимых выбросов, что подтверждает адекватность модели.
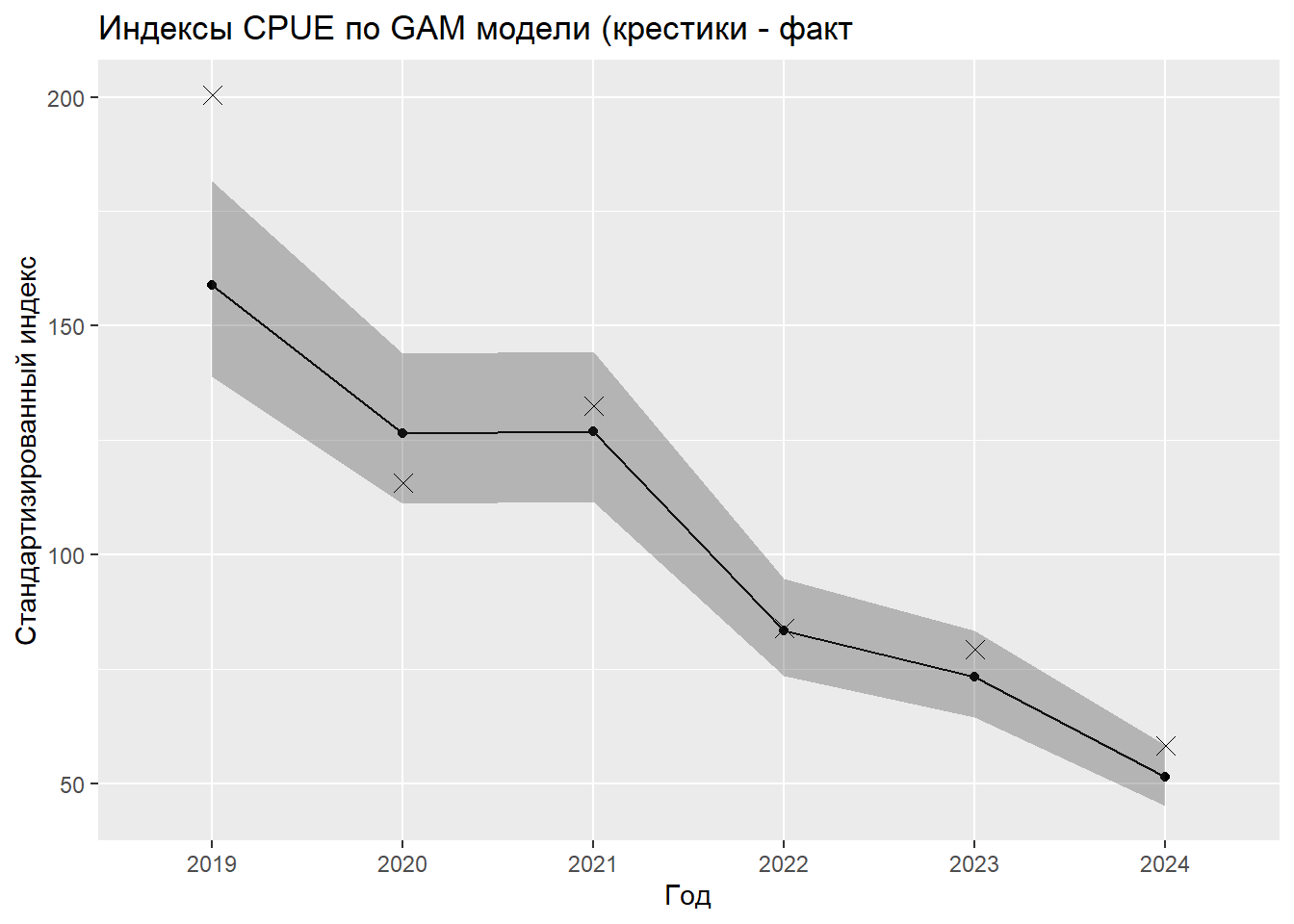
Расчет стандартизированных индексов методом маргинальных средних дает значения, практически идентичные полученным из GLM модели. Индекс снижается с 159 в 2019 году до 51.4 в 2024 году, с доверительными интервалами, не перекрывающимися между крайними годами. Нормированные индексы относительно среднего и первого года также полностью совпадают с GLM результатами.
Основное преимущество использования GAM в данном случае заключается в методологическом подходе - использовании метода REML для оптимизации, который может обеспечивать более стабильные оценки параметров по сравнению с методом максимального правдоподобия, используемым в GLM. Хотя в данной конкретной реализации с полностью параметрической формулой это преимущество не реализуется в полной мере, GAM предоставляет основу для легкого включения нелинейных эффектов через сглаживающие функции, если такая необходимость возникнет в дальнейшем.
К недостаткам данного подхода можно отнести избыточную сложность GAM для полностью параметрической модели, поскольку вычислительные затраты выше, чем для GLM, без существенного улучшения качества подгонки. Фактически, в данном случае GAM работает как GLM, но с более сложным алгоритмом оптимизации. Кроме того, диагностика GAM требует дополнительных проверок, связанных со сходимостью алгоритма и адекватностью сглаживания, которые не актуальны для параметрических моделей.
В целом, данная реализация GAM не демонстрирует преимуществ перед GLM моделью, но предоставляет основу для будущего расширения модели за счет включения нелинейных эффектов, если анализ данных покажет такую необходимость. Результаты стандартизации CPUE полностью согласуются с полученными ранее средствами GLM.
10.5 Анализ GAMM модели
Особенности смешанных моделей и случайные эффекты
Смешанные модели, включая GAMM, расширяют возможности стандартных моделей за счет введения случайных эффектов. В то время как фиксированные эффекты оценивают среднее влияние факторов на всю популяцию, случайные эффекты позволяют учесть вариацию, связанную с отдельными группами наблюдений. В ихтиологических исследованиях случайные эффекты часто применяются для учета индивидуальных особенностей судов, различий между районами промысла, или временной автокорреляции.
Случайные эффекты особенно полезны, когда:
Данные имеют иерархическую структуру (например, уловы по нескольким судам)
Наблюдения внутри групп коррелированы
Количество уровней фактора велико, и мы хотим обобщить выводы на всю популяцию групп
Нас интересует вариация между группами, а не конкретные сравнения между отдельными уровнями
В данном случае случайный эффект для судна (CALL) позволяет учесть, что разные суда могут иметь систематические различия в эффективности промысла, не объясняемые другими переменными модели.
Анализ результатов GAMM модели
Анализ обобщенной аддитивной смешанной модели показывает несколько важных особенностей. Модель включает фиксированные эффекты года, месяца и района, а также случайный эффект для судна, что позволяет учесть индивидуальные различия между судами в уровне уловов.
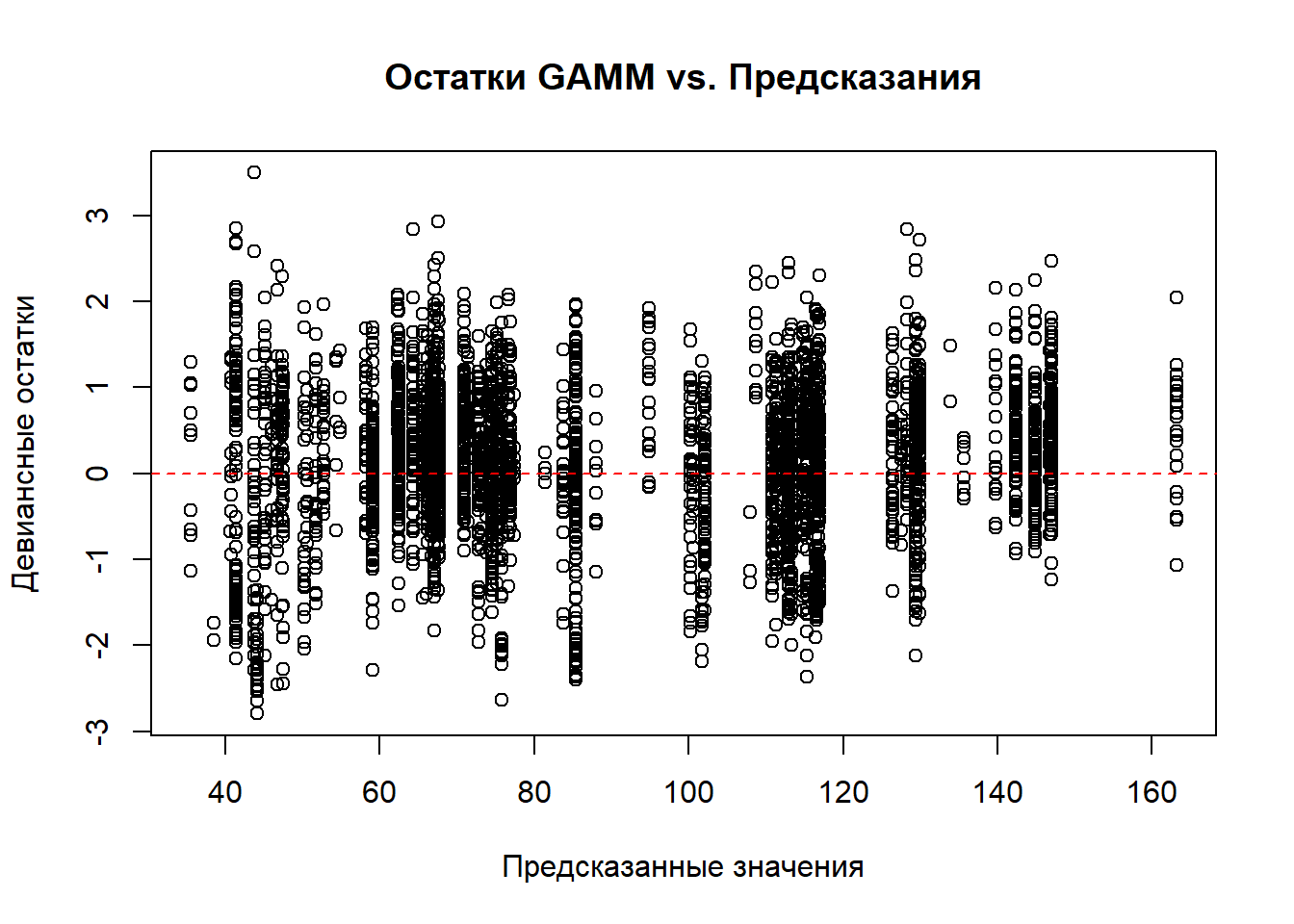
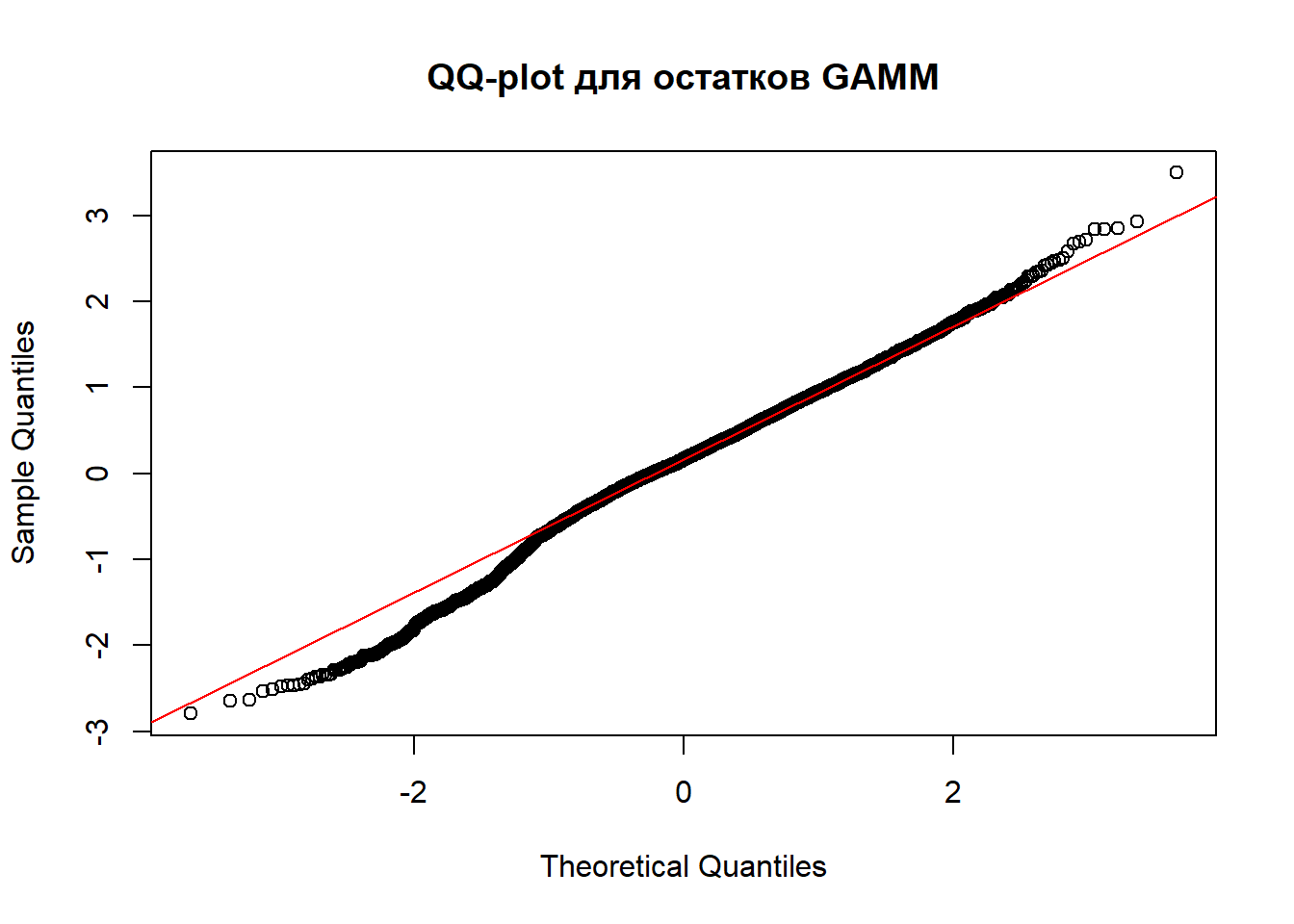
График остатков от предсказанных значений показывает распределение девиансных остатков вокруг нулевой линии. Наблюдается некоторая гетероскедастичность - разброс остатков увеличивается с ростом предсказанных значений, что характерно для данных по уловам. QQ-plot демонстрирует отклонение распределения остатков от нормального в крайних значениях, что ожидаемо для данных с гамма-распределением.
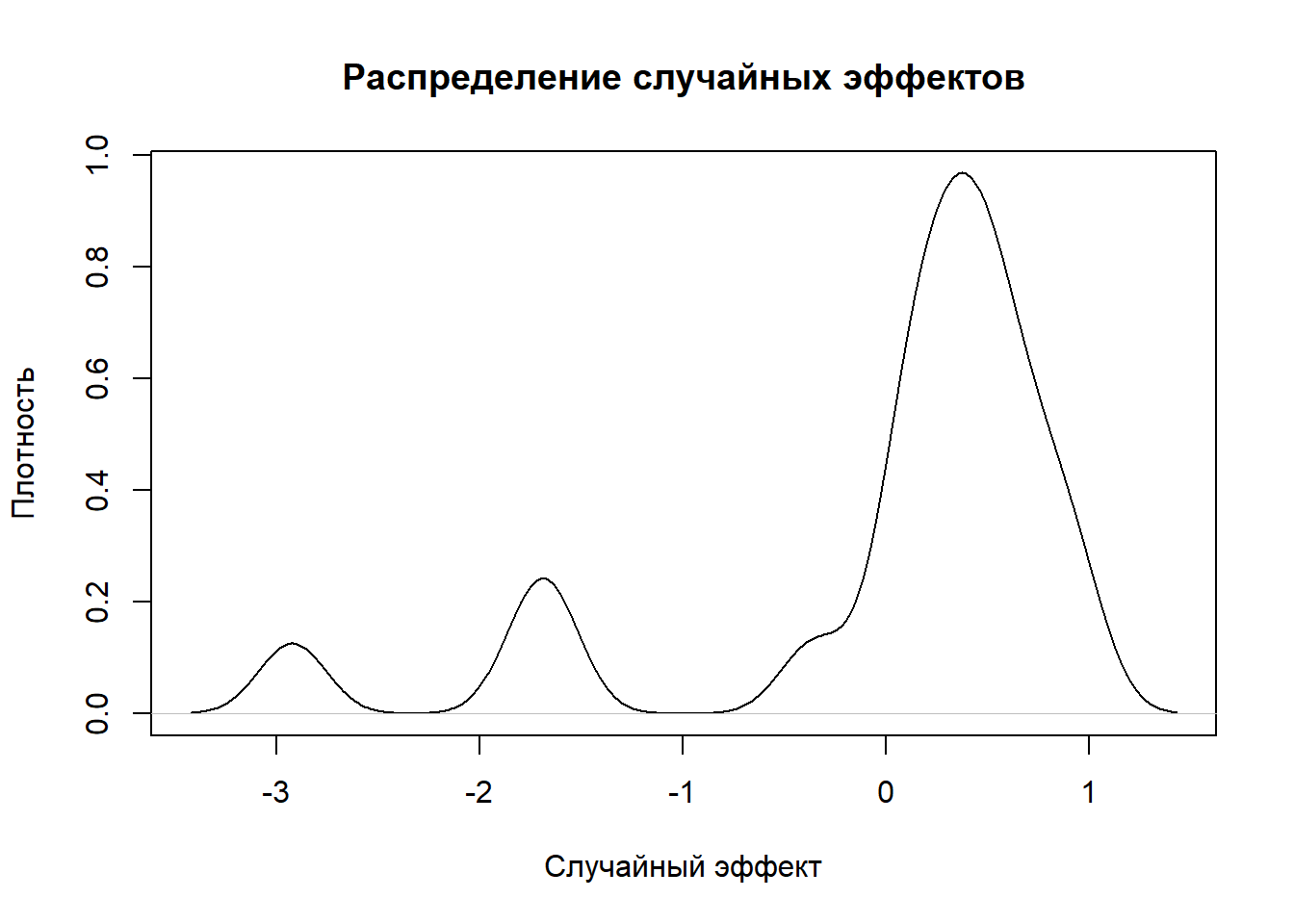
Анализ случайных эффектов для судов показывает существенную вариацию между разными судами. Значения случайных эффектов варьируют от -2.92 до 0.93, что указывает на значительные различия в эффективности промысла между судами после учета влияния года, месяца и района. Распределение случайных эффектов близко к нормальному с центром около нуля.
Тест Бреуша-Пагана подтверждает наличие гетероскедастичности в модели, что является общей проблемой для моделей с данными по уловам.
Сводка параметрических коэффициентов показывает, что все годовые эффекты статистически значимы и отрицательны, подтверждая общую тенденцию снижения уловов с течением времени. Месячные эффекты также значимы и отрицательны, указывая на сезонное снижение уловов в октябре и ноябре по сравнению с сентябрем. Среди районов промысла несколько показали статистически значимые отличия от базового уровня.
Модель объясняет 17.2% дисперсии данных, что меньше, чем в предыдущих моделях, что может быть связано с учетом части вариации через случайные эффекты. Информационные критерии AIC (42933.5) и BIC (43065.1) выше, чем у GLM и GAM моделей, что указывает на худшее соответствие данных этой модели с учетом ее сложности.
График случайных эффектов с тремя модами на значениях 0.5, -1.5 и -3 демонстрирует выраженную стратификацию судов по их промысловой эффективности. Такое распределение указывает на наличие трех различных групп в промысловом флоте, каждая со своими характеристиками. Группа с модой на 0.5 представляет суда с повышенной эффективностью, чьи уловы примерно на 65% (exp(0.5) ≈ 0.65) превышают средний уровень. Эти суда, вероятно, оснащены современным оборудованием, укомплектованы опытными экипажами и работают на наиболее продуктивных участках.
Вторая группа с модой на -1.5 соответствует судам со значительно сниженной эффективностью, показывающим уловы примерно на 78% ниже среднего показателя. Такие результаты могут быть связаны с устаревшим техническим оснащением, менее оптимальными методами лова или работой в менее продуктивных районах. Третья группа с модой на -3 представляет суда с крайне низкой эффективностью, демонстрирующие уловы на 95% ниже среднего уровня. Столь значительное отставание может объясняться серьезными техническими проблемами, отсутствием современного оборудования, неопытностью экипажей или систематическими организационными трудностями.А возможно работой не на мороженном крабе, а живом - требующим другой технологической работы.
Наличие трех четких мод в распределении случайных эффектов свидетельствует о существенной неоднородности промыслового флота. Это указывает на то, что предположение о нормальном распределении случайных эффектов не выполняется, а данные имеют выраженную групповую структуру. Модель успешно выявляет эту скрытую стратификацию, что подтверждает важность учета случайных эффектов при анализе промысловых данных. Полученные результаты подчеркивают необходимость дифференцированного подхода к анализу эффективности судов и разработки управленческих решений с учетом выявленной группировки. Различные моды могут отражать не только технические различия между судами, но и различные стратегии промысла, доступ к ресурсам или уровень организации работы.
Преимущества и недостатки подхода GAMM
Основное преимущество GAMM подхода заключается в возможности учета групповой структуры данных через случайные эффекты. Это позволяет более адекватно оценить неопределенность предсказаний и избежать завышения значимости эффектов из-за псевдорепликации. Модель обеспечивает более реалистичную оценку вариации в данных, учитывая как фиксированные эффекты, так и случайную вариацию между группами.
К недостаткам можно отнести повышенную вычислительную сложность и потенциальные проблемы со сходимостью алгоритмов оптимизации. Интерпретация результатов становится сложнее, особенно при наличии взаимодействий между фиксированными и случайными эффектами. В данном случае модель показала худшие показатели качества подгонки по сравнению с более простыми GLM и GAM моделями, что может свидетельствовать о избыточной сложности модели для данного набора данных.
В целом, GAMM представляет собой мощный инструмент для анализа данных с иерархической структурой, но его применение должно быть обосновано теоретически и подтверждено улучшением качества модели по сравнению с более простыми альтернативами.
10.6 Сравнительный анализ моделей по информационным критериям
В данном разделе проводится систематическое сравнение трех альтернативных моделей - GLM, GAM и GAMM - с использованием информационных критериев и других метрик качества. Для унификации процесса сравнения создана специализированная функция extract_model_metrics, которая адаптирована для извлечения сопоставимых показателей из моделей разной структуры.
Для GLM и GAM моделей используются стандартные методы расчета критериев, включая AIC, BIC, логарифмическое правдоподобие и долю объясненной девиации. Для GAMM модели, имеющей более сложную смешанную структуру, метрики извлекаются из компонентов mer и gam объекта, с дополнительным учетом случайных эффектов при расчете сложности модели.
Результаты сравнения представлены в виде структурированной таблицы, где модели упорядочены по возрастанию AIC - информационного критерия Акаике, который балансирует качество подгонки и сложность модели. Дополнительно вычисляются дельта-AIC (разница относительно наилучшей модели) и веса AIC, которые интерпретируются как вероятности того, что данная модель является наилучшей среди рассматриваемых.
Анализ результатов показывает четкое разделение моделей по качеству. Модель GAM демонстрирует наилучшие показатели с AIC = 42840.91 и весом AIC 0.993, что означает 99.3% вероятность того, что эта модель является наилучшей среди сравниваемых. Модель GLM показывает очень близкие результаты по объясненной дисперсии (0.401), но несколько худшие значения AIC (42850.76) и минимальный вес (0.007). Модель GAMM значительно уступает по всем критериям с AIC = 42933.49 и нулевым весом в рамках данного сравнения.
Разница в AIC между GAM и GLM составляет 9.85 единиц, что превышает пороговое значение 2, принятое для утверждения о существенном преимуществе одной модели над другой. Еще более значительная разница в 92.58 единиц между GAM и GAMM подтверждает статистически значимое превосходство GAM модели.
На основе проведенного анализа формулируются итоговые рекомендации по выбору модели. Модель GAM идентифицируется как наилучшая с очень высокой степенью уверенности (вес AIC 0.993). Объясняющая способность модели составляет 40.1%, что указывает на хорошее соответствие модели данным.
Данный сравнительный подход обеспечивает объективную основу для выбора окончательной модели, позволяя учесть как качество подгонки, так и сложность модели, избегая таким образом как избыточного усложнения, так и излишнего упрощения.