Если смотреть на планирование съёмки из высоты «Космоса» Карла Сагана и «Краткой истории времени» Стивена Хокинга, всё сводится к простой геометрии и неумолимой физике: расстояния складываются, время утекает, а топология района диктует, сколько топлива и суток мы действительно можем себе позволить. Но как только мы возвращаемся к карте, «быстрый» ум спешит дорисовать удобную историю: «расширим полигон — маршрут вырастет вдвое». На практике рост длины маршрута ведёт себя нелинейно, а форма «важнее площади» чаще, чем нам кажется. Это занятие — про то, как дисциплинировать интуицию, превратить картинку в числа и принять решения, которые выдерживают встречу с реальностью.
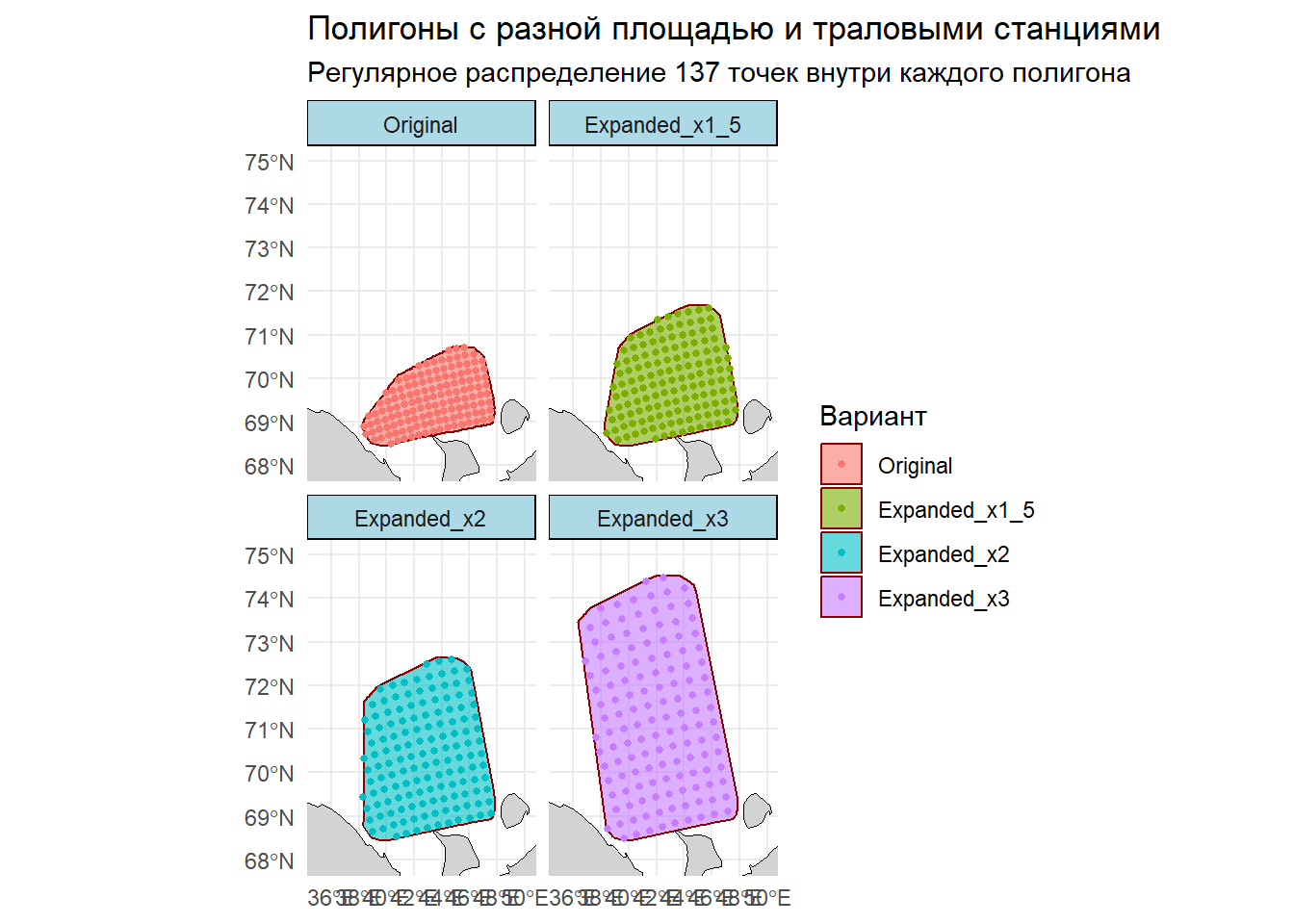
Мы используем минималистичный, но честный инструментариум: переводим исходный полигон в метрическую проекцию UTM, генерируем равномерную сетку станций и решаем задачу коммивояжёра для маршрута судна. Дальше — серия контролируемых экспериментов: асимметрично «растягиваем» полигон к северу (имитируя расширение арктического фронта работ) в 1.5, 2 и 3 раза, каждый раз оставляя одно и то же число станций. Сравниваем площади и оптимальные маршруты. Наша цель проста: понять, насколько дороже становится логистика от изменения площади и формы, когда часы и топливо конечны.
Мы заранее признаём «чёрных лебедей»: погодные окна, запреты и ледовую обстановку скрипт не видит. Но и это хорошая новость — систематический, воспроизводимый подход всё равно делает нас лучше: регулярная оценка маршрутов при разных сценариях снижает долю импровизации и помогает не переплачивать за «красивые» идеи. Здесь важнее не одна точная цифра, а устойчивая картина: где логистика растёт медленнее, чем площадь, а где внезапно «взлетает» из‑за длинной узкой шейки полигона или неудобно расположенных станций.
Эта логистическая «эволюция маршрутов» чем‑то напоминает «Эгоистичный ген» Ричарда Докинза: выживают те траектории, которые экономят ресурс — и не важно, как они появились, важно, что они меньше «едят» времени и топлива. А из «SPQR» Мэри Бирд можно позаимствовать трезвость римских инженеров: дороги строили не по вдохновению, а по задачам снабжения; в море у нас те же дороги, только из линий на карте. Управление — это всегда история, которую мы рассказываем про будущее рейса; хорошая история — та, которая прошла проверку расчётом. И, да, «воля и самоконтроль» здесь не про героизм, а про дисциплину: держать число станций, окна и границы сценариев в рамках, чтобы сравнение было честным.
Чуть техники, но по делу. Мы:
загружаем полигон 2020 года и считаем его площадь в километрах,
строим три северные экспансии (×1.5, ×2, ×3), не симметрично раздувая фигуру, а добавляя «арктический хвост»,
генерируем внутри каждого полигона по 137 регулярных станций — одинаковая «нагрузка» для справедливости сравнения,
решаем TSP с геодезическими расстояниями (Haversine) и фиксируем начало/конец маршрута в самых западных точках — реалистичная постановка для судна, идущего «с запада»,
визуализируем и сводим метрики: площадь и длина маршрута по каждому сценарию.
Что мы хотим увидеть. Во‑первых, нелинейность: умеренное расширение площади иногда почти «бесплатно», а узкая северная протяжка может внезапно удорожить рейс. Во‑вторых, роль формы: два полигона одинаковой площади могут иметь разные «ценники» из‑за геометрии. В‑третьих, смысл «предельной» станции: где последняя добавленная точка дороже всех предыдущих вместе. Это те наблюдения, которые превращают космическую картинку Нила Деграсса Тайсона о «геометрии вселенной» в бытовую навигацию: за изгибами карты стоят очень приземлённые деньги и часы.
Есть и границы. Наш TSP‑эвристик быстрый, но не гарантирует глобальный оптимум; станции расставлены равномерно и не знают про глубины; старт/финиш жёстко заданы; мы не моделируем штормовые задержки и ледовые коридоры. Нам нужны «хорошие объяснения», а не идеально подогнанные: скрипт даёт прозрачную, проверяемую основу для решений и для постановки более сложных задач — со слоями глубин, реальными портами, окнами и альтернативными алгоритмами маршрутизации. А следующий шаг: добавить предиктивные слои (погода/лед) и дать планировщику инструмент «думать наперёд».
И последнее — о масштабе. История учит смотреть на мир одновременно широко и конкретно. Наши полигоны — маленькие кусочки океана, но в них решается вечная задача: как превратить энергию и время в полезные данные с минимальными потерями. Этот скрипт — простой, «большой» по духу метод: он берёт карту, делает из неё информацию и возвращает управленческое решение. Именно такие мосты между картинкой и числом уменьшают долю случайности и, шаг за шагом, ведут к более разумной экспедиции.
И так, этот R-скрипт выполняет геопространственный анализ и моделирование станций исследований в ходе научно-исследовательских съемок.
Основная цель
Скрипт моделирует оптимальные маршруты для станций в разных вариантах исследовательского полигона, чтобы определить, как изменение площади и формы полигона влияет на длину необходимого маршрута. Полный скрипт можно скачать по ссылке.
1. Подготовка данных - Загружается полигон за 2020 год из файла polygons.RData - Полигон преобразуется в систему координат UTM зоны 40N (EPSG:32640) для точных метрических вычислений - Рассчитывается площадь полигона: 63,101.31 км²
2. Моделирование расширенных полигонов Создан алгоритм, который асимметрично расширяет полигон на север (имитируя расширение зоны исследования в арктическом направлении): - expand_polygon_north() определяет северную часть (верхние 30% точек) - Расширяет только эту часть на заданный коэффициент - Создаются 3 варианта: увеличенные на 1.5x, 2x и 3x
3. Генерация траловых станций - Для каждого полигона генерируются 137 равномерно распределенных точек (метод “regular”) - Это имитирует расположение траловых станций в исследовательском полигоне - Количество станций одинаково для всех вариантов полигона
4. Оптимизация маршрутов Ключевая часть скрипта — решение задачи коммивояжера (TSP) для оптимизации маршрута судна: - Начало и конец маршрута фиксируются как две самые западные точки (логично для судна, приходящего с запада) - Используется алгоритм ближайшего включения (nearest_insertion) - Матрица расстояний рассчитывается с помощью distHaversine (точное геодезическое расстояние)
5. Анализ результатов Скрипт рассчитывает и сравнивает: - Площадь каждого полигона- Длину оптимального маршрута для 137 станций
Визуализирует все варианты на карте
Интерпретация результатов
Из сводной таблицы видно, как увеличение площади полигона влияет на длину маршрута:
Вариант
Количество тралений
Длина маршрута (км)
Площадь полигона (км²)
Original
137
3,745
63,101.3
Expanded_x1.5
137
4,076
99,791.0
Expanded_x2
137
4,701
135,352.0
Expanded_x3
137
6,038
207,066.0
Важные наблюдения: 1. При увеличении площади на 57% (до 99,791 км²) длина маршрута возрастает только на 9% (до 4,076 км) 2. При троекратном увеличении площади (до 207,066 км²) длина маршрута возрастает на 61% (до 6,038 км) 3. Это показывает нелинейную зависимость между площадью полигона и длиной маршрута
Практическое применение Этот анализ полезен для: - Планирования гидробиологических исследований в условиях ограниченного бюджета - Оценки дополнительных затрат при расширении зоны исследования - Оптимизации маршрутов научно-исследовательских судов - Моделирования последствий изменения границ охраняемых территорий
Скрипт демонстрирует, как геопространственный анализ и алгоритмы оптимизации могут помочь в принятии решений при планировании полевых исследований водных биоресурсов, особенно в условиях арктических морей, где логистика особенно сложна и дорогостояща.
# ========================================================================================================================# ПРАКТИЧЕСКОЕ ЗАНЯТИЕ: ПЛАНИРОВАНИЕ МАРШРУТА СЪЕМКИ ПРИ ОГРАНИЧЕННОМ ВРЕМЕННОМ РЕСУРСЕ# Курс: "Современные методы анализа данных в оценке водных биоресурсов"# Автор: Баканев С.В.# Дата: 24.04.2025# # Цель: Освоить методы геопространственного анализа и оптимизации для планирования научно-исследовательских съемок# # Структура:# 1. Загрузка пакетов и настройка среды# 2. Загрузка и подготовка исходных данных# 3. Создание расширенных полигонов# 4. Генерация схемы станций# 5. Построение оптимальных маршрутов# 6. Визуализация результатов# 7. Сравнительный анализ и экспорт результатов# # Описание: Скрипт демонстрирует подход к планированию морских исследований с использованием# методов пространственного анализа и решения задачи коммивояжера (TSP).# Моделируются различные сценарии расширения района работ с оценкой# их влияния на протяженность маршрута.# ========================================================================================================================# ЗАГРУЗКА НЕОБХОДИМЫХ ПАКЕТОВ -----------------------------------------------# Все пакеты должны быть предварительно установлены (install.packages(...))library(sf) # Базовые операции с пространственными данными (вектор)
Linking to GEOS 3.13.1, GDAL 3.11.0, PROJ 9.6.0; sf_use_s2() is TRUE
library(tidyverse) # Метасборка пакетов для обработки и визуализации данных
-- Attaching core tidyverse packages ------------------------ tidyverse 2.0.0 --
v dplyr 1.1.4 v readr 2.1.5
v forcats 1.0.0 v stringr 1.5.2
v ggplot2 4.0.0 v tibble 3.2.1
v lubridate 1.9.4 v tidyr 1.3.1
v purrr 1.0.4
-- Conflicts ------------------------------------------ tidyverse_conflicts() --
x dplyr::filter() masks stats::filter()
x dplyr::lag() masks stats::lag()
i Use the conflicted package (<http://conflicted.r-lib.org/>) to force all conflicts to become errors
library(rnaturalearth) # Загрузка готовых полигональных карт мира (для фона)library(ggplot2) # Создание продвинутых графиков (входит в tidyverse, но подключаем для ясности)library(geosphere) # Геодезические расчеты на сфере (расчет расстояний между точками)library(TSP) # Решение "Задачи коммивояжера" (Traveling Salesman Problem)# 1. НАСТРОЙКА СРЕДЫ ----------------------------------------------------------# Установка рабочей директории (замените на путь к своей папке)setwd("C:/SURVEY/")# 2. ЗАГРУЗКА ИСХОДНЫХ ДАННЫХ -------------------------------------------------# Загрузка предварительно созданного файла с полигонамиload("polygons.RData")# Фильтрация полигона за 2020 год и извлечение его геометрииpolygon_2020 <- polygons %>%filter(YEAR ==2020) %>%st_geometry()# 3. ПРЕОБРАЗОВАНИЕ СИСТЕМЫ КООРДИНАТ -----------------------------------------# Преобразование из географических координат (WGS84) в проекцию UTM (зона 40N).# Это необходимо для корректного вычисления площадей и расстояний в метрах.polygon_2020_utm <-st_transform(polygon_2020, 32640)# 4. РАСЧЕТ ПЛОЩАДИ ИСХОДНОГО ПОЛИГОНА ----------------------------------------# Вычисление площади в кв. метрах (st_area) и конвертация в кв. километры (/ 1e6)area_km2_original <- (st_area(polygon_2020_utm) /1e6) %>%as.numeric()# Вывод результата в консольcat("Площадь полигона 2020 года: ", round(area_km2_original, 2), " км²\n")
Площадь полигона 2020 года: 63101.31 км<U+00B2>
# 5. ФУНКЦИЯ ДЛЯ ЭКСПАНСИИ ПОЛИГОНА НА СЕВЕР -----------------------------------# Создание функции, которая "растягивает" северную часть полигона на заданный множитель.# Аргументы:# poly - исходный полигон (в UTM)# factor - коэффициент расширения (например, 1.5 - увеличить на 50%)expand_polygon_north <-function(poly, factor) {# Извлечение координат вершин полигона и преобразование в DataFrame coords <-st_coordinates(poly)[, 1:2] %>%as.data.frame() %>%rename(x = X, y = Y)# ЛОГИКА РАСШИРЕНИЯ:# 1. Определяем "северную" часть полигона (верхние 30% точек по оси Y) north_threshold <-quantile(coords$y, 0.7)# 2. Находим общий разброс полигона по оси Y (высоту) y_range <-diff(range(coords$y))# 3. Сдвигаем все северные точки на север на величину (factor - 1) * высоту_полигона coords[coords$y >= north_threshold, "y"] <- coords[coords$y >= north_threshold, "y"] + y_range * (factor -1)# Создание нового полигона из модифицированных точек:# 1. Преобразование точек в spatial object# 2. Объединение точек в один объект# 3. Построение выпуклой оболочки для получения гладкого полигона expanded_poly <-st_as_sf(coords, coords =c("x", "y"), crs =st_crs(poly)) %>%st_combine() %>%st_convex_hull()return(expanded_poly)}# 6. СОЗДАНИЕ НАБОРА ЭКСПАНДИРОВАННЫХ ПОЛИГОНОВ -------------------------------# Применение функции к коэффициентам 1.5, 2 и 3factors <-c(1.5, 2, 3)expanded_polygons <-map(factors, ~expand_polygon_north(polygon_2020_utm, .x))# 7. РАСЧЕТ ПЛОЩАДЕЙ НОВЫХ ПОЛИГОНОВ ------------------------------------------areas_expanded <-map_dbl(expanded_polygons, ~ { (st_area(.x) /1e6) %>%as.numeric() # Площадь в кв. км.})# 8. ФОРМИРОВАНИЕ ЕДИНОЙ ТАБЛИЦЫ С ВСЕМИ ПОЛИГОНАМИ ---------------------------# Создание именованного списка всех полигоновall_polygons <-list(Original = polygon_2020_utm,Expanded_x1_5 = expanded_polygons[[1]],Expanded_x2 = expanded_polygons[[2]],Expanded_x3 = expanded_polygons[[3]])# Вектор меток и площадейlabels <-c("Original", "Expanded_x1_5", "Expanded_x2", "Expanded_x3")areas <-c(area_km2_original, areas_expanded)# Комбинирование геометрий и создание итогового SF-объектаgeometry <-do.call(c, all_polygons) # Объединение геометрий в один векторpolygon_df <-tibble(label =factor(labels, levels = labels), # Метка как фактор для сохранения порядкаarea_km2 = areas, # Площадьgeometry =st_sfc(geometry) # Геометрия) %>%st_as_sf() # Преобразование в пространственный объект# 9. ГЕНЕРАЦИЯ СЕТКИ ТОЧЕК (СТАНЦИЙ) ВНУТРИ КАЖДОГО ПОЛИГОНА -----------------# Генерация 137 точек по регулярной сетке внутри каждого полигона.# Используется rowwise для применения функции к каждой строке-полигону.sample_points <- polygon_df %>%rowwise() %>%mutate(points =list(st_sample(geometry, size =137, type ="regular"))) %>%ungroup()# 10. СОЗДАНИЕ ЕДИНОЙ ТАБЛИЦЫ ВСЕХ ТОЧЕК --------------------------------------# Преобразование вложенного списка точек в плоскую таблицуpoints_list <-map2(sample_points$geometry, sample_points$label, ~ {st_sample(.x, size =137, type ="regular") %>%# Извлечение точекst_as_sf() %>%# Конвертация в SFmutate(label = .y) # Добавление метки полигона})# Объединение всех точек в один DataFramepoints_df <-do.call(rbind, points_list) %>%rename(geometry = x) %>%st_set_geometry("geometry") %>%st_set_crs(st_crs(polygon_2020_utm)) # Важно: явно задаем систему координат# 11. ПРЕОБРАЗОВАНИЕ В WGS84 ДЛЯ ВИЗУАЛИЗАЦИИ И РАСЧЕТОВ ----------------------# Большинство картографических пакетов и функций расчета расстояний работают с WGS84polygon_wgs84 <-st_transform(polygon_df, 4326) # WGS84 (широта/долгота)points_wgs84 <-st_transform(points_df, 4326)# 12. ЗАГРУЗКА ФОНОВОЙ КАРТЫ (ГРАНИЦЫ РОССИИ) ---------------------------------russia <-ne_countries(scale ="medium", country ="Russia", returnclass ="sf") %>%st_transform(4326) # Преобразование в WGS84# 13. ВИЗУАЛИЗАЦИЯ: ПОЛИГОНЫ И ТОЧКИ ------------------------------------------# Построение карты с фацетами (subplots) для каждого варианта полигонаggplot() +geom_sf(data = russia, fill ="lightgray", color ="black", linewidth =0.3) +# Фонgeom_sf(data = polygon_wgs84, aes(fill = label), alpha =0.6, color ="darkred", linewidth =0.5) +# Полигоныgeom_sf(data = points_wgs84, aes(color = label), shape =16, size =1) +# Точкиfacet_wrap(~ label, scales ="fixed") +# Фацеты по варианту полигонаcoord_sf(xlim =c(35, 50), ylim =c(68, 75)) +# Обрезка карты до нужного регионаlabs(title ="Полигоны с разной площадью и траловыми станциями",subtitle ="Регулярное распределение 137 точек внутри каждого полигона",fill ="Вариант", color ="Вариант" ) +theme_minimal() +theme(strip.background =element_rect(fill ="lightblue"))
# 14. ФУНКЦИЯ ДЛЯ ПОСТРОЕНИЯ ОПТИМАЛЬНОГО МАРШРУТА (TSP) ----------------------# Создает маршрут, проходящий через все точки, с фиксацией начала и конца.create_route <-function(points) {# Извлечение координат (долгота, широта) из SF-объекта coords <-st_coordinates(points)# СТРАТЕГИЯ: Начало и конец маршрута - две самые западные точки.# Это имитирует выход судна из порта и возврат в него. west_points <-order(coords[,1])[1:2] # Индексы двух точек с min долготой# Расчет матрицы расстояний между всеми точками (в метрах) dist_matrix <-distm(coords, fun = distHaversine)# СОЗДАНИЕ И НАСТРОЙКА ЗАДАЧИ KОММИВОЯЖЕРА (TSP): tsp <-TSP(dist_matrix /1000) # Создание объекта TSP (расстояния в км) atsp <-as.ATSP(tsp) # Преобразование в Asymmetric TSP# ФИКСАЦИЯ НАЧАЛА И КОНЦА:# Обнуляем расстояния ДО стартовой точки -> она станет первой. atsp[, west_points[1]] <-0# Обнуляем расстояния ОТ конечной точки -> она станет последней. atsp[west_points[2], ] <-0# РЕШЕНИЕ TSP: метод "Ближайшая вставка" (быстрый, но не всегда оптимальный) tour <-solve_TSP(atsp, method ="nearest_insertion")# ФОРМИРОВАНИЕ ПОСЛЕДОВАТЕЛЬНОСТИ ТОЧЕК МАРШРУТА:# Начало -> Маршрут -> Конец. unique() убирает возможные дубликаты. ordered_indices <-c(west_points[1], as.integer(tour), west_points[2]) ordered_indices <-unique(ordered_indices)return(ordered_indices)}# 15. ПОСТРОЕНИЕ МАРШРУТОВ ДЛЯ КАЖДОГО ПОЛИГОНА -------------------------------# Применение функции create_route к каждой группе точекroutes <- points_wgs84 %>%group_by(label) %>%# Группировка по варианту полигонаgroup_modify(~ { ids <-create_route(.x) # Получение упорядоченного списка индексов точек# Соединение точек в линию (маршрут) route_line <-st_combine(.x$geometry[ids]) %>%st_cast("LINESTRING") # Явное указание типа геометрииtibble(geometry =st_sfc(route_line, crs =4326)) # Возврат маршрута }) %>%st_as_sf() # Преобразование результата в SF-объект# 16. ВИЗУАЛИЗАЦИЯ: ПОЛИГОНЫ, ТОЧКИ И МАРШРУТЫ --------------------------------ggplot() +geom_sf(data = russia, fill ="lightgray", color ="black", linewidth =0.3) +geom_sf(data = polygon_wgs84, aes(fill = label), alpha =0.6, linewidth =0.5) +geom_sf(data = points_wgs84, aes(color = label), shape =16, size =1) +geom_sf(data = routes, color ="darkblue", linewidth =0.8) +# Маршрутыfacet_wrap(~ label, scales ="fixed") +coord_sf(xlim =c(35, 50), ylim =c(68, 74.5)) +labs(title ="Полигоны с оптимальными маршрутами",subtitle ="Начало и конец маршрута - две самые западные точки",fill ="Вариант", color ="Вариант" ) +theme_minimal() +theme(strip.background =element_rect(fill ="lightblue"))
# 17. СОХРАНЕНИЕ КАРТЫ В ФАЙЛ -------------------------------------------------ggsave("polygon_with_optimal_routes.png", width =12, height =10, dpi =300)# 18. СОХРАНЕНИЕ ДАННЫХ МАРШРУТОВ (Ошибка: файл уже существует) ---------------# st_write(routes, "optimal_routes.gpkg") # Раскомментируйте и используйте append=FALSE для перезаписи# st_write(routes, "optimal_routes.gpkg", append=FALSE)# 19. ФИНАЛЬНЫЙ СРАВНИТЕЛЬНЫЙ АНАЛИЗ ------------------------------------------# Создание сводной таблицы с ключевыми метриками для каждого сценарияsurvey_summary <- routes %>%# Добавление данных о площади из таблицы полигоновleft_join(st_drop_geometry(polygon_wgs84), by ="label") %>%mutate(`Количество тралений`=137, # Константа по условию задачи# Расчет длины маршрута: st_length(geometry) возвращает длину в метрах, делим на 1000 для перевода в км.`Длина маршрута (км)`=round(as.numeric(st_length(geometry)) /1000, 1),`Площадь полигона (км2)`=round(area_km2, 1) ) %>%select( # Выбор и переименование колонок для итоговой таблицы Вариант = label,`Количество тралений`,`Длина маршрута (км)`,`Площадь полигона (км2)` )# 20. ВЫВОД ИТОГОВОЙ ТАБЛИЦЫ В КОНСОЛЬ ----------------------------------------cat("\nСводная статистика по вариантам:\n")
Сводная статистика по вариантам:
print(survey_summary)
Simple feature collection with 4 features and 4 fields
Geometry type: LINESTRING
Dimension: XY
Bounding box: xmin: 36.70383 ymin: 68.46426 xmax: 47.67176 ymax: 74.47698
Geodetic CRS: WGS 84
# A tibble: 4 x 5
# Groups: Вариант [4]
Вариант `Количество тралений` `Длина маршрута (км)` Площадь полигона (км~1
<fct> <dbl> <dbl> <dbl>
1 Original 137 3481 63101.
2 Expanded_x~ 137 4375. 99791.
3 Expanded_x2 137 5084. 135352.
4 Expanded_x3 137 6406. 207066.
# i abbreviated name: 1: `Площадь полигона (км2)`
# i 1 more variable: geometry <LINESTRING [arc_degree]>