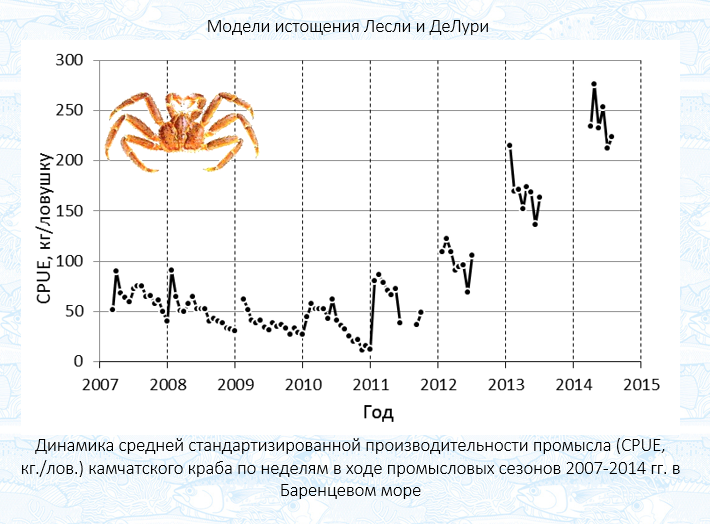
Если вы когда-нибудь задумывались, как оценить, сколько всего крабов было в море до того, как начался промысел, то сегодняшнее занятие — для вас. Мы погрузимся в причудливый и лапидарный мир моделей истощения — пожалуй, одних из самых интуитивно понятных и в то же время самых капризных инструментов в арсенале рыбохозяйственной науки. Модели Лесли и ДеЛури, рожденные в середине прошлого века, предлагают элегантное и на первый взгляд простое решение: если мы видим, что с каждой проведенной на промысле минутой улов на усилие (пресловутый CPUE или производительность промысла) неумолимо падает, то, значит, мы последовательно вылавливаем некую исходную популяцию. Проведя линию через эти точки снижения, мы можем экстраполировать её назад, к моменту начала лова, и получить оценку начальной численности. В теории всё звучит прекрасно и логично. Лесли предлагает смотреть на зависимость CPUE от кумулятивного (суммарного) усилия, а Делури — логарифма CPUE от кумулятивного улова; разница в подходе, но философия одна: зафиксировать сам факт истощения и дать ему количественную оценку.
Проблема, однако, в том, что эти модели требуют идеальных, почти лабораторных условий, которые в реальном мире встречаются реже, чем искренний ответ пахаря голубой нивы на вопрос «Много ли поймал?». Нужно, чтобы один и тот же флот, с одной и той же эффективностью, одним и тем же орудием лова работал на ограниченной акватории, изымая запас без всякой притравки извне. Нужно, чтобы за это время была устойчивая погода, не изменилась температура воды, не подошла новая агрегация краба с соседнего участка. Нужно, чтобы крабы вели себя как хорошие статистические единицы — предсказумо и пассивно. В общем, нужно чудо.
И такое чудо иногда случается. Данные, с которыми мы будем работать сегодня — тот самый редкий и почти уникальный случай. С 2007 по 2018 (рисунок немного устарел) год один промысловый флот вёл лов камчатского краба на относительно локальном участке Баренцева моря по одной и той же схеме. И в каждый промысловый сезон, длиной в два-три месяца, кривая CPUE послушно и плавно ползла вниз, как будто краб специально подгадал и выстроился в очередь по приказу статистика. Это был идеальный, просто учебный сюжет, подарок для любого аналитика. Увы, всему хорошему приходит конец. С приходом новых игроков на промысел идиллическая картина разрушилась. Пространственная структура запаса перемешалась, усилие стало прикладываться довольно неравномерно, и та самая чистая сигнатура истощения, которую нам так нравилась, пропала, растворившись в шуме конкуренции и возросшего пресса. Теперь эти данные — скорее исключение, музейный экспонат, наглядно демонстрирующий, как должны выглядеть модели истощения в идеале, и почему мы не можем использовать их так часто, как хотелось бы. Давайте же воспользуемся этой уникальной возможностью и разберёмся, как работают эти капризные, но прекрасные в своей простоте методы.
# ========================================================================================================================# ПРАКТИЧЕСКОЕ ЗАНЯТИЕ: МОДЕЛИ ИСТОЩЕНИЯ ЛЕСЛИ И ДЕЛУРИ# Курс: "Оценка водных биоресурсов в среде R (для начинающих)"# Автор: Баканев С. В. Дата: 03.09.2025# ========================================================================================================================# 1. ПОДГОТОВКА СРЕДЫ ====================================================================================================# Установка и подключение необходимых пакетов# FSA - Fisheries Stock Analysis для моделей истощения# ggplot2 - для продвинутой визуализации# dplyr - для манипуляций с данными# tidyverse - современный подход к обработке данныхif (!require("FSA")) install.packages("FSA")
Загрузка требуемого пакета: FSA
## FSA v0.10.0. See citation('FSA') if used in publication.
## Run fishR() for related website and fishR('IFAR') for related book.
if (!require("ggplot2")) install.packages("ggplot2")
Загрузка требуемого пакета: ggplot2
if (!require("dplyr")) install.packages("dplyr")
Загрузка требуемого пакета: dplyr
Присоединяю пакет: 'dplyr'
Следующие объекты скрыты от 'package:stats':
filter, lag
Следующие объекты скрыты от 'package:base':
intersect, setdiff, setequal, union
if (!require("broom")) install.packages("broom")
Загрузка требуемого пакета: broom
if (!require("tidyverse")) install.packages("tidyverse")
Загрузка требуемого пакета: tidyverse
-- Attaching core tidyverse packages ------------------------ tidyverse 2.0.0 --
v forcats 1.0.0 v stringr 1.5.2
v lubridate 1.9.4 v tibble 3.2.1
v purrr 1.0.4 v tidyr 1.3.1
v readr 2.1.5
-- Conflicts ------------------------------------------ tidyverse_conflicts() --
x dplyr::filter() masks stats::filter()
x dplyr::lag() masks stats::lag()
i Use the conflicted package (<http://conflicted.r-lib.org/>) to force all conflicts to become errors
library(FSA)library(ggplot2)library(dplyr)library(broom)library(tidyverse)# Установка рабочей директории - укажите путь к папке с даннымиsetwd("C:/DEPLETION/")# 2. ЗАГРУЗКА И ПЕРВИЧНЫЙ АНАЛИЗ ДАННЫХ ==================================================================================# Чтение данных из CSV-файла# header = TRUE - первая строка содержит названия колонок# sep = ";" - разделитель точка с запятой (common для European CSV)LESLIDATA <-read.csv("DATAdep.csv", header =TRUE, sep =";")# Проверка структуры данных# Функция str() показывает:# - тип объекта (data.frame)# - количество наблюдений и переменных# - тип каждой переменнойstr(LESLIDATA)
'data.frame': 131 obs. of 5 variables:
$ CPUE : num 51 90 68 64 60 72 75 75 65 65 ...
$ CATCH : num 262 826 596 545 564 ...
$ YEAR : int 2007 2007 2007 2007 2007 2007 2007 2007 2007 2007 ...
$ WEEK : int 37 38 39 40 41 42 43 44 45 46 ...
$ EFFORT: num 5.14 9.18 8.77 8.52 9.39 ...
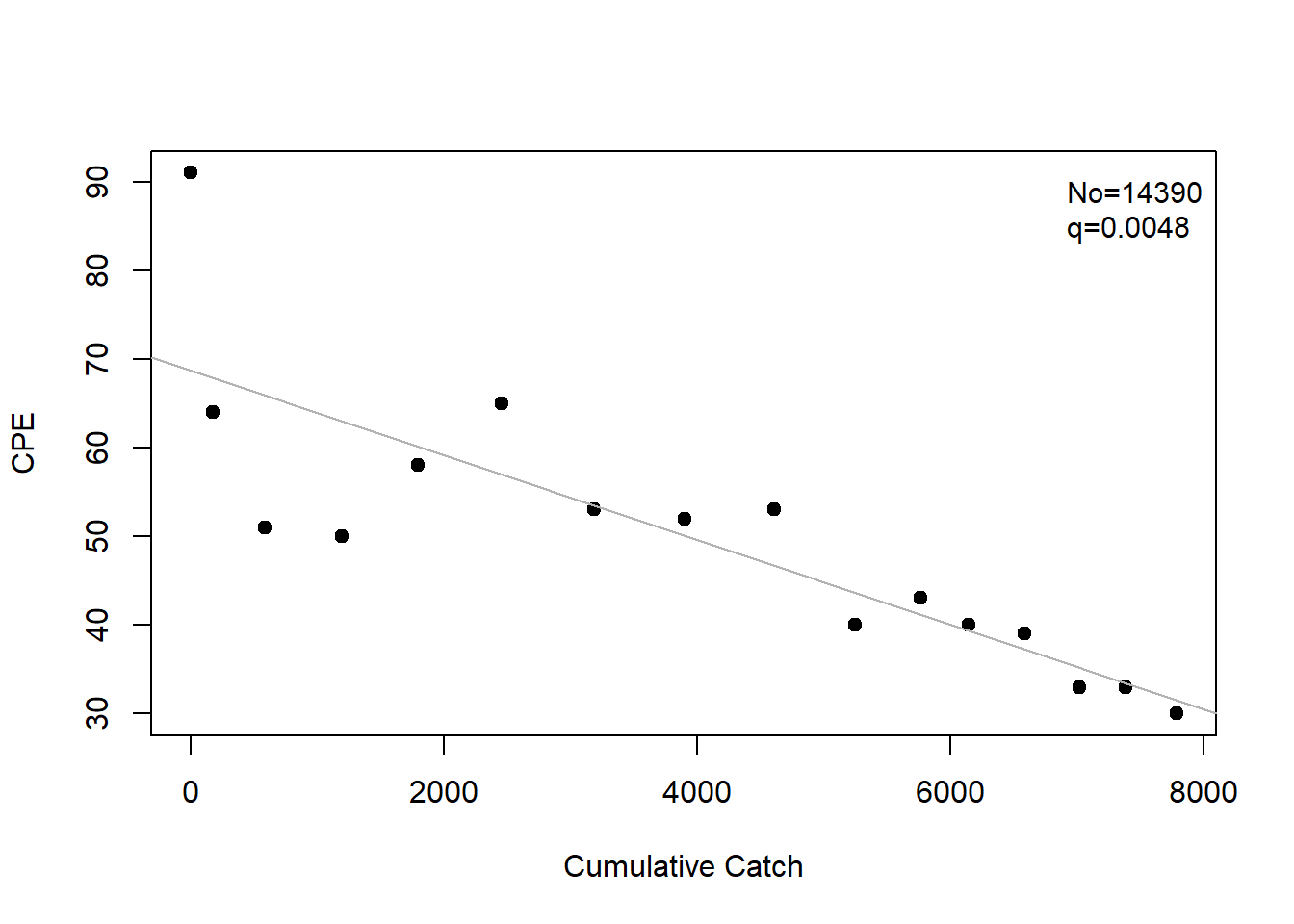
# 3. БАЗОВЫЙ АНАЛИЗ МОДЕЛИ ЛЕСЛИ ДЛЯ ОДНОГО ПЕРИОДА ======================================================================# Фильтрация данных для 2008 года (2007 < YEAR < 2009)DATA <- LESLIDATA[LESLIDATA$YEAR >2007& LESLIDATA$YEAR <2009, ]# Построение модели истощения по методу Лесли# Модель Лесли: CPUE ~ кумулятивное усилие# Использует линейную регрессию для оценки начальной численностиlesli <-depletion(DATA$CATCH, DATA$EFFORT, method ="Leslie")# Визуализация модели# График показывает зависимость CPUE от кумулятивного усилияplot(lesli)
# Доверительные интервалы для параметров моделиconfint(lesli)
95% LCI 95% UCI
No 1.041229e+04 1.836816e+04
q 3.005055e-03 6.548509e-03
# Сводная информация по модели# Включает оценки параметров и статистику качестваsummary(lesli)
Estimate Std. Err.
No 1.439023e+04 1.854700e+03
q 4.776782e-03 8.260623e-04
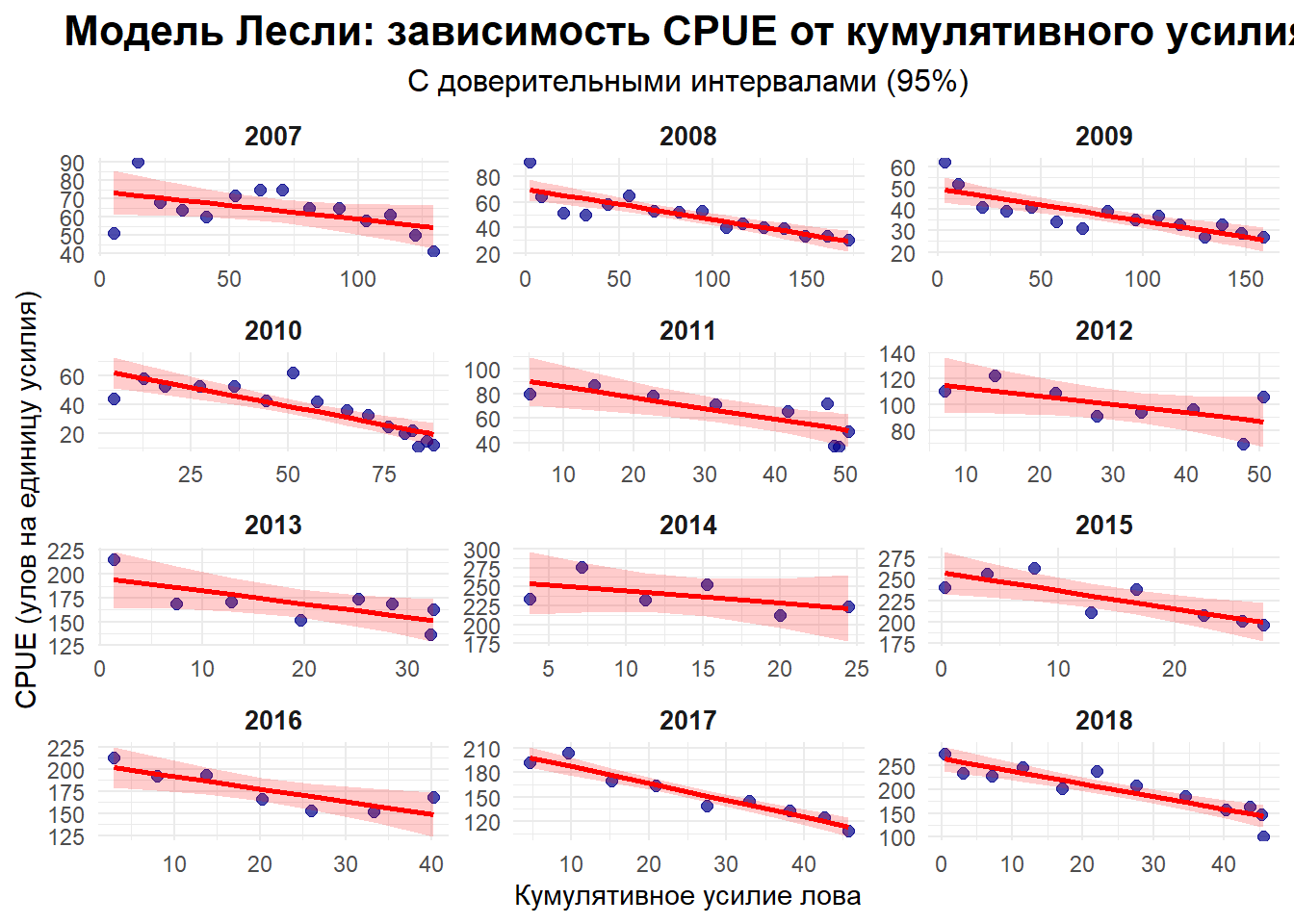
# 4. РАСШИРЕННЫЙ АНАЛИЗ ПО ГОДАМ (2007-2018) =============================================================================# Создаем функцию для расчета кумулятивных показателей# Кумулятивные показатели необходимы для построения моделей истощенияcalculate_cumulative <-function(data) { data %>%arrange(WEEK) %>%# Сортировка по неделямmutate(cumulative_effort =cumsum(EFFORT), # Накопленное усилиеcumulative_catch =cumsum(CATCH) # Накопленный улов )}# Инициализация списка для хранения результатовleslie_models_list <-list()# Анализ для каждого года в диапазоне 2007-2018for (year in2007:2018) {# Фильтрация данных по году year_data <- LESLIDATA %>%filter(YEAR == year) %>%na.omit() # Удаление пропущенных значений# Проверка достаточности данных (минимум 3 наблюдения)if (nrow(year_data) <3) {message(paste("Недостаточно данных для анализа в", year))next# Переход к следующему году }# Расчет кумулятивных показателей year_data <-calculate_cumulative(year_data)# Добавление CPUE (улов на единицу усилия) year_data$CPUE <- year_data$CATCH / year_data$EFFORT# Построение модели Лесли через линейную регрессию leslie_model <-try(lm(CPUE ~ cumulative_effort, data = year_data), silent =TRUE)if (inherits(leslie_model, "try-error")) {# Обработка ошибок моделирования year_data$leslie_predicted <-NA year_data$leslie_lwr <-NA year_data$leslie_upr <-NAmessage(paste("Ошибка в модели Лесли для", year)) } else {# Получение предсказаний с доверительными интервалами predictions <-predict(leslie_model, interval ="confidence", level =0.95) year_data$leslie_predicted <- predictions[, "fit"] year_data$leslie_lwr <- predictions[, "lwr"] year_data$leslie_upr <- predictions[, "upr"]# Расчет начальной биомассы (No)# No = -a/b, где a - интерсепт, b - коэффициент кумулятивного усилия a <-coef(leslie_model)[1] b <-coef(leslie_model)[2] No <--a / b year_data$No <- No }# Сохранение результатов для года leslie_models_list[[as.character(year)]] <- year_data}# Объединение данных всех летall_years_leslie <-bind_rows(leslie_models_list, .id ="Year")# Преобразование Year в фактор с сохранением порядкаall_years_leslie$Year <-factor(all_years_leslie$Year, levels =as.character(2007:2018))# 5. ВИЗУАЛИЗАЦИЯ РЕЗУЛЬТАТОВ МОДЕЛИ ЛЕСЛИ ==============================================================================# Построение фасетного графика для всех летleslie_facet_plot <-ggplot(all_years_leslie, aes(x = cumulative_effort)) +geom_point(aes(y = CPUE), size =2, color ="darkblue", alpha =0.7) +geom_ribbon(aes(ymin = leslie_lwr, ymax = leslie_upr), fill ="red", alpha =0.2) +# Доверительный интервалgeom_line(aes(y = leslie_predicted), color ="red", linewidth =1) +facet_wrap(~ Year, scales ="free", ncol =3) +# Свободные масштабы для каждого годаlabs(title ="Модель Лесли: зависимость CPUE от кумулятивного усилия",subtitle ="С доверительными интервалами (95%)",x ="Кумулятивное усилие лова",y ="CPUE (улов на единицу усилия)" ) +theme_minimal() +theme(plot.title =element_text(hjust =0.5, face ="bold", size =16),plot.subtitle =element_text(hjust =0.5, size =12),strip.text =element_text(face ="bold", size =10) )# Вывод графикаprint(leslie_facet_plot)
Warning: Estimates are suspect as model did not exhibit a significantly (p>0.05)
negative slope.
Warning: Estimates are suspect as model did not exhibit a significantly (p>0.05)
negative slope.
Warning: Estimates are suspect as model did not exhibit a significantly (p>0.05)
negative slope.
Warning: Estimates are suspect as model did not exhibit a significantly (p>0.05)
negative slope.
Warning: Estimates are suspect as model did not exhibit a significantly (p>0.05)
negative slope.
Warning: Estimates are suspect as model did not exhibit a significantly (p>0.05)
negative slope.
Warning: Estimates are suspect as model did not exhibit a significantly (p>0.05)
negative slope.
Warning: Estimates are suspect as model did not exhibit a significantly (p>0.05)
negative slope.
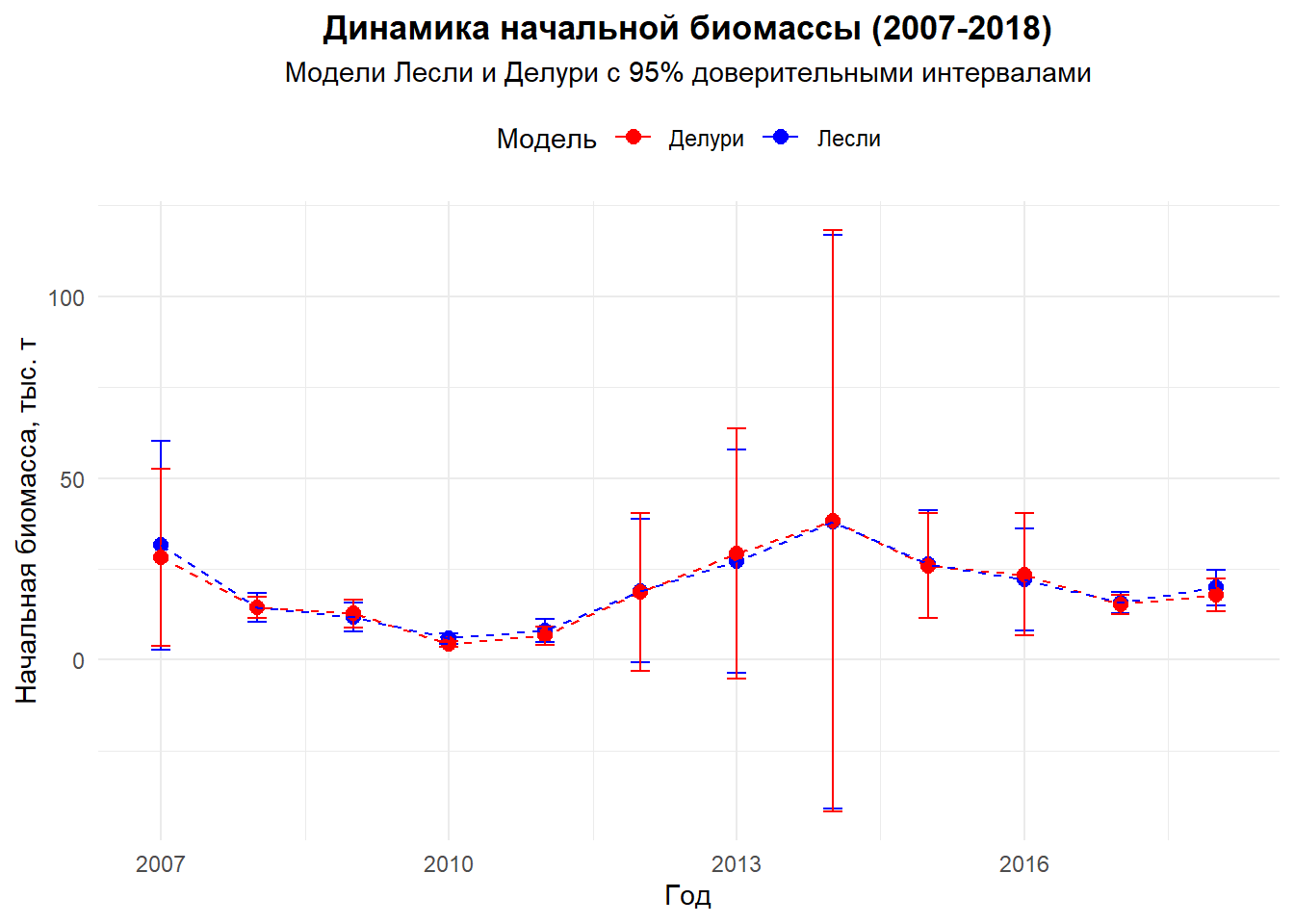
# Преобразование списка в dataframeresults_df <-bind_rows(results_list)# 7. ВИЗУАЛИЗАЦИЯ СРАВНЕНИЯ МОДЕЛЕЙ =====================================================================================# График динамики начальной биомассыbiomass_plot <-ggplot(results_df, aes(x = Year, y = Initial_Biomass/1000, color = Model)) +geom_point(size =2.5) +geom_errorbar(aes(ymin = LCI/1000, ymax = UCI/1000), width =0.2) +geom_line(aes(group = Model), linetype ="dashed") +labs(title ="Динамика начальной биомассы (2007-2018)",subtitle ="Модели Лесли и Делури с 95% доверительными интервалами",x ="Год",y ="Начальная биомасса, тыс. т",color ="Модель" ) +theme_minimal() +theme(plot.title =element_text(hjust =0.5, face ="bold"),plot.subtitle =element_text(hjust =0.5),legend.position ="top" ) +scale_color_manual(values =c("Лесли"="blue", "Делури"="red"))print(biomass_plot)
# 8. ДЕТАЛИЗИРОВАННЫЙ АНАЛИЗ ПАРАМЕТРОВ =================================================================================# Создание таблиц с параметрами моделейleslie_all_years <-data.frame()delury_all_years <-data.frame()for (year in2007:2018) { year_data <- LESLIDATA %>%filter(YEAR == year) %>%na.omit()if (nrow(year_data) <3) next# Анализ для модели ЛеслиtryCatch({ leslie_model <-depletion(year_data$CATCH, year_data$EFFORT, method ="Leslie") leslie_ci <-confint(leslie_model) leslie_all_years <-rbind(leslie_all_years, data.frame( Модель ="Лесли", Год = year,B0 =round(leslie_model$est["No", "Estimate"], 2),B0_LCI =round(leslie_ci["No", "95% LCI"], 2),B0_UCI =round(leslie_ci["No", "95% UCI"], 2),q =round(leslie_model$est["q", "Estimate"], 6),q_LCI =round(leslie_ci["q", "95% LCI"], 6),q_UCI =round(leslie_ci["q", "95% UCI"], 6),R2 =round(summary(leslie_model$lm)$r.squared, 4) )) }, error =function(e) {message(paste("Ошибка в модели Лесли для", year, ":", e$message)) })# Анализ для модели ДелуриtryCatch({ delury_model <-depletion(year_data$CATCH, year_data$EFFORT, method ="DeLury") delury_ci <-confint(delury_model) delury_all_years <-rbind(delury_all_years, data.frame( Модель ="Делури", Год = year,B0 =round(delury_model$est["No", "Estimate"], 2),B0_LCI =round(delury_ci["No", "95% LCI"], 2),B0_UCI =round(delury_ci["No", "95% UCI"], 2),q =round(delury_model$est["q", "Estimate"], 6),q_LCI =round(delury_ci["q", "95% LCI"], 6),q_UCI =round(delury_ci["q", "95% UCI"], 6),R2 =round(summary(delury_model$lm)$r.squared, 4) )) }, error =function(e) {message(paste("Ошибка в модели Делури для", year, ":", e$message)) })}
Warning: Estimates are suspect as model did not exhibit a significantly (p>0.05)
negative slope.
Warning: Estimates are suspect as model did not exhibit a significantly (p>0.05)
negative slope.
Warning: Estimates are suspect as model did not exhibit a significantly (p>0.05)
negative slope.
Warning: Estimates are suspect as model did not exhibit a significantly (p>0.05)
negative slope.
Warning: Estimates are suspect as model did not exhibit a significantly (p>0.05)
negative slope.
Warning: Estimates are suspect as model did not exhibit a significantly (p>0.05)
negative slope.
Warning: Estimates are suspect as model did not exhibit a significantly (p>0.05)
negative slope.
Warning: Estimates are suspect as model did not exhibit a significantly (p>0.05)
negative slope.
# Вывод результатовprint("Таблица параметров модели Лесли по годам:")
# Сохранение результатовwrite.csv(leslie_all_years, "Leslie_parameters_all_years.csv", row.names =FALSE)write.csv(delury_all_years, "Delury_parameters_all_years.csv", row.names =FALSE)# ========================================================================================================================# ИНТЕРПРЕТАЦИЯ РЕЗУЛЬТАТОВ:# 1. Модель Лесли: CPUE = a + b * (кумулятивное усилие)# 2. Модель Делури: ln(CPUE) = a + b * (кумулятивное усилие)# Параметры:# - B0 (No): начальная биомасса/численность# - q: коэффициент уловистости# - R2: показатель качества модели (0-1)# Доверительные интервалы показывают точность оценок# ========================================================================================================================
19.2 Результаты применения моделей истощения
Анализ данных промысла камчатского краба в Баренцевом море с 2007 по 2018 год выявил крайне неоднородную эффективность моделей истощения. В течение 2008-2011 и 2017-2018 годов обе модели демонстрировали статистически значимые результаты с высокими коэффициентами детерминации (R² > 0.65), что указывало на четко выраженный эффект истощения запаса в эти периоды. Наиболее надежные оценки начальной биомассы (B0) были получены для 2008 года: модель Лесли показала 14.4 тыс. тонн, а модель Делури — 14.3 тыс. тонн с относительно узкими доверительными интервалами.
Однако в другие годы (2012-2014) результаты оказались статистически несостоятельными — модели не выявили значимого отрицательного наклона, а доверительные интервалы включали биологически нереалистичные значения, включая отрицательную биомассу. Особенно показательными был 2014 год, где верхняя граница доверительного интервала превышала нижнюю более чем на 150 тыс. тонн, что свидетельствует о крайне ненадежных оценках.
Анализ коэффициента уловистости (q) выявил интересную динамику: значения демонстрировали выраженную изменчивость от 0.0023 в 2007 году до 0.0163 в 2010 году по модели Делури. Начиная с 2011 года значения q стабилизировались на более высоком уровне (0.009-0.015), что может указывать на изменение эффективности промысла или поведенческих характеристик краба.
Сравнительный анализ двух моделей показал их принципиальную согласованность: расхождения в оценках B0 редко превышали 10-15%, что является приемлемым для данного типа моделей. Однако модель ДеЛури в большинстве случаев демонстрировала несколько более высокую точность оценок, выражающуюся в немного более узких доверительных интервалах.
Ключевым выводом исследования стало подтверждение ограниченной применимости моделей истощения — они работают адекватно только в условиях контролируемого промысла с изолированной популяцией. После 2018 года, с появлением новых промысловых игроков, модели потеряли практическую ценность, поскольку нарушилось основное предположение о закрытости системы и стабильности технологии добычи. Таким образом, несмотря на теоретическую элегантность, модели Лесли и Делури остаются нишевым инструментом, применимым лишь в редких условиях идеального промыслового сценария.