Продолжим с честного предупреждения. Как только мы делим запас на осмысленные группы — пререкруты, рекруты, пострекруты — и прописываем переходы между ними, очень легко почувствовать, что мы «внутри механизма», а значит, управляем им. Это та самая иллюзия контроля: формула кажется ближе к биологии, чем функция продукции в продукционной модели, и мозг дорисовывает уверенность, которой в данных может не хватать. Дисциплина «медленного» режима анализа данных и работы мозга в том, чтобы отделить структуру от знания: CSA и правда даёт больше биологического смысла, но достоверность этого смысла определяется не изяществом уравнений, а качеством наблюдений, идентифицируемостью параметров и тем, как аккуратно мы проверяем альтернативы. У системы есть история, пороги, сдвиги и запаздывания; толстые хвосты и редкие годы «сюрпризов». Наша задача — встроить всё это в анализ, не потеряв прозрачности и воспроизводимости.
Практическая ценность CSA в том, что она распаковывает общую динамику по «каналам»: пополнение, рост (переходы между категориями), естественная смертность и изъятие промыслом, а затем связывает скрытые состояния с наблюдаемыми индексами через улавливаемость. Это полезно для объектов с выборочным промыслом (например, только крупные самцы) и сильно неоднородной размерной структурой: давление смещается по группам, и агрегаты легко маскируют реальные сдвиги. Но вместе с детализацией приходит классическая ловушка идентифицируемости: M путается с q, переходные вероятности (Gp, Gr, Mp) — между собой, процессная дисперсия — с наблюдательной. Если не заякорить параметры априорами и не опереться на внешнюю информацию (калибровки тралов, биологию линьки, разумные диапазоны смертности), модель будет «объяснять» всё и сразу, но в каждом запуске по‑разному. Байесовская постановка — именно способ честно ввести эти якоря и сразу показать, где данные «передвинули» прайеры, а где — нет.
Главные источники смещения здесь не банальны. Улавливаемость редко постоянна: меняются суда, орудия, глубины, сезонность; индексы могут отражать доступность, а не истинную численность. Выборочная природа съёмок порождает нули и неоднородную дисперсию; логнормальная модель наблюдений удобна, но не всегда робастна к выбросам. Переходы между группами зависят от роста и линьки, а значит — от среды; если эти зависимости «впитаны» в постоянные Gp/Gr/Mp, то часть динамики будет ложиться в ошибки. Поэтому мы заранее признаём: фиксированные прайеры — осознанный компромисс, а чувствительность к прайерам — обязательная проверка, а не факультатив.
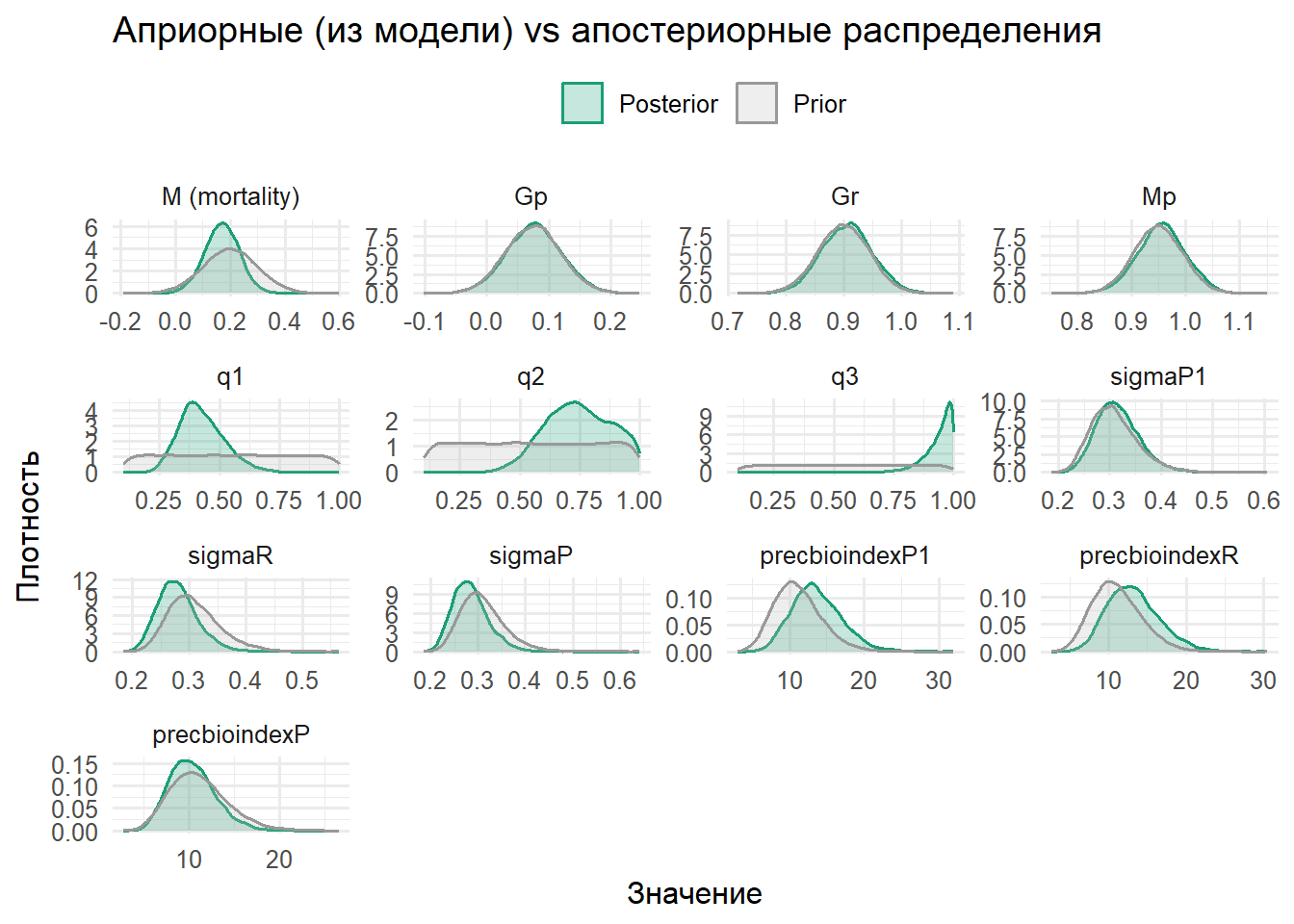
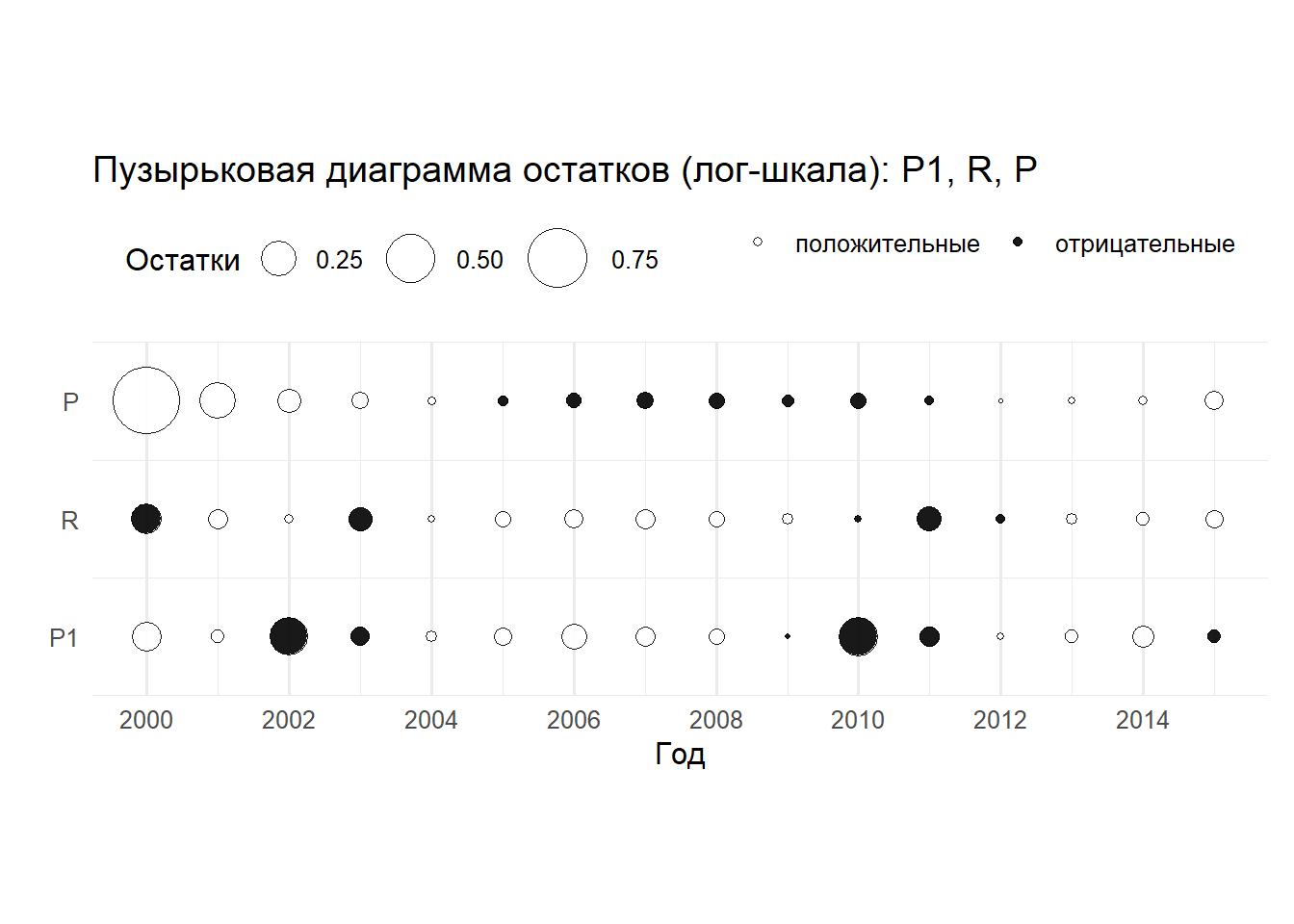
Диагностика — не приложение, а часть модели. Мы смотрим траектории цепей, эффективный размер выборки, MC‑ошибку, проверяем сходимость независимых цепей и, что не менее важно, сопоставляем прайеры и постериоры по ключевым параметрам: если плотности почти не разошлись, значит, данные нас мало чему научили; если разошлись «до хвостов» — возможно, мы зашли за границы биологически правдоподобного. Постериорные проверочные прогонки (posterior predictive) — простой и мощный тест: генерируем псевдо‑индексы из модели и убеждаемся, что реальная серия не выглядит «инородным телом». Бабл‑графики остатков по группам и годам помогают увидеть систематику: дрейф знака — сигнал к времени‑зависимому q или пропущенным ковариатам. А вероятность нарушить управленческий предел (PR < PRlim) должна выводиться прямо из постериора, а не прикидываться на глаз по одной траектории.
Стабильность выводов проверяем во времени — ретроспективой. Отрезая по одному–несколько последних лет и переоценивая модель, мы видим, «дышит» ли оценка прошлых лет от добавления новой информации. Это сохраняет нас от соблазна «подогнать настоящее» и выдать его за прогнозную силу. Там же хорошо выявляются скрытые конфликты идентифицируемости: если при каждом «срезе» меняется баланс M–q или расползаются переходы из одной размерной категории в другую, значит, данных не хватает или прайеры слишком расплывчаты. Такой «проверенный на бордюре» консерватизм — это не скепсис, а инструмент против самоуверенности.
Часть неопределённости мы принимаем как данность и переводим в язык решений. Менеджменту нужны не «числа», а вероятности: какова P(PR<PRlim) в текущем году, как меняется она при сценарии улова, каков шанс сохранить PR над порогом при консервативном и при агрессивном изъятии. Картина «веера» — медиана и 50/95% интервалы — честнее единственной жирной линии. И здесь полезна мысль: аккуратно собранные данные и прозрачные процедуры, повторённые из года в год, делают систему разумнее — даже если в каждом конкретном году интервал широк. Прогресс не в том, чтобы угадать до тонны, а в том, чтобы системно сокращать неопределённость и принимать решения, устойчивые к её остаткам.
Практическая реализация в этом занятии выдержана в том же ключе. Мы задаём прайеры, учим модель в JAGS, сохраняем полные постериоры параметров и состояний, сравниваем прайеры с постериорами, строим диагностические графики остатков и динамики по группам, считаем вероятность пересечения порога PRlim и даём интерпретацию в управленческих терминах. Там, где это уместно, тестируем чувствительность к диапазонам прайеров на M и q, а также к альтернативам в наблюдательной части (логнормальная дисперсия). И да, Excel‑симулятор на четыре группы — не игрушка, а хороший способ «почувствовать руками» идентифицируемость: как меняется постериор при фиксации M, при расширении дисперсий наблюдений, при «дрейфе» q. Интуиция, подкреплённая такими играми, экономит много времени в полноценной байесовской оценке.
Наконец, важная оговорка: CSA — не конечная станция. В данных с явными климатическими сдвигами стоит рассмотреть время‑зависимую улавливаемость, ковариаты для переходов и смертности, иерархическую связку нескольких съёмок. Если в этом блоке мы делаем базовую, учебную версию, то следующий шаг — включать «регуляторы» сложности только после того, как базовая модель пройдёт диагностику. Это тот самый «мост» между ясностью и гибкостью: сперва минимально достаточная структура, затем — аккуратные расширения с прицельной проверкой альтернатив. Так вводится порядок в систему, где соблазнов «знать больше, чем знаем» всегда больше, чем данных.
И так, модель “анализа уловов и съемок” - Catch-Survey Analysis (CSA) представляет собой инструмент для оценки состояния запасов, особенно тех видов, данные по индивидуальному возрасту которых труднодоступны или отсутствуют, что типично для многих беспозвоночных, таких как крабы, креветки, а также для некоторых рыб. В отличие от классических продукционных моделей, которые оперируют агрегированными показателями всей популяции и требуют строгих допущений о ее равновесном состоянии и постоянной емкости среды, когортные модели, подобные CSA, позволяют отслеживать судьбу отдельных функциональных категорий (например, пререкруты, рекруты, пострекруты). Они явным образом учитывают такие процессы, как рост, пополнение и естественная смертность, разделяя запас на дискретные размерные или возрастные группы. Это дает несомненное преимущество при анализе динамики популяций с выраженной цикличностью или тех, которые подвергаются интенсивному промысловому прессу, избирательно воздействующему на определенные размерные или возрастные категории (например, пререкруты не подвержены прямой прмысловой смертности в отличие от рекрутов и посрекрутов). Подробнее о модели и ее реализации можно почитать в статье “Результаты применения стохастической когортной модели CSA для оценки запаса камчатского краба Paralithodes camtschaticus в Баренцевом море”. В статье описывается реализация модели в программе OpenBUGS, которая в упрощенном виде (без прогноза, риск-анализа и диагностики) и в учебных целях была переведена в среду R и представлена ниже, а полный срипт здесь.Также доступна иммитационная CSA модель для 4 размерных групп, реализованная в MS Excel по ссылке.
Данная реализация модели представляет собой байесовский подход к оценке запасов, который позволяет учитывать неопределенности как в процессе динамики популяции, так и в процессе наблюдений, что особенно важно при работе с данными, характеризующимися высокой вариабельностью и неполнотой. В основе модели лежит разделение популяции на три размерно-возрастные группы: пререкруты (P1), рекруты (R) и пострекруты (P), что соответствует биологическим особенностям многих видов крабов, включая камчатского краба. Модель включает два основных компонента: динамику процесса, описывающую естественные изменения численности популяции, и модель наблюдений, связывающую ненаблюдаемые “истинную” численность запаса с доступными данными съемок (индексами численности пререкрутов, рекрутов и пострекрутов). Уравнения процессной динамики для пострекрутов имеют вид:
Gp обозначает вероятность перехода пререкрутов в пострекруты,
Mp - вероятность линьки пререкрутов,
M - коэффициент естественной смертности, а εP представляет собой процессную ошибку.
Для рекрутов уравнение динамики выглядит как
R[i] = (P1[i-1]×Gr×Mp) × exp(-M) + εR, где
Gr - вероятность перехода пререкрутов в рекруты. Динамика пререкрутов моделируется как лог-случайное блуждание P1[i] = P1[i-1] + εP1. Модель наблюдений предполагает, что данные траловых съемок соответствуют логнормальному распределению относительно истинной численности, умноженной на коэффициент улавливаемости:
аналогично для рекрутов и пострекрутов, где q1, q2, q3 - коэффициенты улавливаемости для каждой группы, а precbioindex - параметры точности. В байесовском подходе ключевую роль играют априорные распределения параметров, которые в данной реализации задаются как равномерные для коэффициентов улавливаемости (q1, q2, q3 ~ dunif(0.1,1)), нормальные для вероятностей перехода (Gr ~ dnorm(0.9,500), Gp ~ dnorm(0.075,500), Mp ~ dnorm(0.95,500)) и для коэффициента естественной смертности (M ~ dnorm(0.2,100)). Использование байесовского подхода позволяет не только получить точечные оценки параметров, но и оценить полные апостериорные распределения, что дает возможность проводить риск-анализ различных сценариев управления запасом. В данном занятии мы реализуем модель CSA в среде R с использованием пакетов rjags и coda, что позволяет эффективно работать с байесовскими иерархическими моделями через интерфейс с программой JAGS, которую также необходимо установить.
Мы рассмотрим полный цикл работы с моделью: от подготовки данных и задания априорных распределений до обучения модели и анализа результатов, включая визуализацию априорных и апостериорных распределений параметров, анализ остатков и сравнение моделируемой и фактической динамики запаса. Особое внимание будет уделено интерпретации результатов в контексте управления водными биоресурсами, что является ключевой целью применения подобных моделей в практической деятельности гидробиологов и ихтиологов.
9.2 Реализация модели
# ========================================================================================================================# ПРАКТИЧЕСКОЕ ЗАНЯТИЕ: МОДЕЛЬ Catch-Survey Analysis (CSA) - три категории (пререкруты (P1), рекруты (R), пострекруты (P)# Курс: "Оценка водных биоресурсов в среде R (для начинающих)"# Автор: Баканев С. В. Дата: 20.08.2025# Структура:# 1) Входные данные# 2) Модель# 3) Прайеры# 4) Обучение модели# 5) Подготовка выходных данных # 6) Анализ результатов (визуализация априорных и апостериорных параметров;бабл-плоты остатков; динамика индексов) # ========================================================================================================================# Установка рабочей директорииsetwd("C:/CSA")# Подключение необходимых библиотек# install.packages(c("rjags", "coda")) # Раскомментировать для установкиlibrary(rjags) # Для работы с JAGS
Загрузка требуемого пакета: coda
Linked to JAGS 4.3.1
Loaded modules: basemod,bugs
library(coda) # Для анализа MCMC-выходаlibrary(ggplot2)# Рисунки# ========================================================================================================================# --- Входные данные ---# ========================================================================================================================data_list <-list(N =16,# Количество временных точек# Наблюдаемые данные (индексы запаса)bioindexP1 =c(1500,1028,554,887,1345,1817,2291,1958,1500,1028,554,887,1345,1817,2291,1958),bioindexR =c(2531,1927,1305,764,1216, 1820,2442,2983,2531,1927,1305,764,1216,1820,2442,2983),bioindexP =c(13741,13770,13060,11653,9782,8634,8321,8793,9809,10177,9776,9566,8789,8640,9240,10547),catch =c(6,2,6,15,21,37,37,315,945,890,991,1060,1000,1000,1600,1673,1250))# Создание вектора лет для подписейYEAR <-2000+0:(data_list$N -1)# ========================================================================================================================# --- Генерация модели CSA --# ========================================================================================================================model_string <-"model { for (i in 1:N) { bioindexP1med[i] <- log(1.0E-6 + q1 * P1[i]) bioindexP1[i] ~ dlnorm(bioindexP1med[i], precbioindexP1) bioindexRmed[i] <- log(1.0E-6 + q2 * R[i]) bioindexR[i] ~ dlnorm(bioindexRmed[i], precbioindexR) bioindexPmed[i] <- log(1.0E-6 + q3 * P[i]) bioindexP[i] ~ dlnorm(bioindexPmed[i], precbioindexP) } inv_surv <- exp(-M)# Коэффициент естественной смертности for (i in 2:N) { tmpPraw[i] <- (P1[i-1]*Gp*Mp + R[i-1] + P[i-1] - catch[i-1]) * inv_surv tmpPpos[i] <- tmpPraw[i] * step(tmpPraw[i]) Pmed[i] <- log(1.0E-6 + tmpPpos[i]) P[i] ~ dlnorm(Pmed[i], precP) tmpRraw[i] <- (P1[i-1]*Gr*Mp) * inv_surv tmpRpos[i] <- tmpRraw[i] * step(tmpRraw[i]) Rmed[i] <- log(1.0E-6 + tmpRpos[i]) R[i] ~ dlnorm(Rmed[i], precR) P1med[i] <- log(1.0E-6 + P1[i-1]) P1[i] ~ dlnorm(P1med[i], precP1) } for (i in 1:N) { PR[i] <- P[i] + R[i] p.PRlim[i] <- step(PRlim - PR[i]) } PRlim <- 4000 P1[1] ~ dunif(200,4000) P[1] ~ dunif(200,6000) R[1] ~ dunif(200,25000) Gr ~ dnorm(0.9, 500) Gp ~ dnorm(0.075,500) Mp ~ dnorm(0.95, 500) precbioindexP1 ~ dgamma(12.22, 1.1) precbioindexR ~ dgamma(12.22, 1.1) precbioindexP ~ dgamma(12.22, 1.1) q1 ~ dunif(0.1,1) q2 ~ dunif(0.1,1) q3 ~ dunif(0.1,1) precP1 ~ dgamma(12.22, 1.1) precR ~ dgamma(12.22, 1.1) precP ~ dgamma(12.22, 1.1) M ~ dnorm(0.2, 100)}"# ========================================================================================================================# --- Обучение модели ---# ========================================================================================================================set.seed(1) # Для воспроизводимости# Инициализация модели JAGSjm <-jags.model(textConnection(model_string), # Модель из строкиdata = data_list, # Данныеn.chains =3, # Количество цепейn.adapt =1500# Длина адаптационной фазы)
Compiling model graph
Resolving undeclared variables
Allocating nodes
Graph information:
Observed stochastic nodes: 48
Unobserved stochastic nodes: 61
Total graph size: 576
Initializing model
# Обновление модели (burn-in)update(jm, 4000)# Переменные для мониторингаvars_to_monitor <-c("M","Gp","Gr","Mp","q1","q2","q3", # Параметры"precP","precP1","precR","precbioindexP","precbioindexP1","precbioindexR", # Точности"P","P1","R","PR","p.PRlim"# Состояния и производные)# Генерация MCMC-выборокsamps <-coda.samples( jm, variable.names = vars_to_monitor, # Мониторируемые переменныеn.iter =6000, # Длина выборкиthin =3# Прореживание)# ========================================================================================================================# --- Анализ результатов ---# ========================================================================================================================# Стандартная статистика по выборкамsm <-summary(samps)stats <- sm$statistics # Средние, SD, стандартные ошибкиquants <- sm$quantiles # Квантили (2.5%, 25%, 50%, 75%, 97.5%)# Матрица всех сэмплов для ручных вычисленийdraws_mat <-as.matrix(samps)# Функция для расчета MC ошибки через эффективный размер выборкиmcse_from_ess <-function(vec) { ess <-effectiveSize(as.mcmc(vec)) # Эффективный размер выборкиsd(vec) /sqrt(as.numeric(ess)) # MC ошибка}# Функция для создания строки результатаmake_row <-function(year, mapping, node, mean, sd, mcse, q2.5, q25, q50, q75, q97.5) {data.frame(YEAR = year,`#Vectors to monitor`= mapping,node = node,mean = mean,sd = sd,`MC error`= mcse,`2.50%`= q2.5,`25.00%`= q25,median = q50,`75.00%`= q75,`97.50%`= q97.5,check.names =FALSE )}# Список для накопления результатовrows <-list()# Функция добавления скалярных параметровadd_scalar <-function(x_idx, vname) {if (vname %in%rownames(stats)) {# Если параметр есть в готовой статистике m <- stats[vname, "Mean"] s <- stats[vname, "SD"] mcse <-mcse_from_ess(draws_mat[, vname]) q <- quants[vname, c("2.5%", "25%", "50%", "75%", "97.5%")] rows[[length(rows) +1]] <<-make_row(NA, paste0("x[", x_idx, "]<-", vname), paste0("x[", x_idx, "]"), m, s, mcse, q[1], q[2], q[3], q[4], q[5]) } elseif (vname %in%c("sigmaP1","sigmaR","sigmaP")) {# Для стандартных отклонений (преобразуем из точности) src <-switch(vname,sigmaP1 ="precP1",sigmaR ="precR",sigmaP ="precP")if (src %in%colnames(draws_mat)) { vec <-sqrt(1/ draws_mat[, src]) # Преобразование precision -> sigma m <-mean(vec); s <-sd(vec); mcse <-mcse_from_ess(vec) q <-quantile(vec, c(0.025,0.25,0.5,0.75,0.975)) rows[[length(rows) +1]] <<-make_row(NA, paste0("x[", x_idx, "]<-", vname), paste0("x[", x_idx, "]"), m, s, mcse, q[1], q[2], q[3], q[4], q[5]) } }}# Добавление основных параметровadd_scalar(1, "M")add_scalar(2, "q1")add_scalar(3, "q2")add_scalar(4, "q3")add_scalar(5, "sigmaP1")add_scalar(6, "sigmaR")add_scalar(7, "sigmaP")add_scalar(8, "precbioindexP1")add_scalar(9, "precbioindexR")add_scalar(10, "precbioindexP")add_scalar(11, "Gr")add_scalar(12, "Gp")add_scalar(13, "Mp")# Функция добавления временных рядовadd_series <-function(base_idx, varname, years) {for (i inseq_along(years)) { rn <-paste0(varname, "[", i, "]") # Имя переменной с индексомif (!rn %in%rownames(stats)) next# Пропуск если нет данных m <- stats[rn, "Mean"] s <- stats[rn, "SD"] mcse <-mcse_from_ess(draws_mat[, rn]) q <- quants[rn, c("2.5%", "25%", "50%", "75%", "97.5%")] xi <- base_idx + (i -1) # Вычисление индекса в выходной таблице rows[[length(rows) +1]] <<-make_row(years[i], paste0("x[", xi, "]<-", rn), paste0("x[", xi, "]"), m, s, mcse, q[1], q[2], q[3], q[4], q[5]) }}# Добавление временных рядовadd_series(100, "P1", YEAR)add_series(200, "R", YEAR)add_series(300, "P", YEAR)# Создание итоговой таблицыout_df <-do.call(rbind, rows)# Создание групп для сортировкиout_df$group <-ifelse(is.na(out_df$YEAR), "param",ifelse(grepl("<-P1\\[", out_df$`#Vectors to monitor`), "P1",ifelse(grepl("<-R\\[", out_df$`#Vectors to monitor`), "R", "P")))# Сортировка параметров по индексуparam_rows <- out_df[out_df$group =="param", ]param_idx <-as.numeric(sub(".*\\[(\\d+)\\].*", "\\1", param_rows$node))param_rows <- param_rows[order(param_idx), ]# Сортировка временных рядов по годуp1_rows <- out_df[out_df$group =="P1", ]p1_rows <- p1_rows[order(p1_rows$YEAR), ]r_rows <- out_df[out_df$group =="R", ]r_rows <- r_rows[order(r_rows$YEAR), ]p_rows <- out_df[out_df$group =="P", ]p_rows <- p_rows[order(p_rows$YEAR), ]# Компоновка финальной таблицыout_df <-rbind(param_rows, p1_rows, r_rows, p_rows)out_df$group <-NULL# Удаление вспомогательной колонки# Сохранение результатовwrite.csv(out_df, "monitor_summary.csv", row.names =FALSE)cat("Saved: monitor_summary.csv\n")
Saved: monitor_summary.csv
# Вывод структуры результатовstr(out_df)
'data.frame': 61 obs. of 11 variables:
$ YEAR : num NA NA NA NA NA NA NA NA NA NA ...
$ #Vectors to monitor: chr "x[1]<-M" "x[2]<-q1" "x[3]<-q2" "x[4]<-q3" ...
$ node : chr "x[1]" "x[2]" "x[3]" "x[4]" ...
$ mean : num 0.171 0.424 0.743 0.935 0.315 ...
$ sd : num 0.0657 0.1013 0.1378 0.06 0.0409 ...
$ MC error : num 0.002236 0.007709 0.009833 0.001268 0.000566 ...
$ 2.50% : num 0.045 0.262 0.49 0.776 0.244 ...
$ 25.00% : num 0.127 0.346 0.638 0.906 0.285 ...
$ median : num 0.17 0.415 0.741 0.953 0.312 ...
$ 75.00% : num 0.216 0.489 0.851 0.98 0.341 ...
$ 97.50% : num 0.302 0.645 0.982 0.998 0.404 ...
# ========================================================================================================================# Визуализация априорных и апостериорных параметров# Параметры: M, Gp, Gr, Mp, q1, q2, q3, precP1, precR, precP, precbioindexP1, precbioindexR, precbioindexP# И производные: sigmaP1, sigmaR, sigmaP# ========================================================================================================================# Сэмплируем приоры прямо из той же JAGS-модели (без данных)sample_priors_from_model <-function(model_string, n_iter =20000, n_adapt =500) { jm_prior <-jags.model(textConnection(model_string), data =list(N =0), n.chains =1, n.adapt = n_adapt) vars <-c("M","Gp","Gr","Mp","q1","q2","q3","precP1","precR","precP","precbioindexP1","precbioindexR","precbioindexP") priors <-coda.samples(jm_prior, variable.names = vars, n.iter = n_iter)as.matrix(priors)}# Получаем матрицы приоров и постериоровprior_mat <-sample_priors_from_model(model_string, n_iter =20000, n_adapt =500)
Compiling model graph
Resolving undeclared variables
Allocating nodes
Graph information:
Observed stochastic nodes: 0
Unobserved stochastic nodes: 16
Total graph size: 33
Initializing model
post_mat <-as.matrix(samps)# Добавляем производные сигмы из прецизионовadd_sigmas <-function(mat) { add <-function(dst, src) {if (all(src %in%colnames(mat))) dst <-cbind(dst, setNames(as.data.frame(sqrt(1/mat[, src, drop=FALSE])), gsub("^prec","sigma", src))) dst } out <- mat out <-add(out, c("precP1")) out <-add(out, c("precR")) out <-add(out, c("precP")) out}prior_mat <-add_sigmas(prior_mat)post_mat <-add_sigmas(post_mat)# Список параметров для визуализацииparams <-intersect(c("M","Gp","Gr","Mp","q1","q2","q3","sigmaP1","sigmaR","sigmaP","precbioindexP1","precbioindexR","precbioindexP"),union(colnames(prior_mat), colnames(post_mat)))# В long-форматmk_df <-function(mat, label) {if (is.null(mat) ||nrow(mat) ==0) return(data.frame()) mat <- mat[, intersect(colnames(mat), params), drop =FALSE]reshape(data.frame(iter =seq_len(nrow(mat)), mat, check.names =FALSE),direction ="long", varying = params, v.names ="value", timevar ="param", times = params )[, c("param","value")]}prior_df <-mk_df(prior_mat, "Prior"); prior_df$dist <-"Prior"post_df <-mk_df(post_mat, "Posterior"); post_df$dist <-"Posterior"plot_df <-rbind(prior_df, post_df)# Подписиparam_labels <-c(M="M (mortality)", Gp="Gp", Gr="Gr", Mp="Mp",q1="q1", q2="q2", q3="q3",sigmaP1="sigmaP1", sigmaR="sigmaR", sigmaP="sigmaP",precbioindexP1="precbioindexP1", precbioindexR="precbioindexR", precbioindexP="precbioindexP")plot_df$param_f <-factor(plot_df$param, levels = params, labels =unname(param_labels[params]))# График prior vs posterior (берёт priors из модели!)library(ggplot2)ggplot(plot_df, aes(x = value, color = dist, fill = dist)) +geom_density(alpha =0.25, linewidth =0.7) +facet_wrap(~ param_f, scales ="free", ncol =4) +scale_color_manual(values =c("Prior"="#999999", "Posterior"="#1b9e77")) +scale_fill_manual(values =c("Prior"="#bbbbbb", "Posterior"="#1b9e77")) +labs(title ="Априорные (из модели) vs апостериорные распределения",x ="Значение", y ="Плотность", color ="", fill ="") +theme_minimal(base_size =12) +theme(legend.position ="top")
# ========================================================================================================================# Бабл-плоты остатков P1, R, P по годам (2000–2015)# Требуется: объекты samps, data_list. Если YEAR не создан, создадим.# ========================================================================================================================if (!exists("YEAR")) YEAR <-2000+0:(data_list$N -1)draws_mat <-as.matrix(samps)eps <-1.0e-6resid_bubble_summary <-function(series, obs_vec, q_name, state_name_prefix) { rows <-list()for (i inseq_along(obs_vec)) {if (is.na(obs_vec[i])) next q_draws <- draws_mat[, q_name] state_draws <- draws_mat[, paste0(state_name_prefix, "[", i, "]")]# residual per draw: log(observed) - log(expected) res_draws <-log(obs_vec[i]) -log(eps + q_draws * state_draws) r_mean <-mean(res_draws, na.rm =TRUE) rows[[length(rows) +1]] <-data.frame(YEAR = YEAR[i],series = series,resid = r_mean,abs_resid =abs(r_mean),sign =ifelse(r_mean >=0, "pos", "neg") ) }do.call(rbind, rows)}b1 <-resid_bubble_summary("P1", data_list$bioindexP1, "q1", "P1")b2 <-resid_bubble_summary("R", data_list$bioindexR, "q2", "R")b3 <-resid_bubble_summary("P", data_list$bioindexP, "q3", "P")bubbles <-rbind(b1, b2, b3)# Порядок рядов сверху вниз: P1, R, Pbubbles$series <-factor(bubbles$series, levels =c("P1", "R", "P"))# Убираем пустое расстояние - используем минимальные интервалыlvl <-c("P1","R","P")y_map <-setNames(c(1, 2, 3), lvl) # Числовые позиции без больших промежутковbubbles$y_pos <-unname(y_map[as.character(bubbles$series)])# Создаем вытянутый прямоугольный графикggplot(bubbles, aes(x = YEAR, y = y_pos)) +geom_point(aes(size = abs_resid, fill = sign), shape =21, color ="black", alpha =0.9) +scale_fill_manual(values =c(neg ="black", pos ="white"),breaks =c("pos","neg"),labels =c("положительные","отрицательные"),name ="") +scale_size_area(max_size =12, name ="Остатки") +scale_x_continuous(breaks =seq(2000, 2015, by =2), limits =c(2000, 2015)) +scale_y_continuous(breaks =unname(y_map), labels =names(y_map),limits =c(0.5, 3.5), # Убираем пустое пространство сверху и снизуexpand =c(0, 0)) +# Убираем расширение осейlabs(title ="Пузырьковая диаграмма остатков (лог-шкала): P1, R, P", x ="Год", y ="") +theme_minimal(base_size =12) +theme(legend.position ="top",panel.grid.major.y =element_blank(),axis.ticks.y =element_blank(),aspect.ratio =0.3, # Делаем график вытянутым прямоугольником (ширина > высоты)plot.margin =margin(5, 10, 5, 5, "pt") # Убираем лишние отступы вокруг графика )
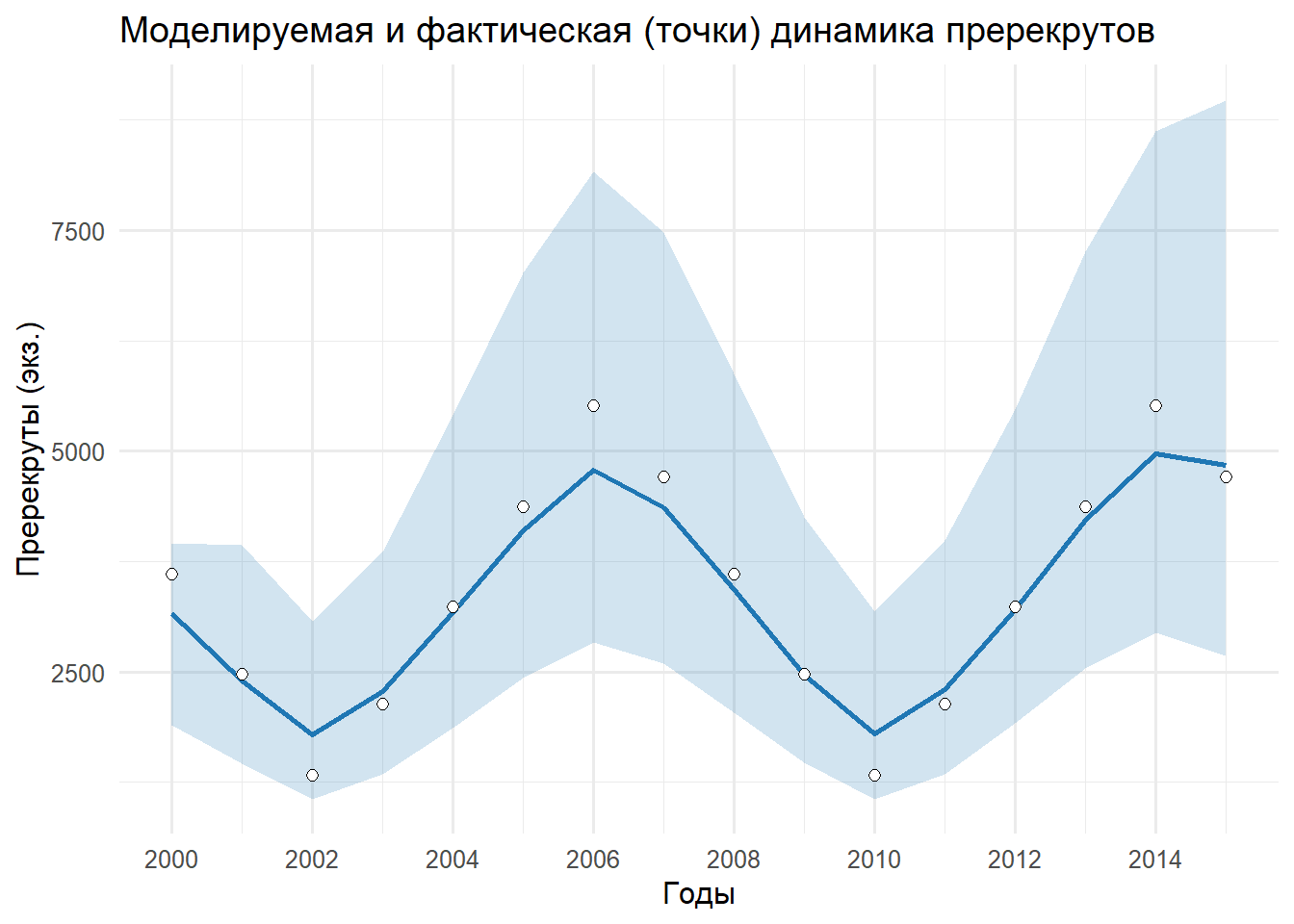
# ========================================================================================================================# ДИНАМИКА ИНДЕКСОВ (ПРЕРЕКРУТЫ, РЕКРУТЫ, ПОСТРЕКРУТЫ) МОДЕЛЬНЫХ И ФАКТИЧЕСКИХ (ТОЧКИ)# ========================================================================================================================# Три графика динамики P1, R, P: медиана (линия), 95% ДИ (лента), точки — наблюдения,# приведённые к единому масштабу делением на медиану q (Posterior median).# ========================================================================================================================if (!exists("YEAR")) YEAR <-2000+0:(data_list$N -1)draws_mat <-as.matrix(samps)series_summary <-function(varname, obs_vec, qname, series_label) { med_q <-median(draws_mat[, qname], na.rm =TRUE) rows <-vector("list", length(obs_vec))for (i inseq_along(obs_vec)) { rn <-paste0(varname, "[", i, "]")if (!rn %in%colnames(draws_mat)) next v <- draws_mat[, rn] qs <-quantile(v, c(0.025, 0.5, 0.975), na.rm =TRUE) obs_state <-if (!is.na(obs_vec[i])) obs_vec[i] / med_q elseNA_real_ rows[[i]] <-data.frame(YEAR = YEAR[i],series = series_label,median = qs[2],lo = qs[1],hi = qs[3],obs = obs_state ) }do.call(rbind, rows)}df_p1 <-series_summary("P1", data_list$bioindexP1, "q1", "P1")df_r <-series_summary("R", data_list$bioindexR, "q2", "R")df_p <-series_summary("P", data_list$bioindexP, "q3", "P")p_P1 <-ggplot(df_p1, aes(x = YEAR)) +geom_ribbon(aes(ymin = lo, ymax = hi), fill ="#1f77b4", alpha =0.2) +geom_line(aes(y = median), color ="#1f77b4", linewidth =1) +geom_point(aes(y = obs), shape =21, size =2, color ="black", fill ="white", na.rm =TRUE) +scale_x_continuous(breaks =seq(2000, 2015, by =2), limits =c(2000, 2015)) +labs(title ="Моделируемая и фактическая (точки) динамика пререкрутов", x ="Годы", y ="Пререкруты (экз.)") +theme_minimal(base_size =12)print(p_P1)
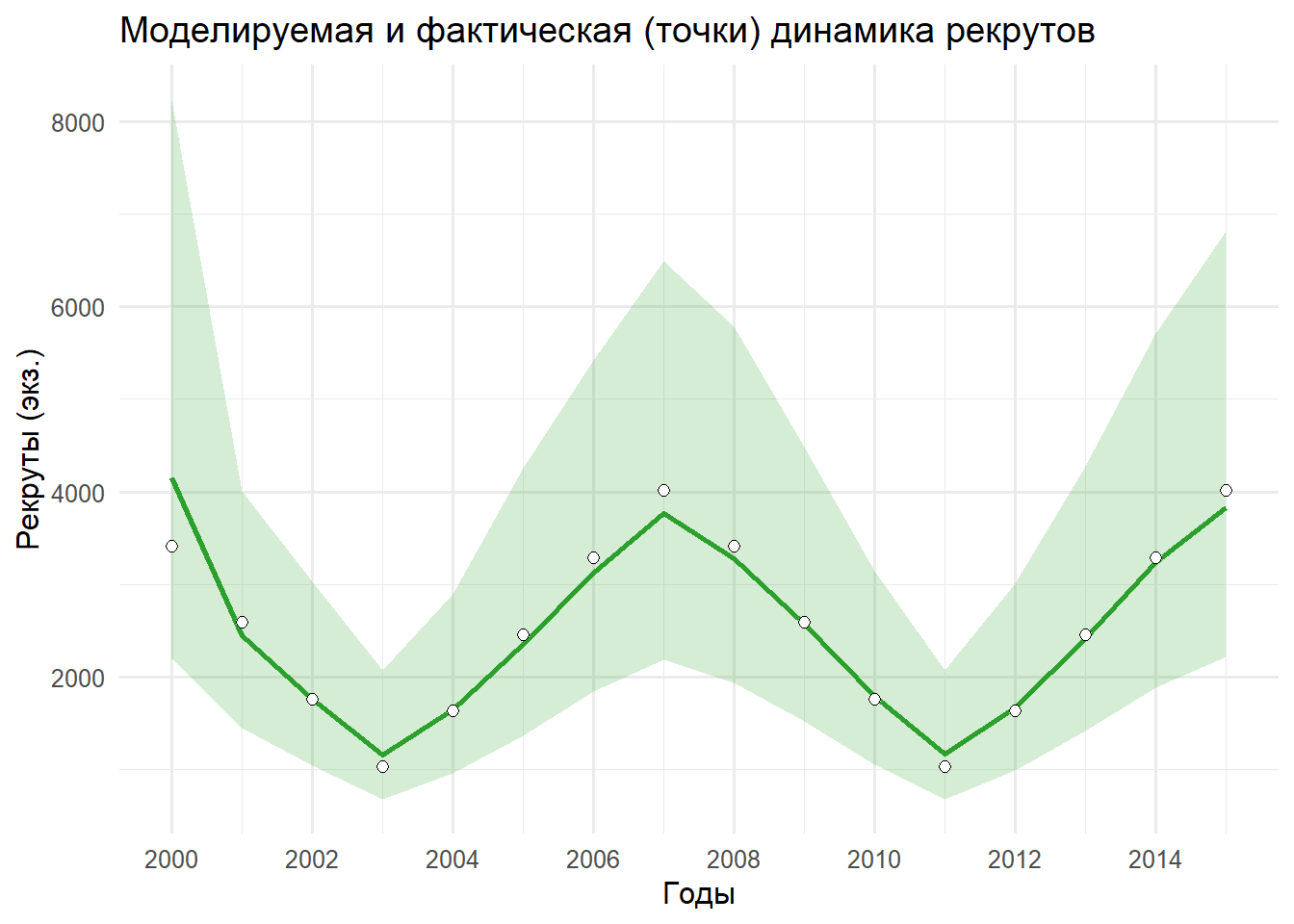
p_R <-ggplot(df_r, aes(x = YEAR)) +geom_ribbon(aes(ymin = lo, ymax = hi), fill ="#2ca02c", alpha =0.2) +geom_line(aes(y = median), color ="#2ca02c", linewidth =1) +geom_point(aes(y = obs), shape =21, size =2, color ="black", fill ="white", na.rm =TRUE) +scale_x_continuous(breaks =seq(2000, 2015, by =2), limits =c(2000, 2015)) +labs(title ="Моделируемая и фактическая (точки) динамика рекрутов", x ="Годы", y ="Рекруты (экз.)") +theme_minimal(base_size =12)print(p_R)
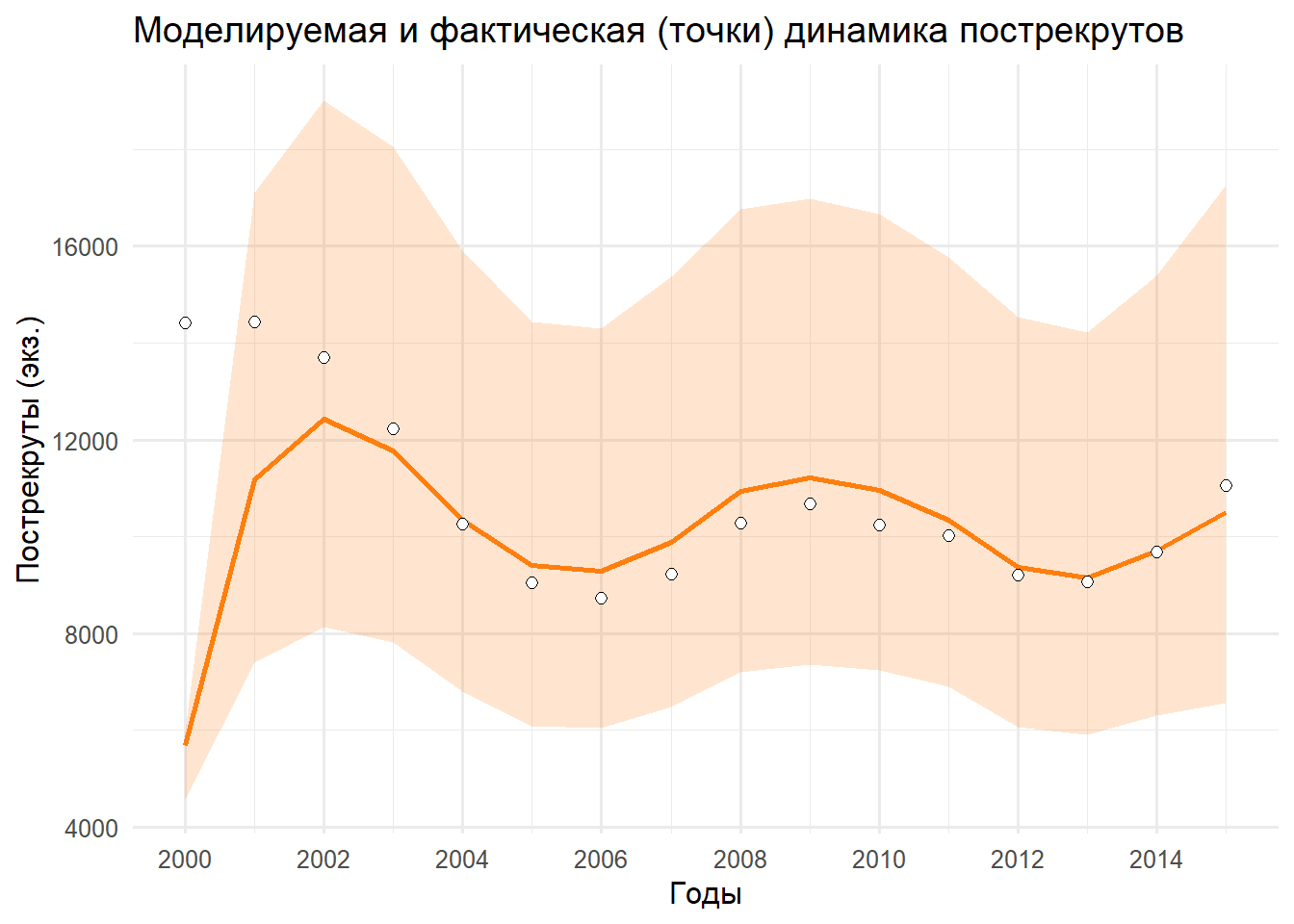
p_P <-ggplot(df_p, aes(x = YEAR)) +geom_ribbon(aes(ymin = lo, ymax = hi), fill ="#ff7f0e", alpha =0.2) +geom_line(aes(y = median), color ="#ff7f0e", linewidth =1) +geom_point(aes(y = obs), shape =21, size =2, color ="black", fill ="white", na.rm =TRUE) +scale_x_continuous(breaks =seq(2000, 2015, by =2), limits =c(2000, 2015)) +labs(title ="Моделируемая и фактическая (точки) динамика пострекрутов", x ="Годы", y ="Пострекруты (экз.)") +theme_minimal(base_size =12)print(p_P)