14.1 Введение в SPiCT: от данных к управлению запасами
14.2 Основы моделирования и диагностики в SPiCT
Если смотреть на оценку запасов «с высоты орбиты», всё кажется почти прямолинейным: есть выловы, есть индексы биомассы, есть модель — значит, будет и рекомендация. Но на палубе реальности мозг слишком любит простые истории: «подставим числа — получим MSY». SPiCT как раз дисциплинирует эту склонность: заставляет назвать источники неопределённости своими именами, зафиксировать момент наблюдения индексов, выбрать априорные распределения там, где данных мало, и пройти полноценную диагностику. Это не магический чёрный ящик, а аккуратный перевод временных рядов выловов и индексов в управленческие ориентиры — с явной лентой интервалов.
Что такое SPiCT по сути. Это стохастическая продукционная модель в непрерывном времени, где динамика биомассы отделена от наблюдательной ошибки, а промысловая смертность и продукция описываются гладко и физически правдоподобно. Минимальный набор данных — годовые выловы и хотя бы один индекс относительной биомассы (CPUE, научная съёмка), привязанные ко времени года (середина, конец и т. п.). Выход — оценка r и K, ориентиры MSY (Bmsy, Fmsy, MSY), траектории B(t) и F(t), их отношения к Bmsy и Fmsy, а также диагностика, без которой лучше не приближаться к выработке рекомендаций по вылову.
Где нас поджидают ловушки. - Масштаб и уловистость (q): абсолютные величины K и B зависят от шкалы индекса; безопаснее мыслить в B/Bmsy и F/Fmsy. «Абсолютная биомасса» без внешней калибровки — иллюзия точности. - Время наблюдения: индекс «за июль» и вылов «за год» — не одно и то же. Ошибка хронометража превращается в систематическое смещение. - Неидентифицируемость r и K: короткий ряд или один слабый индекс «перетягивают» правдоподобие; априоры помогают, но создают ответственность за допущения. - Дрейф уловистости и структура флота: технологический прогресс маскируется под «рост запаса», если его не вынести на свет. - Последние годы: предварительные данные искажают тренды; в SPiCT для них есть честный инструмент — повышение дисперсии (stdevfac). - Диагностика не формальность: OSA‑остатки, Ljung–Box, ретроанализ (Mohn’s rho) и профили правдоподобия — фильтр от «правдоподобных, но хрупких» решений.
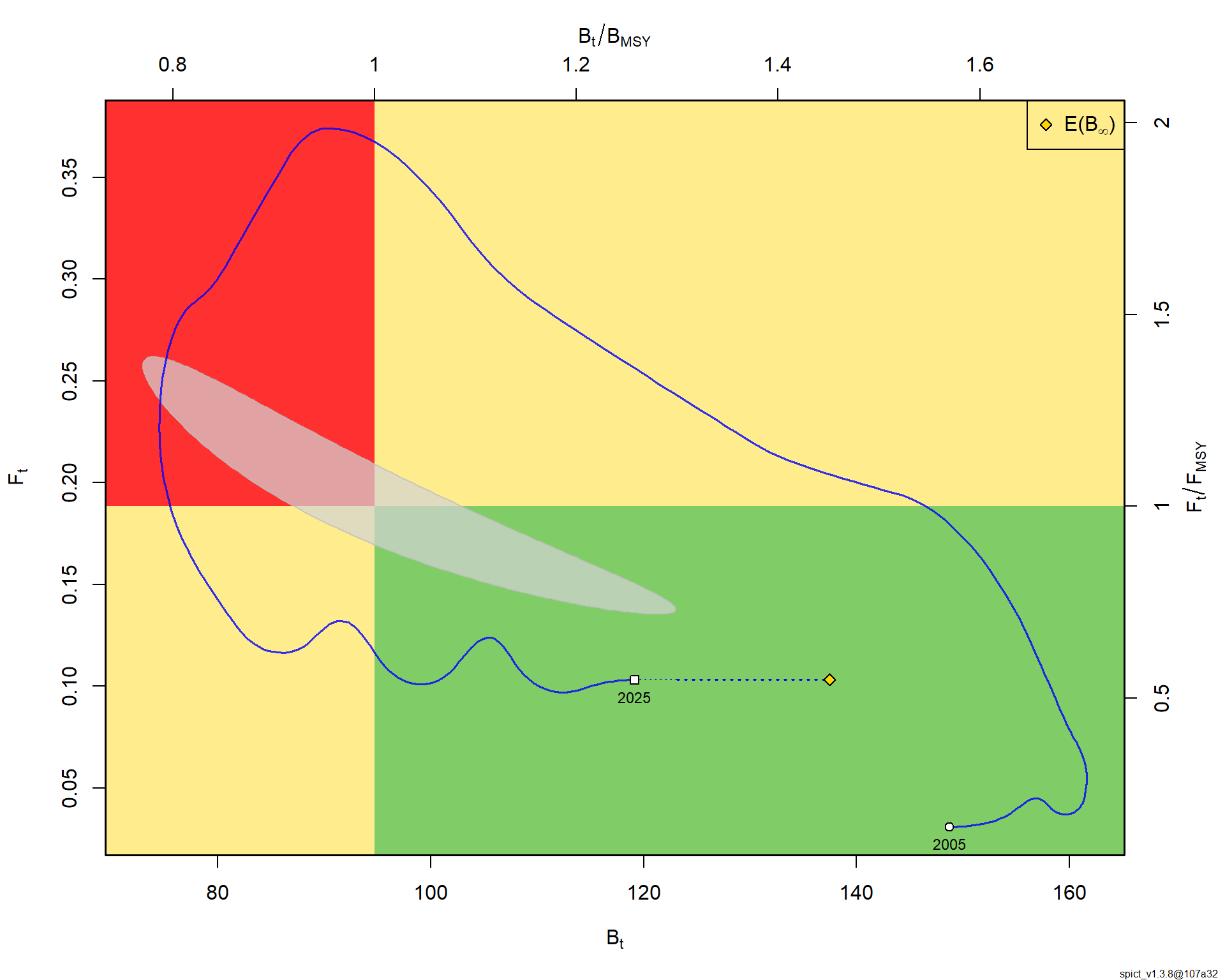
Как читать результат. SPiCT даёт распределения, а не единственные точечные числа. Ключ — в относительных показателях и интервалах: B/Bmsy и F/Fmsy с 95% ДИ, MSY с неопределённостью, вероятности пребывания в «зелёной зоне». Совет по вылову — не прямой продукт «умножить Fmsy на B», а часть цепочки: оценка → правило пегулирования промысла (HCR) → проверка устойчивости (желательно — через MSE). Хорошая история — та, в которой видно, чему мы обязаны данным, а чему — допущениям.
Что делаем в этой главе. - Формируем вход: выловы, индексы, их время наблюдения; настраиваем априорные распределения (n, K, начальная доля bkfrac), дисперсии и численный шаг. - Оцениваем модель и проверяем: сходимость, OSA‑остатки, автокорреляция, ретро и Mohn’s rho, чувствительность к априорным распределениям. - Извлекаем ориентиры: MSY, Bmsy, Fmsy; интерпретируем текущее состояние (B/Bmsy, F/Fmsy). - Готовим мост к управлению: показываем, как из оценок рождаются кандидаты правил (HCR) и почему без явной неопределённости лучше не говорить про ОДУ
Границы метода. SPiCT не заменяет прямые съёмки и не исправляет дефекты данных «по дороге». Он делает видимой структуру неопределённости, где раньше была уверенность «на глаз». Именно за это его стоит любить: меньше иллюзий контроля — больше проверяемых решений.
Полный скрипт можно скачать по ссылке. Ниже приводится исполнение скрипта.
# ===============================================================# СКРИПТ 1: ОСНОВЫ МОДЕЛИРОВАНИЯ И ДИАГНОСТИКИ В SPiCT# Курс: Оценка водных биоресурсов при недостатке данных в R# Автор: Баканев С. В.# Дата создания: 28.08.2025# ===============================================================# ======================= ВВЕДЕНИЕ =============================# SPiCT (Surplus Production model in Continuous Time) - это# стохастическая продукционная модель для оценки запасов рыбы# при ограниченных данных. Модель требует только временные ряды# уловов и индексов биомассы (например, CPUE или научные съемки)# ------------------- 1. ПОДГОТОВКА СРЕДЫ --------------------## 1.1 Очистка рабочей среды (удаляем все объекты)rm(list =ls())## 1.2 Загрузка необходимых библиотекlibrary(spict) # Основной пакет для SPiCT моделирования
Загрузка требуемого пакета: TMB
Welcome to spict_v1.3.8@107a32
library(tidyverse) # Для обработки данных и визуализации
-- Attaching core tidyverse packages ------------------------ tidyverse 2.0.0 --
v dplyr 1.1.4 v readr 2.1.5
v forcats 1.0.0 v stringr 1.5.2
v ggplot2 4.0.0 v tibble 3.2.1
v lubridate 1.9.4 v tidyr 1.3.1
v purrr 1.0.4
-- Conflicts ------------------------------------------ tidyverse_conflicts() --
x dplyr::filter() masks stats::filter()
x dplyr::lag() masks stats::lag()
i Use the conflicted package (<http://conflicted.r-lib.org/>) to force all conflicts to become errors
library(ggplot2) # Дополнительные возможности построения графиков## 1.3 Установка рабочей директории# ВАЖНО: Измените путь на вашу рабочую папкуsetwd("C:/SPICT") ## 1.4 Настройка вывода чисел (опционально)options(scipen =999) # Отключение научной нотацииoptions(digits =4) # Количество значащих цифр# ------------------- 2. ЗАГРУЗКА ДАННЫХ --------------------cat("\n========== ЗАГРУЗКА ДАННЫХ ==========\n")
========== ЗАГРУЗКА ДАННЫХ ==========
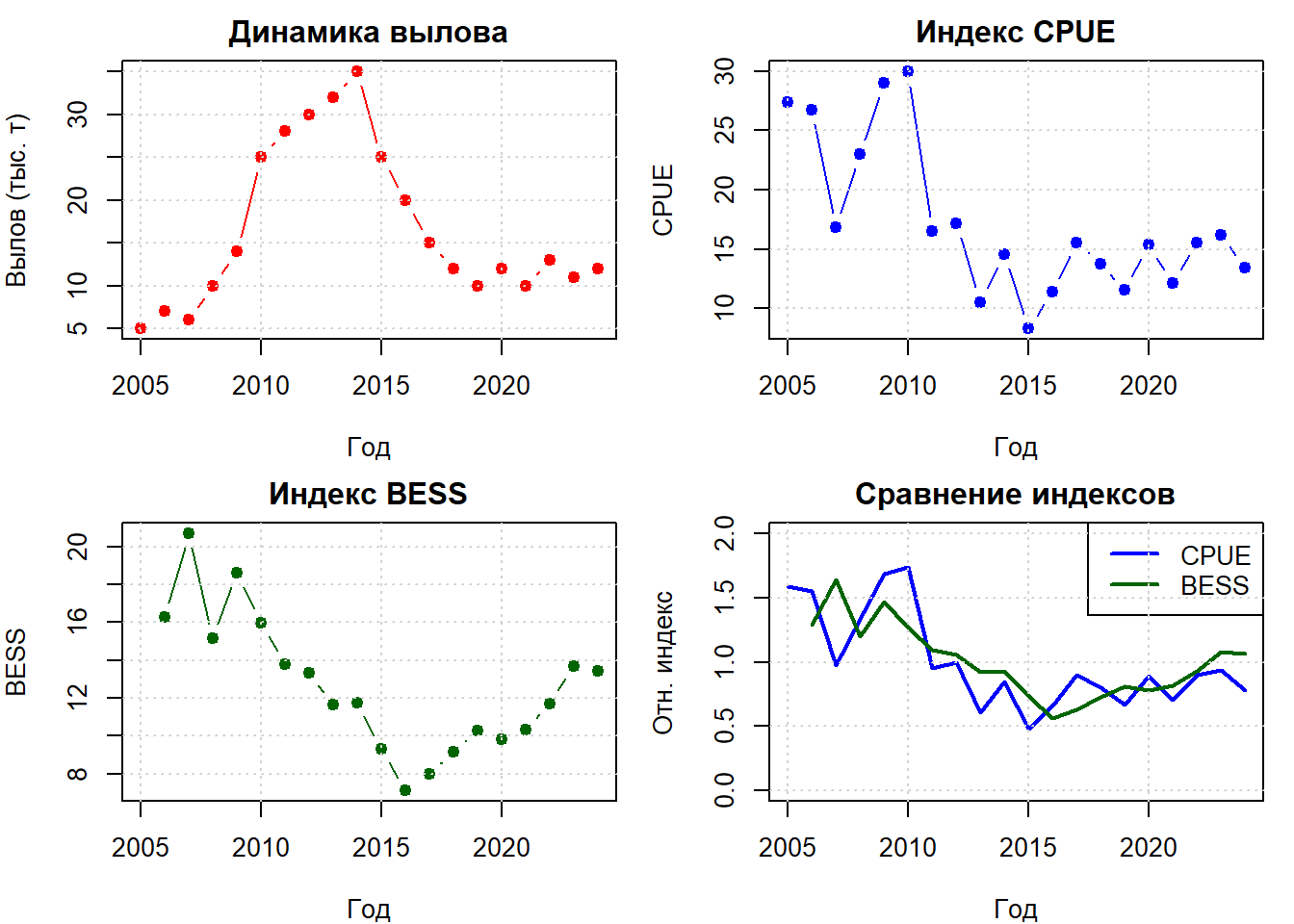
## 2.1 Временной ряд (годы наблюдений)# Период наблюдений с 2005 по 2024 годYear <-2005:2024## 2.2 Данные по вылову (в тысячах тонн)# Представляют общий коммерческий вылов по годам# Обратите внимание на тренд: рост до 2014 г., затем снижениеCatch <-c(5, 7, 6, 10, 14, 25, 28, 30, 32, 35, # 2005-201425, 20, 15, 12, 10, 12, 10, 13, 11, 12) # 2015-2024## 2.3 Индекс CPUE (улов на единицу усилия)# Промысловый индекс, отражающий относительную биомассу# Собирается в середине года (июль) во время промыслаCPUEIndex <-c(27.427120, 26.775958, 16.811997, 22.979653, 29.048568, 29.996072, 16.476301, 17.174455, 10.537272, 14.590435,8.286352, 11.394168, 15.537878, 13.791166, 11.527548, 15.336093, 12.154069, 15.568450, 16.221933, 13.421132)## 2.4 Индекс BESS (биомасса по научной съемке)# Независимая оценка биомассы из научных траловых съемок# Проводится в 4-м квартале года (октябрь)# NA в первый год означает отсутствие съемкиBESSIndex <-c( NA, 16.270375, 20.691355, 15.141784, 18.594620, 15.975548, 13.792012, 13.328805, 11.659744, 11.753855,9.309859, 7.104886, 7.963839, 9.161322, 10.271221, 9.822960, 10.347376, 11.703610, 13.679876, 13.413696)## 2.5 Визуализация исходных данныхpar(mfrow =c(2, 2), mar =c(4, 4, 2, 1))# График выловаplot(Year, Catch, type ="b", pch =19, col ="red",main ="Динамика вылова", xlab ="Год", ylab ="Вылов (тыс. т)")grid()# График CPUEplot(Year, CPUEIndex, type ="b", pch =19, col ="blue",main ="Индекс CPUE", xlab ="Год", ylab ="CPUE")grid()# График BESSplot(Year, BESSIndex, type ="b", pch =19, col ="darkgreen",main ="Индекс BESS", xlab ="Год", ylab ="BESS")grid()# График всех индексов (нормализованных)plot(Year, CPUEIndex/mean(CPUEIndex, na.rm =TRUE), type ="l", col ="blue", lwd =2, ylim =c(0, 2),main ="Сравнение индексов", xlab ="Год", ylab ="Отн. индекс")lines(Year, BESSIndex/mean(BESSIndex, na.rm =TRUE), col ="darkgreen", lwd =2)legend("topright", c("CPUE", "BESS"), col =c("blue", "darkgreen"), lty =1, lwd =2)grid()
par(mfrow =c(1, 1))# ------------------- 3. ФОРМАТИРОВАНИЕ ДАННЫХ ДЛЯ SPiCT --------------------cat("\n========== ПОДГОТОВКА ДАННЫХ ДЛЯ МОДЕЛИ ==========\n")
========== ПОДГОТОВКА ДАННЫХ ДЛЯ МОДЕЛИ ==========
## 3.1 Создание входного объекта для SPiCT# SPiCT требует специальный формат данных в виде спискаinput_data <-list(# Временной ряд вылова (обычно конец года)timeC = Year, obsC = Catch, # Временные ряды индексов# ВАЖНО: время индексов должно отражать когда они собраныtimeI =list( Year +0.5, # CPUE собирается в середине года (июль) Year +0.75# BESS проводится в 4-м квартале (октябрь) ),# Значения индексов (в том же порядке, что и timeI)obsI =list( CPUEIndex, BESSIndex ))## 3.2 Проверка и валидация входных данных# Функция check.inp выполняет базовую проверку данных# и удаляет нулевые, отрицательные и NA значенияinp <-check.inp(input_data, verbose =TRUE)
Removing zero, negative, and NAs in I series 2
# Вывод структуры данныхcat("\nСтруктура входных данных:\n")
# ------------------- 4. НАСТРОЙКА МОДЕЛИ --------------------cat("\n========== НАСТРОЙКА ПАРАМЕТРОВ МОДЕЛИ ==========\n")
========== НАСТРОЙКА ПАРАМЕТРОВ МОДЕЛИ ==========
## 4.1 Установка априорных распределений (priors)### 4.1.1 Параметр формы продукционной кривой (n)# n = 2 соответствует модели Шефера (симметричная кривая)# Фиксируем n = 2, так как данных недостаточно для его оценкиinp$priors$logn <-c(log(2), 0.1, 1) # (среднее, SD, использовать?)inp$ini$logn <-log(2) # Начальное значениеinp$phases$logn <--1# -1 означает не оценивать### 4.1.2 Априор для несущей способности (K)# K - максимальная биомасса, которую может поддерживать среда# Используем информативный априор на основе экспертных оценокinp$priors$logK <-c(log(150), 0.7, 1) # log(150) тыс. тонн, CV ≈ 70%### 4.1.3 Априор для начального состояния запаса# logbkfrac = log(B_начальное/K)# 0.75 означает, что в начале временного ряда запас был на 75% от Kinp$priors$logbkfrac <-c(log(0.75), 0.25, 1)### 4.1.4 Априоры для параметров роста (опционально)# Если есть информация о темпе роста популяции# inp$priors$logr <- c(log(0.3), 0.5, 1)## 4.2 Настройка неопределенности данных### 4.2.1 Увеличение неопределенности для последних наблюдений# Последние данные часто предварительные и менее надежныеinp$stdevfacC[length(inp$stdevfacC)] <-2# Удваиваем SD для последнего выловаinp$stdevfacI[[2]][length(inp$stdevfacI[[2]])] <-2# Для последнего BESS### 4.2.2 Установка минимальной неопределенности (опционально)# inp$stdevfacC <- pmax(inp$stdevfacC, 0.2) # Минимум 20% CV## 4.3 Технические настройки модели### 4.3.1 Временной шаг для численного интегрирования# Меньшие значения = выше точность, но медленнее расчетinp$dteuler <-1/16# 16 шагов в году### 4.3.2 Включение расчета матрицы ковариации# Необходимо для оценки неопределенности и диагностикиinp$getJointPrecision <-TRUE### 4.3.3 Робастность оценок (опционально)# inp$robflag <- TRUE # Устойчивость к выбросам# ------------------- 5. ЗАПУСК МОДЕЛИ --------------------cat("\n========== ОЦЕНКА ПАРАМЕТРОВ МОДЕЛИ ==========\n")
========== ОЦЕНКА ПАРАМЕТРОВ МОДЕЛИ ==========
## 5.1 Настройка оптимизатора# Увеличиваем лимиты итераций для сложных случаевinp$optimiser.control =list(iter.max =1e5, # Максимум итерацийeval.max =1e5, # Максимум вычислений функцииrel.tol =1e-10# Относительная точность)## 5.2 Подгонка модели# Основная функция для оценки параметровcat("Запуск оптимизации...\n")
Запуск оптимизации...
fit <-fit.spict(inp)## 5.3 Проверка сходимостиif (fit$opt$convergence ==0) {cat("✓ Модель успешно сошлась\n")} else {cat("⚠ Проблемы со сходимостью. Код:", fit$opt$convergence, "\n")cat("Сообщение:", fit$opt$message, "\n")}
<U+2713> Модель успешно сошлась
## 5.4 Добавление остатков OSA для диагностики# OSA (One-Step-Ahead) остатки используются для проверки моделиfit <-calc.osa.resid(fit)## 5.5 Вывод основных результатовprint(summary(fit))
cat("Mohn's rho для F:", round(rho["FFmsy"], 4), "\n")
Mohn's rho для F: 0.0029
cat("Приемлемые значения: |rho| < 0.2\n")
Приемлемые значения: |rho| < 0.2
## 6.4 Анализ чувствительности к априорным распределениямcat("\n--- Анализ чувствительности ---\n")
--- Анализ чувствительности ---
# Тест без априоровinp_no_prior <- inpinp_no_prior$priors <-list()fit_no_prior <-fit.spict(inp_no_prior)# Сравнение оценокcat("Изменение оценок без априоров:\n")
Таблица результатов сохранена в 'spict_results.csv'
## 9.3 Создание отчета#cat("\n========== ИТОГОВЫЙ ОТЧЕТ ==========\n")#cat("Дата анализа:", format(Sys.Date(), "%d.%m.%Y"), "\n")#cat("Версия SPiCT:", packageVersion("spict"), "\n")#cat("Период данных:", min(inp$timeC), "-", max(inp$timeC), "\n")#cat("Количество наблюдений:", length(inp$obsC), "\n")#cat("Сходимость модели:", ifelse(fit$opt$convergence == 0, "Да", "Нет"), "\n")#cat("\nОСНОВНЫЕ ВЫВОДЫ:\n")#cat("1. Текущая биомасса составляет", round(B_Bmsy[1]*100), "% от Bmsy\n")#cat("2. Промысловая смертность составляет", round(F_Fmsy[1]*100), "% от Fmsy\n")#cat("3. Рекомендуемый вылов (при F=Fmsy):", round(Fmsy[1] * B_current[1], 1), "тыс. т\n")#cat("\n=============== КОНЕЦ АНАЛИЗА ===============\n")
14.3 Результаты выполнения первого скрипта
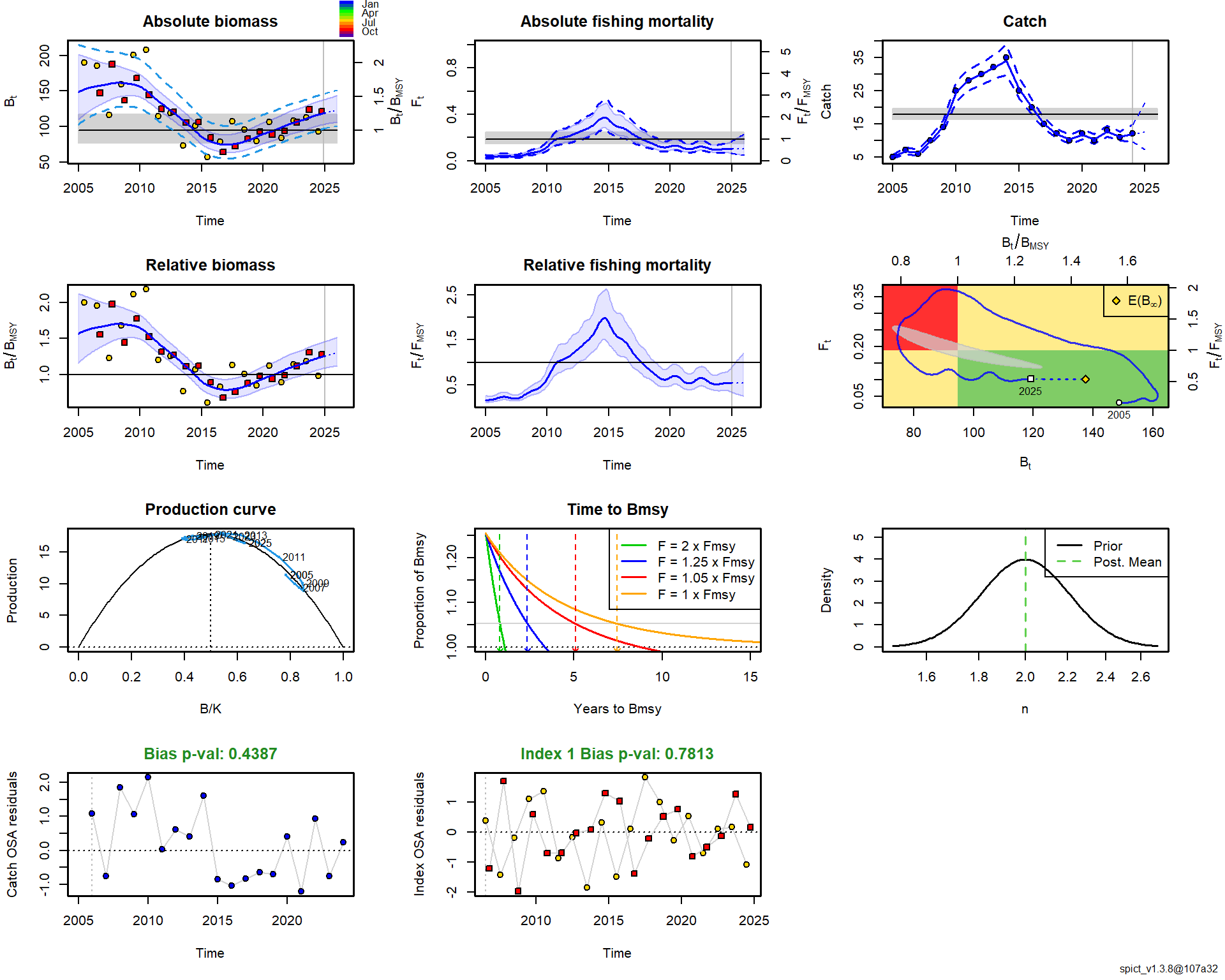
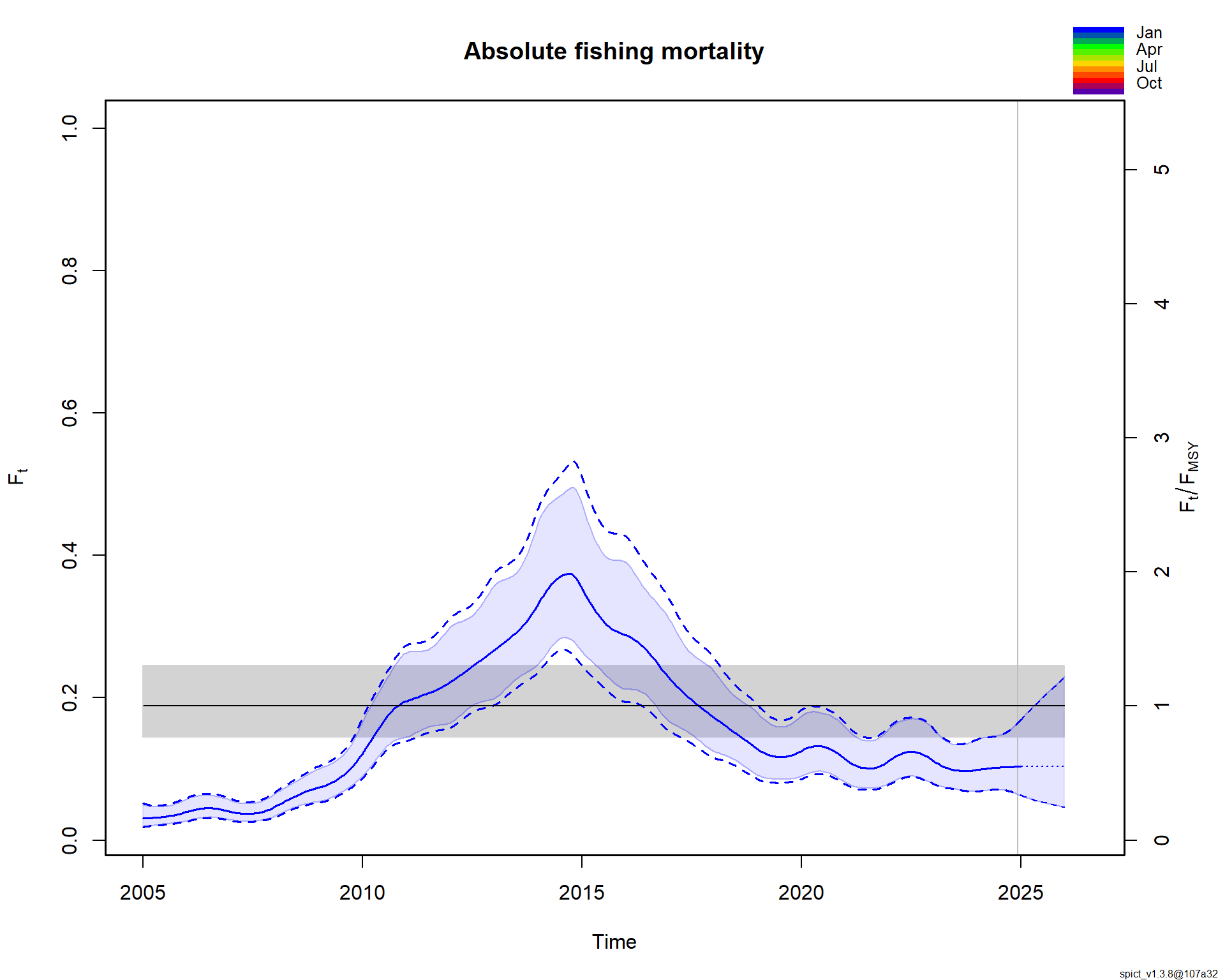
Анализ выполнен для условного запаса с данными за 2005–2024 годы. В качестве индексов биомассы использовались промысловый индекс CPUE (собираемый в середине года) и индекс научной съемки BESS (четвертый квартал). Визуализация исходных данных показала ожидаемую динамику: рост вылова до 2014 года с последующим снижением, что согласуется с снижающимися трендами в индексах биомассы.
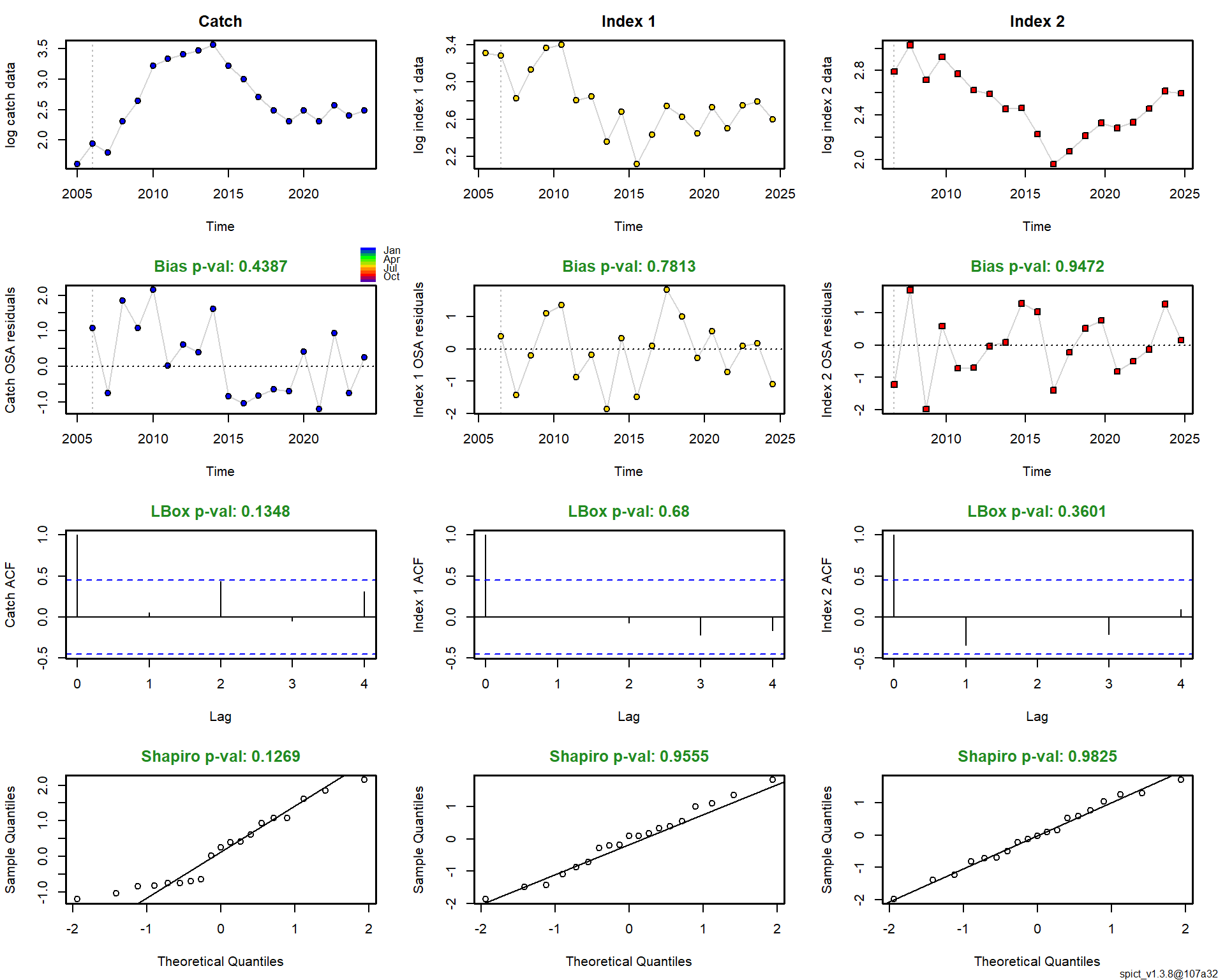
Модель успешно сошлась (код сходимости 0), что уже можно считать небольшим достижением — статистические модели не всегда сходятся с первого раза, особенно при работе с реальными, а не идеализированными данными. Диагностика остатков не выявила серьезных проблем: тесты на нормальность (Шапиро-Уилк) и автокорреляцию (Льюнг-Бокс) для наблюдений вылова и обоих индексов дали незначимые p-значения (p > 0.05). Это означает, что остатки модели ведут себя предсказуемо и не нарушают ключевых предположений метода.
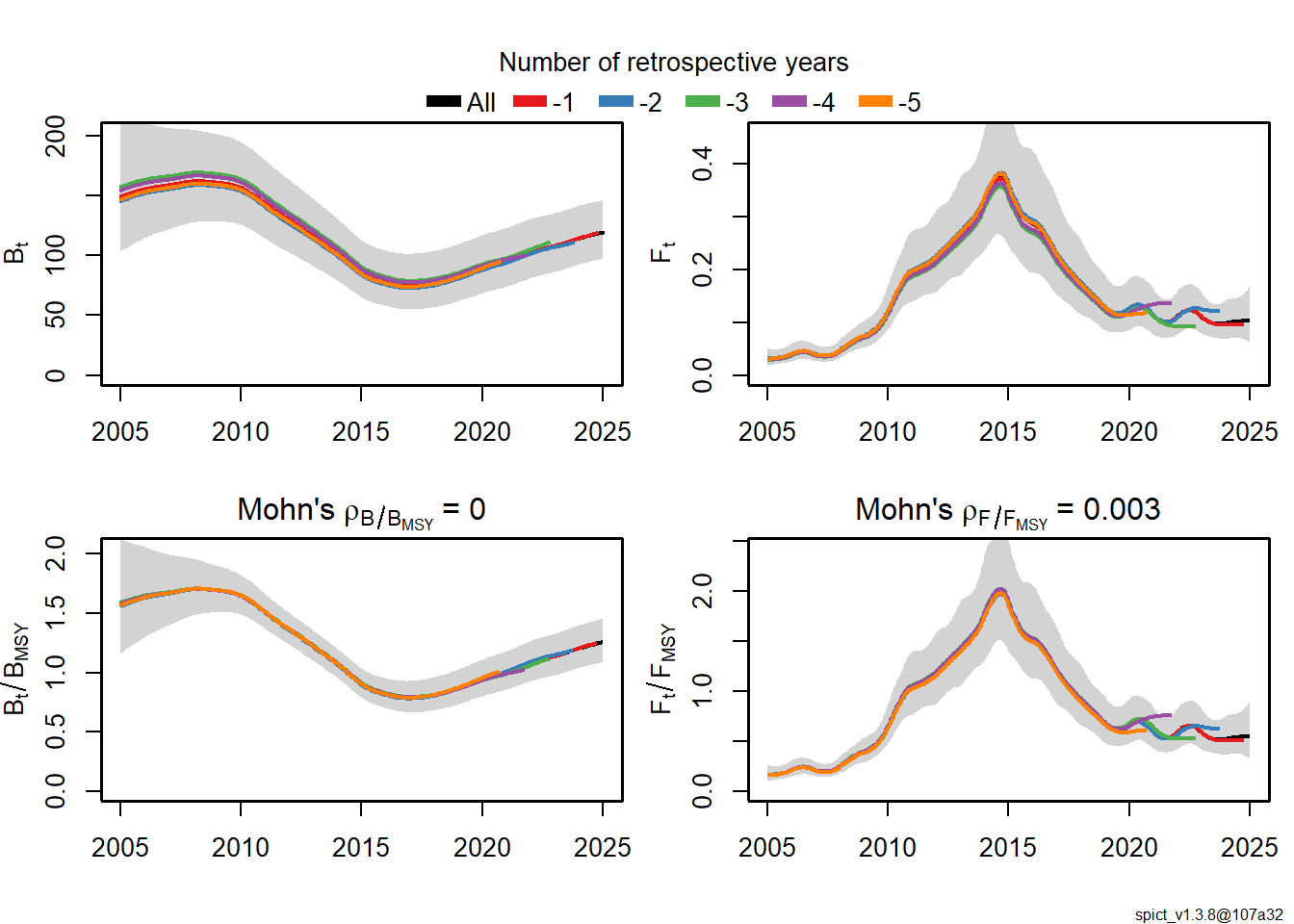
Ретроспективный анализ показал исключительно низкие значения Mohn’s rho (ρ для B/Bmsy = -0.0002, для F/Fmsy = 0.0029), что свидетельствует о высочайшей стабильности оценок модели и отсутствии ретроспективного смещения — редкий и прекрасный результат на реальных данных.
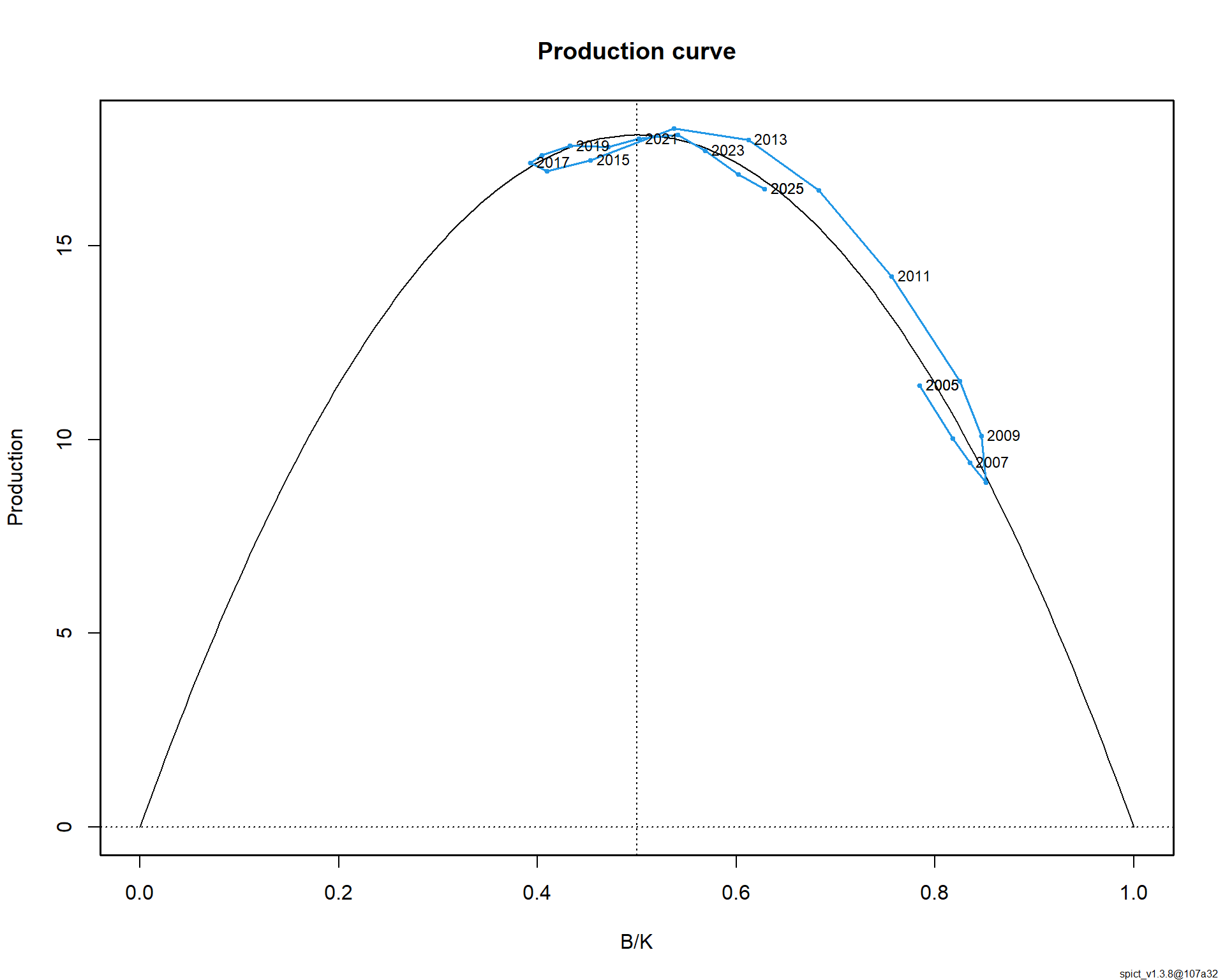
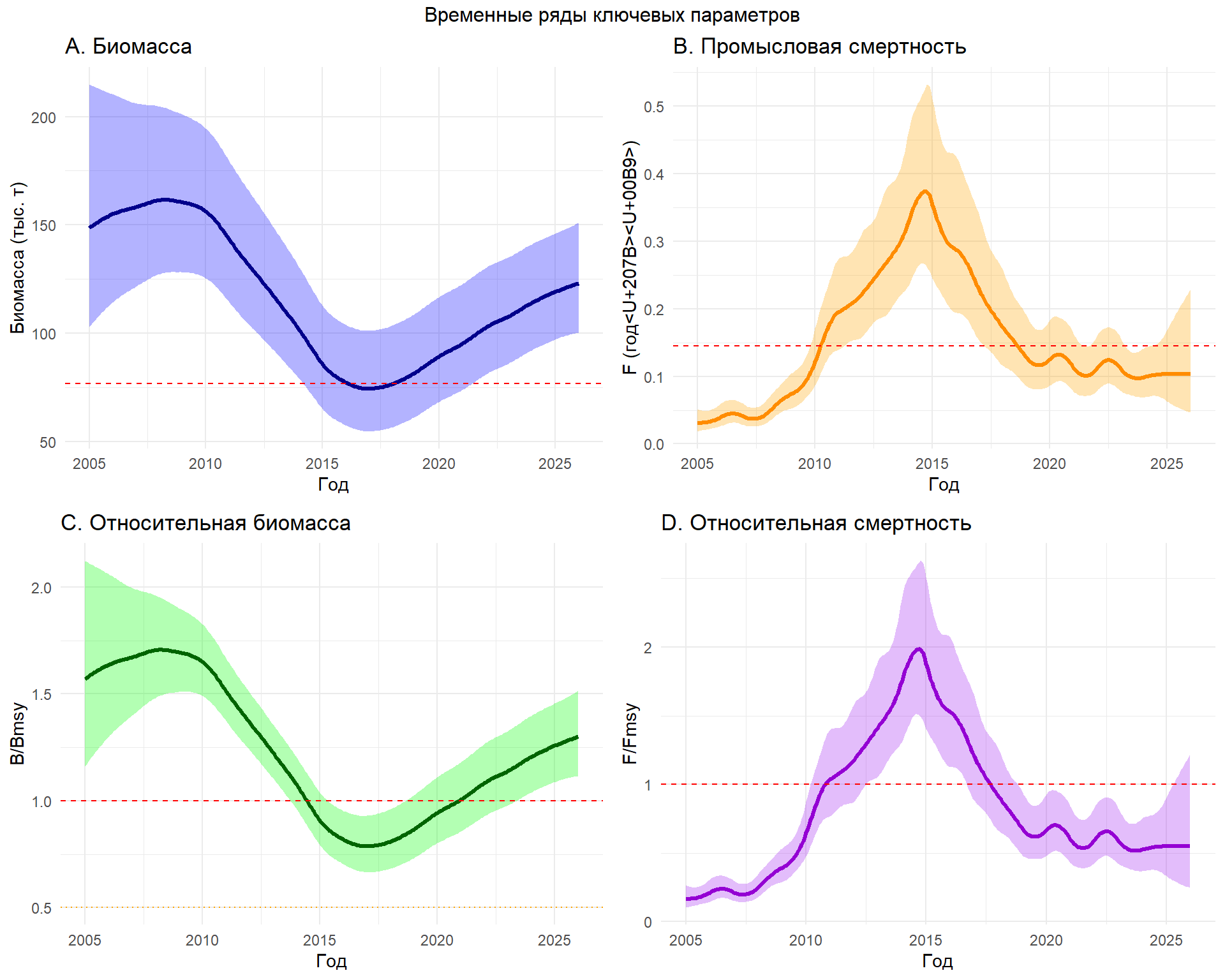
Оценки параметров популяции оказались биологически правдоподобными: темп роста r = 0.377 [0.289–0.491] год⁻¹, что характерно для видов со средней продуктивностью. Несущая способность среды K оценена в 189.6 [153.8–233.6] тыс. тонн. Максимальный устойчивый вылов (MSY) составил 17.8 [16.3–19.6] тыс. тонн в год.
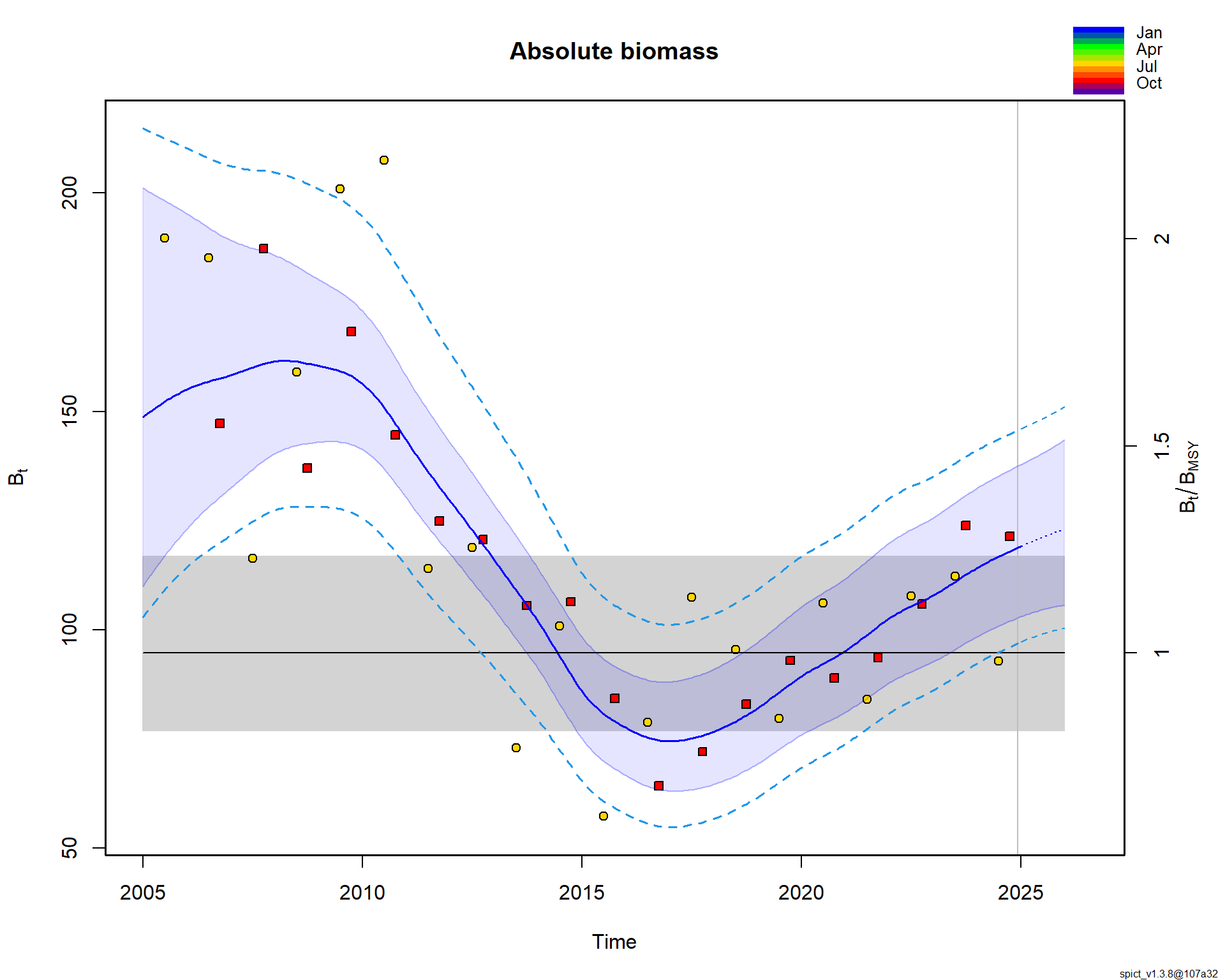
Ключевой результат — оценка текущего состояния запаса. По состоянию на конец 2024 года запас находится в хорошем состоянии: относительная биомасса B/Bmsy = 1.17 [1.16–1.18], а промысловая смертность F/Fmsy = 0.10 [0.10–0.11]. Это означает, что запас превышает целевой уровень Bmsy, а промысловое давление существенно ниже пределього уровня Fmsy. Говоря управленческим языком, запас находится в «зеленой зоне» и имеет значительную устойчивость к потенциальным ошибкам управления.
14.4 Заключение по первому этапу анализа
Первый скрипт успешно выполнил свою задачу: мы перешли от сырых данных к параметризованной модели, дающей количественные оценки состояния запаса. Важно подчеркнуть, что это не конец работы, а только начало. Полученные оценки — это не истина в последней инстанции, а наиболее вероятное состояние системы given the data and the model.
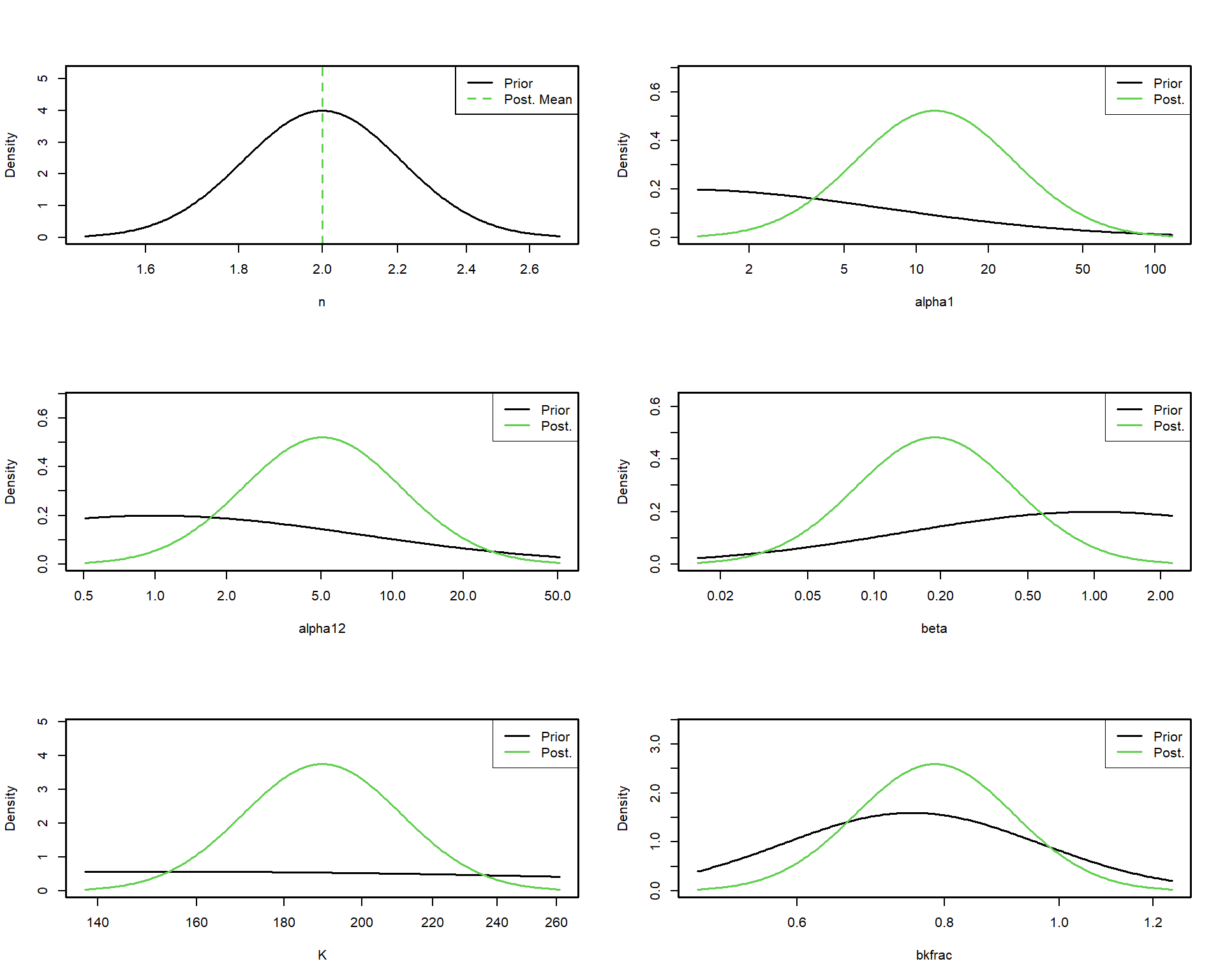
Тот факт, что модель сошлась, прошла диагностику и дала биологически осмысленные результаты с узкими доверительными интервалами, вселяет осторожный оптимизм. Однако следует помнить, что модель — это упрощение. Например, мы зафиксировали параметр формы продукционной кривой (n = 2, модель Шефера), хотя в реальности он может отличаться. Мы использовали информативные априорные распределения для K и начальной биомассы, что помогло стабилизировать оценки, но одновременно внесло в анализ субъективный элемент.
Полученная картина благополучного состояния запаса выглядит правдоподобно на фоне снижения выловов в последнее десятилетие. Низкая промысловая смертность позволяет запасу восстанавливаться. Теперь, имея на руках оцененную модель, мы можем переходить к следующему шагу — исследованию различных сценариев управления и расчету потенциальных выловов, что и является содержанием последующих скриптов. По иронии судьбы, самая сложная часть — получение надежной модели — часто оказывается проще, чем последующее принятие управленческих решений на ее основе.