# ------------------------- 1. ПОДГОТОВКА СРЕДЫ ---------------------------
## 1.1 Установка пакетов (выполнить один раз)
# install.packages("tidyverse")
#remotes::install_github("DTUAqua/spict/spict") # Установка SPiCT
#install.packages("TMB", type="source")
## 1.2 Загрузка библиотек
library(spict) # Основной пакет для моделирования
library(tidyverse) # Для обработки данных и визуализации
## 1.3 Установка рабочей директории
setwd("C:/SPICT") # Укажите вашу рабочую папку
# ------------------------- 2. ЗАГРУЗКА ДАННЫХ ---------------------------
## 2.1 Вектор лет наблюдений
Year <- 2005:2024
## 2.2 Данные по вылову (тыс. тонн)
Catch <- c(5, 7, 6, 10, 14, 25, 28, 30, 32, 35, 25, 20, 15, 12, 10, 12, 10, 13, 11, 12)
## 2.3 Индекс CPUE (промысловый индекс)
CPUEIndex <- c(27.427120, 26.775958, 16.811997, 22.979653, 29.048568, 29.996072, 16.476301,
17.174455, 10.537272, 14.590435, 8.286352, 11.394168, 15.537878, 13.791166,
11.527548, 15.336093, 12.154069, 15.568450, 16.221933, 13.421132)
## 2.4 Индекс BESS (научная съемка)
BESSIndex <- c( NA, 16.270375, 20.691355, 15.141784, 18.594620, 15.975548, 13.792012,
13.328805, 11.659744, 11.753855, 9.309859, 7.104886, 7.963839, 9.161322,
10.271221, 9.822960, 10.347376, 11.703610, 13.679876, 13.413696)6 Продукционная модель SPiCT
6.1 Введение
Вводное занятие по SPiCT’у, которое основано на рекомендованом к изучению обзоре, составленным разработчиками библиотеки. Однако в этом репозитории (см.боковую вкладку оглавления) есть еще триптих скриптов, посвященных SPiCT’у, включающих отдельную оценку ОДУ, ПРП и MSE (оценки стратегии управления). Перед этим занятием должна читаться лекции о продукционном и байесовском подходах в рыбохозяйственной науке, но пока я их не выложил в сеть. Может позже, а может и нет… И так, далее лирическое введение…
Это практическое занятие — приглашение работать с неопределённостью без иллюзий и профессионально. Мы будем оценивать запас промыслового вида с помощью SPiCT — стохастической продукционной модели в байесовской постановке. В терминах Даниэля Канемана: мы осознанно переводим себя из «быстрой» Системы 1 (интуиции и красивых историй) в «медленную» Систему 2 (проверяемые допущения, прайеры, диагностика, сценарии).
Зачем SPiCT и почему именно такой подход. SPiCT реализует стохастическую динамику продукционной модели (обобщение Шефера/Пеллы–Томлинсона) и оценивает параметры с помощью библиотеки TMB* в байесовской парадигме (см. Байесовский подход). Это важно по трём причинам. Во‑первых, реальный улов и индексы шумные, иногда с нулями, с передисперсией; стохастическая модель учитывает процессные и наблюдательные ошибки, а не прячет их в остатки. Во‑вторых, байесовские прайеры (или прайеры) — не «псевдонаучные пожелания», а протокол того, что мы готовы считать правдоподобным до данных: n≈2 (Шефер), разумный диапазон K, начальная доля B/K. Прайеры делают оценку стабильной при слабых данных и позволяют явно «рассказать» модели, что мы знаем из биологии. В‑третьих, пакет построен вокруг воспроизводимой диагностики: OSA‑остатки, автокорреляция, сравнение априор/апостериор, ретроспектива (коэффициент Мона), сценарии управления — это инструменты, уменьшающие риск когнитивных ловушек.
Про объективные допущения и минимализм. «Простые» объяснения предпочтительнее при прочих равных, пока они работают. Мы не перегружаем модель лишними степенями свободы: фиксируем n=2, задаём информативные прайеры на K и начальную долю B/K, аккуратно масштабируем неопределённость последних лет (не наделяя «свежие» данные ролью окончательных вердиктов), используем малый шаг интегрирования dteuler для корректной динамики. Ричард Докинз сказал бы: эволюция — это про ограничения и компромиссы; продукционная модель — тоже. Она не объясняет всё, но хорошо решает задачу «сколько можем брать и оставаться в зелёной зоне» при ограниченной информации.
Как держать под контролем наши ошибки мышления. Ведь мозг любит «истории с концом», даже если данных мало. Мы противопоставляем этому протокол. Сначала — валидируем входные ряды (вылов и индексы, лаги и кросс‑корреляции), затем — формируем единый вход SPiCT с явным календарём измерений (timeI и obsI), задаём прайеры и повышаем неопределённость там, где это необходимо (последние годы). Дальше — диагностика: OSA‑остатки без смещения и избыточной автокорреляции, нормальность на QQ‑плотах, сравнение прайеров и апостериорныз распределений (данные «говорят», или всё держится на прайере?), корреляции параметров (типичная антагония K и q — не баг, а свойство задачи), ретроспектива Мона (устойчивость оценок к добавлению новых лет). Это «канемановская» дисциплина: мы строим защитные барьеры от своей уверенности.
Про риск и «толстые хвосты». Напомним, что средние — коварны. Даже если B/BMSY>1 и F/FMSY<1, управленческие правила должны учитывать ширину доверительных интервалов, а не только точку. Поэтому мы интерпретируем не одну кривую, а пучок сценариев ПРП (правил регулирования промысла): «держать текущий вылов», «держать текущий F», «ловить на FMSY», «снизить/увеличить F», «хоккейная клюшка», «ICES‑правило», фиксированные квоты. И для каждого — не только прогноз B и F, но и риск превышения FMSY и ухода ниже BMSY. Хорошая рекомендация — это баланс «надёжности» и «пользы»: консервативный вылов, сохраняющий B/BMSY>1.2 при низкой вероятности перелова, часто выигрывает у агрессивных схем, которые «в среднем» немного выгоднее, но делают систему хрупкой.
Как читать результаты и не обмануться. Сходимость (convergence=0) и конечные стандартные ошибки — допуск к интерпретации. OSA‑диагностика без смещения и лишней автокорреляции — индикатор адекватности структуры ошибок. Разумный K (с учётом прайера), r в биологическом диапазоне, q1–q2 сопоставимые для индексов CPUE и BESS — признак «реалистичности». Если апостериор на K почти совпадает с прайером — не беда, это честный сигнал: данных мало, рекомендацию стоит «страховать» широкой лентой доверительного интервала и консервативным сценарием. Если ковариации параметров велики — не прячем, а подчёркиваем в выводах. Если ретроспектива показывает |ρ| близко к нулю — модель устойчива; если нет — упрощаем, усиливаем прайеры, перепроверяем данные.
Про «матчасть» и воспроизводимость. SPiCT — это не только fit.spict(), а экосистема справок (?check.inp, ?fit.spict), кратких обзоров и живого «технического» руководства. Мы сохраняем код, версии пакетов, начальные значения и прайеры внутри скрипта — так, чтобы завтра любой исследователь смог повторить наши оценки. Это и есть “антихрупкость” : система, которая выигрывает от проверок и критики. И это способ строить доверие в сообществе — не за счёт красноречия, а за счёт прозрачности.
Что вы освоите по итогам занятия. 1) Подготовку входных данных: единая шкала времени, лаги индексов, кросс‑корреляции. 2) Настройку прайеров и их роль при ограниченных данных. 3) Запуск и диагностику модели: от конвергенции до OSA и ретроспективы. 4) Чтение ключевых ориентиров (MSY, BMSY, FMSY, B/BMSY, F/FMSY) и их неопределённости. 5) Формирование и интерпретацию сценариев управления с учётом риска, а не только «лучшей точки». 6) Коммуникацию результатов для управленцев: одна картинка Кобе-график (Kobe plot), одна таблица сценариев, одна короткая формулировка рекомендации с оговорками и предпосылками.
И главное — стиль мышления. Мы будем вспоминать Сапольского, когда захочется превратить «красивую» картинку в факт; Канемана — когда рука потянется «довернуть» модель до нужного ответа; Талеба — когда нужно выбирать между «чуть больше сейчас» и «устойчиво много лет»; Хокинга — когда стоит убрать лишнюю сложность; Докинза — когда интерпретируем параметры через процессы; Харари — когда формируем честный и открытый нарратив о том, что модель знает и чего не знает. Такой образ действий превращает SPiCT из «чёрного ящика» в дисциплину: воспроизводимый, устойчивый и полезный для принятия решений анализ.
И так, библиотека SPiCT https://github.com/DTUAqua/spict - оценка запаса с помощью стохастической версии продукционной модели и байесовского подхода. Доступен краткий обзор пакета здесь, который служит для ознакомления с пакетом и его функционалом. В обзоре также содержится описание более продвинутых функций пакета.
Документ с техническими рекомендациями по использованию SPiCT доступен здесь . Это постоянно обновляемый документ.
Пакет также содержит достаточно подробную документацию в виде справочных текстов, связанных с каждой функцией (некоторые из них могут быть не полностью актуальны). Доступ к ним можно получить обычным для R способом, набрав, например ?check.inp, . Для начала (помимо изучения краткого обзора) рекомендуется прочитать ?check.inpи ?fit.spict.
* - TMB (Template Model Builder)— это специализированный пакет для языка R, предназначенный для эффективной оценки параметров сложных нелинейных статистических моделей, часто используемых в экологии и fisheries science. Он позволяет реализовать байесовский вывод, автоматически вычисляя производные и правдоподобие для сложных моделей, что значительно ускоряет расчёты и делает возможной работу с многомерными задачами, такими как оценка запасов с помощью SPiCT.
6.2 Установка пакетов и Загрузка данных
Полный скрипт находится по ссылке
6.3 Кросс-корреляции с временным лагом между индексами и уловами
# График кросс-корреляции: Catch и BESSindex (только данные без пропусков)
ccf(na.omit(Catch), na.omit(BESSIndex),
main = "Кросс-корреляция: Уловы и BESSindex",
xlab = "Лаг (годы)", ylab = "Корреляция")
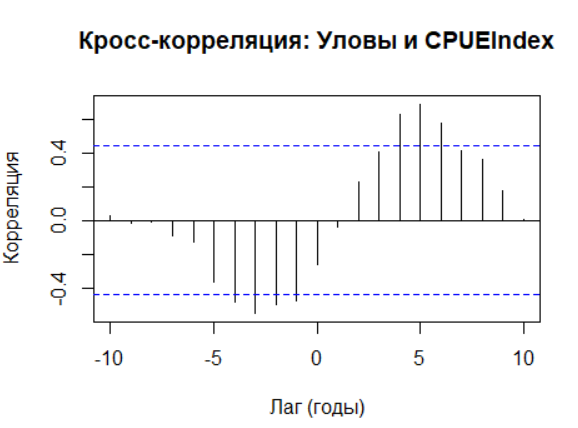
# График кросс-корреляции: Catch и CPUEIndex (только данные без пропусков)
ccf(na.omit(Catch), na.omit(CPUEIndex),
main = "Кросс-корреляция: Уловы и CPUEIndex",
xlab = "Лаг (годы)", ylab = "Корреляция")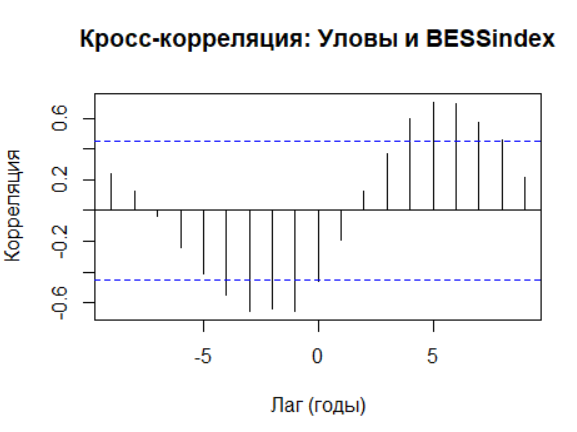
6.4 Подготовка данных для SPiCT
## 3.1 Форматирование данных в список SPiCT
input_new <- list(
timeC = Year, # Годы вылова
obsC = Catch, # Значения вылова
timeI = list( # Временные точки для индексов:
Year + 0.5, # CPUE - середина года (июль)
Year + 0.75 # BESS - 3/4 года (октябрь)
),
obsI = list(
CPUEIndex, # Значения индекса CPUE
BESSIndex # Значения индекса BESS
)
)
## 3.2 Проверка и подготовка входных данных
inp <- check.inp(input_new, verbose = TRUE)Функция check.inp() выполняет подготовку и валидацию входных данных перед моделированием. Основные задачи функции:
Проверяет наличие обязательных элементов: timeC (временные точки вылова), obsC (значения вылова). Проверяет соответствие индексов (timeI и obsI): одинаковое количество элементов в списках, соответствие длин временных рядов. Обработка пропущенных значений. Автоматически обрабатывает NA в начале вектора CPUEIndex (2005-2010). Удаляет или маркирует пропущенные значения в соответствии с настройками пакета и пр.
6.5 Настройка модели
# ------------------- 4. НАСТРОЙКА МОДЕЛИ --------------------
## 4.1 Установка априорных распределений
inp$priors$logn <- c(log(2), 0.1, 1) # Прайер для n (модель Шефера)
inp$ini$logn <- log(2) # Начальное значение
inp$phases$logn <- -1 # Фиксируем параметр (не оцениваем)
inp$priors$logK <- c(5, 0.7, 1) # Прайер для емкости среды (K)
inp$priors$logbkfrac <- c(log(0.75),0.25,1) # Начальный уровень эксплуатации
## 4.2 Настройка неопределенности данных
# Повышаем неопределенность для последнего года вылова
inp$stdevfacC[length(inp$stdevfacC)] <- 2
# Повышаем неопределенность для последнего значения BESS
inp$stdevfacI[[2]][length(inp$stdevfacI[[2]])] <- 2
## 4.3 Настройка временного шага
inp$dteuler <- 1/16 # Более точная дискретизация (по умолчанию 1)
## 4.4 Включение оценки ковариации
inp$getJointPrecision <- TRUE # Для оценки случайных эффектовУстановка априорных распределений
inp$priors$logn <- c(log(2), 0.1, 1) inp$ini$logn <- log(2) inp$phases$logn <- -1Прайер для параметра n: Устанавливаем лог-нормальное распределение для экспоненты в продукционном уравнении, фиксируя модель Шефера (n=2).
Начальное значение: Задаем стартовую точку для оптимизации как log(2), что соответствует n=2.
Фиксация параметра: Флаг
-1исключает n из оценки, делая его константой (упрощает модель).Биологический смысл: Обеспечивает реалистичную форму продукционной кривой (параболическую).
inp$priors$logK <- c(5, 0.7, 1)Прайер для ёмкости среды: Задаем лог-нормальное распределение для K.
Параметры: Медиана exp(5)≈148 тыс.т, SD=0.7 в лог-шкале.
Значение 1: Активирует использование прайера в расчетах.
Назначение: Отражает экспертные знания о возможном диапазоне K.
inp$priors$logbkfrac <- c(log(0.75),0.25,1)Приор для начальной биомассы: Определяет распределение для B₀/K.
Параметры: Медиана 0.75 (начальная биомасса 75% от K), SD=0.25.
Биологический смысл: Отражает гипотезу, что запас изначально был близок к неиспользуемому.
Важность: Помогает оценить начальные условия при ограниченных данных.
Настройка неопределенности данных
inp$stdevfacC[length(inp$stdevfacC)] <- 2Цель: Увеличить неопределенность последнего года вылова.
Значение 2: Стандартная ошибка увеличивается вдвое.
Причина: Последние данные часто предварительные или неполные.
Эффект: Снижает влияние потенциально ненадежной точки на оценку запаса.
inp$stdevfacI[[2]][length(inp$stdevfacI[[2]])] <- 2Цель: Повысить неопределенность последнего значения индекса съемки (BESS).
Синтаксис:
[[2]]указывает на второй индекс в списке.Обоснование: Данные съемок могут требовать последующих корректировок.
Результат: Модель становится менее чувствительной к потенциальным аномалиям.
Настройка временного шага
inp$dteuler <- 1/16Цель: Улучшить точность численного интегрирования.
Значение: Шаг расчета ≈23 дня (вместо годового).
Необходимость: Для короткоживущих видов (н-р, креветка) с быстрой динамикой.
Эффект: Точнее учитывает внутригодовые изменения и сезонность.
Цена: Увеличивает время расчета в 3-5 раз.
Включение оценки ковариации
inp$getJointPrecision <- TRUEЦель: Рассчитать полную ковариационную матрицу параметров.
Необходимость: Для корректной оценки неопределенности производных показателей (B/BMSY).
Что делает: Учитывает взаимосвязи между параметрами и скрытыми состояниями.
Преимущество: Более реалистичные доверительные интервалы.
Ограничение: Увеличивает время расчета на 20-30%.
6.6 Визуализация входных данных
# ----------------- 5. ВИЗУАЛИЗАЦИЯ ВХОДНЫХ ДАННЫХ -----------------
## 5.1 Общий график данных
plotspict.data(inp)
plotspict.ci(inp)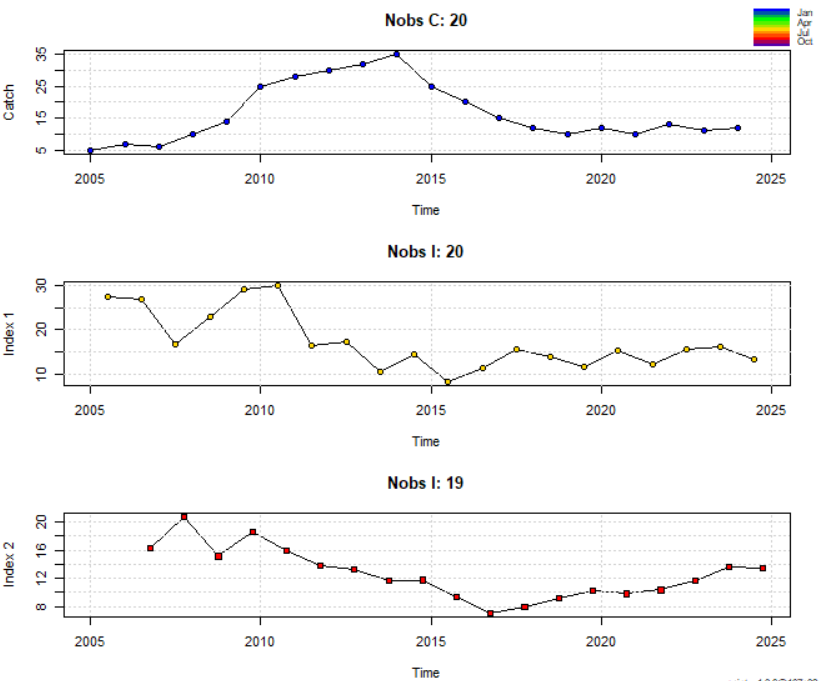
6.7 Запуск модели
# ------------------- 6. ЗАПУСК МОДЕЛИ --------------------
## 6.1 Настройка оптимизатора
inp$optimiser.control = list(iter.max = 1e5, eval.max = 1e5)
## 6.2 Подгонка модели
fit <- fit.spict(inp)
## 6.3 Добавление OSA-остатков
fit <- calc.osa.resid(fit) Настройка оптимизатора
inp$optimiser.control = list(iter.max = 1e5, eval.max = 1e5)Что это делает:
Увеличивает максимальное количество итераций (iter.max) и вычислений (eval.max) для алгоритма оптимизации до 100,000
Обеспечивает, что процесс оптимизации не остановится преждевременно из-за ограничений по умолчанию
Особенно важно для сложных моделей с несколькими индексами или при плохой сходимости
Помогает алгоритму найти глобальный минимум функции правдоподобия
Предотвращает ошибки типа “maximum iterations reached”
Подгонка модели
fit <- fit.spict(inp)Что происходит:
Оценка параметров: Ищет значения параметров (K, r, q и др.), максимизирующие правдоподобие
Интегрирование уравнений: Решает дифференциальные уравнения модели с шагом dteuler
Расчет неопределенности: Оценивает стандартные ошибки через обратную матрицу Гессе
Диагностика сходимости: Проверяет успешность оптимизации (fit$opt$convergence)
Сохраняет результаты: Формирует объект fit со всеми выходами модели
Ключевые процессы:
Численная оптимизация (обычно алгоритм nlminb)
Интегрирование методом Эйлера
Расчет логарифмического правдоподобия
Оценка матрицы Гессе
OSA-остатки
fit <- calc.osa.resid(fit)Что такое OSA-остатки:
One-Step-Ahead residuals - остатки “на один шаг вперед”
Диагностический инструмент: Показывают, насколько хорошо модель предсказывает следующее наблюдение
Расчет: Для каждого года t модель подгоняется по данным до t-1, затем сравнивается предсказание с фактическим значением в t
Что делают:
Обнаружение систематических ошибок: Выявляют смещения в предсказаниях
Проверка независимости: Автокорреляция в остатках указывает на неучтенные зависимости
Оценка распределения ошибок: Проверяют соответствие нормальному распределению
Идентификация выбросов: Помогают найти аномальные точки данных
6.8 Диагностика сходимости
# ----------------- 7. ДИАГНОСТИКА СХОДИМОСТИ -----------------
## 7.1 Проверка сходимости
fit$opt$convergence # 0 = успешная сходимость
## 7.2 Проверка конечных значений
all(is.finite(fit$sd)) # TRUE = все параметры конечныДиагностика сходимости модели SPiCT
Проверка сходимости (7.1)
fit$opt$convergence — индикатор успешности оптимизации. Возвращаемое значение 0 означает, что алгоритм оптимизации успешно сошелся к точке максимума правдоподобия. Это важно, так как гарантирует:
Параметры модели достигли стабильных значений
Градиент функции правдоподобия близок к нулю
Результаты статистически надежны
Модель готова для дальнейшего анализа и прогнозирования
Интерпретация кодов:
0: Успешная сходимость (идеальный результат)
1: Достигнут лимит итераций (требует увеличения iter.max)
10: Дегенерация симплекса (проблемы с данными)
Другие коды указывают на специфические ошибки оптимизации
Проверка конечных значений (7.2)
all(is.finite(fit$sd)) — комплексная проверка корректности оценок неопределенности. Результат TRUE означает:
Все стандартные ошибки параметров являются вещественными числами
Отсутствуют патологические значения (NaN, Inf, NA) в матрице Гессе
Ковариационная матрица положительно определена
Оценки неопределенности надежны для построения доверительных интервалов
Что проверяет:
Корректность расчета стандартных ошибок
Отсутствие вырожденных параметров
Численную стабильность решения
Возможность интерпретировать результаты
Последствия FALSE:
Невозможно построить достоверные доверительные интервалы
Риск ошибочных управленческих рекомендаций
Требуется пересмотр модели (упрощение, изменение прайеров)
6.9 Диагностика модели
# ----------------- 8. ДИАГНОСТИКА МОДЕЛИ -----------------
## 8.1 График остатков
plotspict.osar(fit)
## 8.2 Общая диагностика
plotspict.diagnostic(fit)
## 8.3 Сравнение приоров и апостериорных распределений
plotspict.priors(fit)
## 8.4 Проверка корреляции параметров
cov2cor(fit$cov.fixed) # Матрица корреляций
cov2cor(fit$cov.fixed) > 0.8 # Выявление сильных корреляций (>0.8)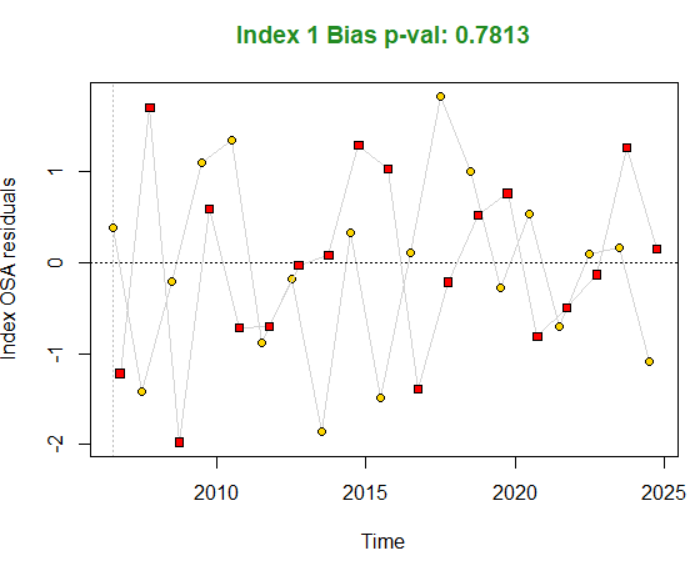
Остатки по времени (Residuals vs. time):
Показывает разницу между наблюдаемыми значениями и предсказаниями модели
Идеал: случайное распределение вокруг нуля
Что означает “Index 1 Bias p-val 0.7813”?
Это результат статистического теста на систематическую ошибку (bias) для первого индекса (в нашем случае - CPUE):
Index 1: Это ваш индекс CPUE (первый в списке индексов)
Bias p-val: p-value теста на наличие систематического смещения
0.7813: Конкретное значение p-value
Интерпретация значения 0.7813:
p-value > 0.05: Нет статистически значимых доказательств систематической ошибки (смещения)
Высокое значение (0.7813): Сильно выше 0.05 → модель не имеет значимого смещения для этого индекса
Практический смысл: Модель адекватно описывает динамику CPUE без постоянного завышения или занижения
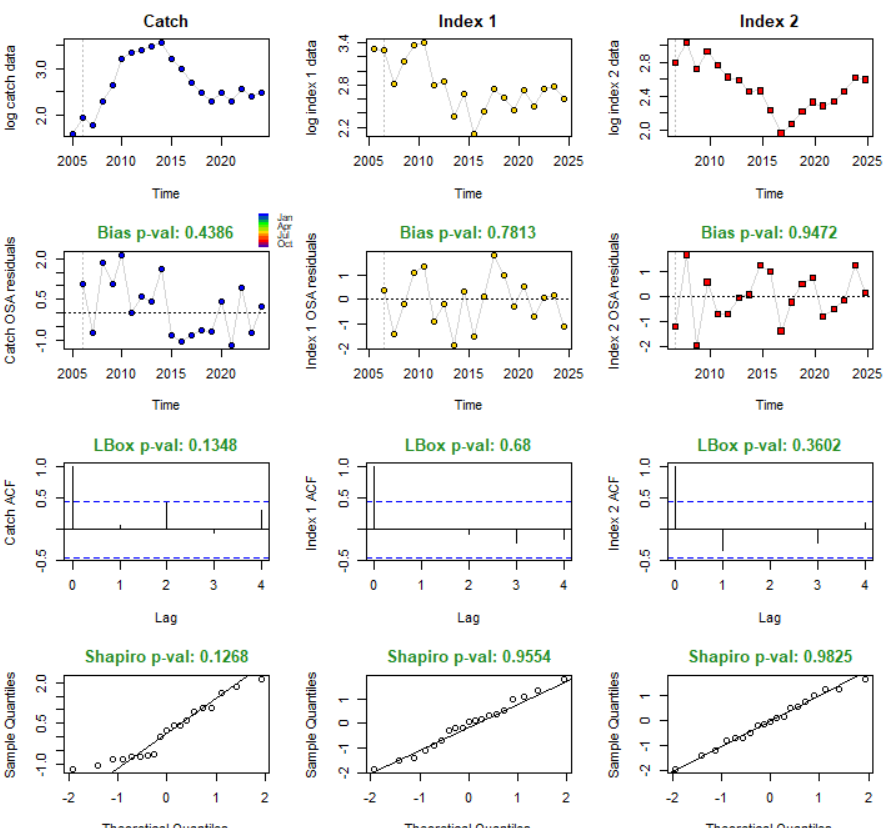
Структура диагностического графика
Первый столбец: Информация, связанная с данными по вылову (catch).
Второй и третий столбцы: Информация, связанная с данными по индексам биомассы.
Строки графика содержат (сверху вниз):
Логарифмы исходных рядов данных:
Верхний левый график в строке:
log catch data(Логарифм данных по вылову).Средний и правый графики в строке:
log index data(Логарифм данных по индексу).Цель: Визуально оценить исходные данные.
OSA-остатки:
График показывает разницу между наблюдаемыми и предсказанными на один шаг вперед значениями (в логарифмической шкале).
Заголовок графика содержит p-значение теста на смещение (bias test). Этот тест проверяет, отличается ли среднее остатков от нуля (систематическая ошибка).
Bias p-val: X.XXXX(p-значение теста на смещение).Зеленый заголовок: Тест НЕ значим (нет свидетельств систематической ошибки, p > 0.05).
Красный заголовок: Тест значим (есть свидетельства систематической ошибки, p <= 0.05).
Три теста незначимы (p=0.4386 для вылова, p=0.7813 и p=0.9472 для индексов), заголовки зеленые.
Эмпирическая автокорреляция остатков (ACF - Autocorrelation Function):
График показывает корреляцию остатков с их собственными лагированными значениями.
Выполняется два теста на значимую автокорреляцию:
Тест Льюнга-Бокса (Ljung-Box test): Одновременный тест для нескольких лагов (здесь 4). Результат:
LBox p-val: X.XXXXв заголовке графика.На примере: Три теста незначимы (p=0.1348 для вылова, p=0.68 и p=0.3602 для индексов).
Тесты для отдельных лагов: Пунктирные горизонтальные линии на графике показывают критические значения для значимой автокорреляции на каждом конкретном лаге. Если столбики автокорреляции (вертикальные линии) выходят за эти пунктирные линии, это свидетельствует о значимой автокорреляции на данном лаге.
На примере : Никаких нарушений (значимой автокорреляции) не выявлено.
Тесты на нормальность остатков:
QQ-график (Quantile-Quantile plot): Сравнивает квантили остатков с квантилями теоретического нормального распределения. Прямая линия указывает на нормальность.
Тест Шапиро-Уилка (Shapiro-Wilk test): Формальный тест на нормальность. Результат:
Shapiro p-val: X.XXXXв заголовке графика.На примере: Три теста незначимы (p=0.1268 для вылова, p=0.9554 и p=0.9825 для индекса), нет свидетельств против нормальности.
Вывод для примера :
Данные в этом примере не показали значимых нарушений предположений модели (нет систематической ошибки, автокорреляции или отклонения от нормальности остатков). Это повышает уверенность в полученных результатах моделирования.
Для обсуждения возможных нарушений и способов их устранения читатель отсылается к Pedersen and Berg (2017) см. https://github.com/DTUAqua/spict/raw/master/spict/inst/doc/spict_handbook.pdf.
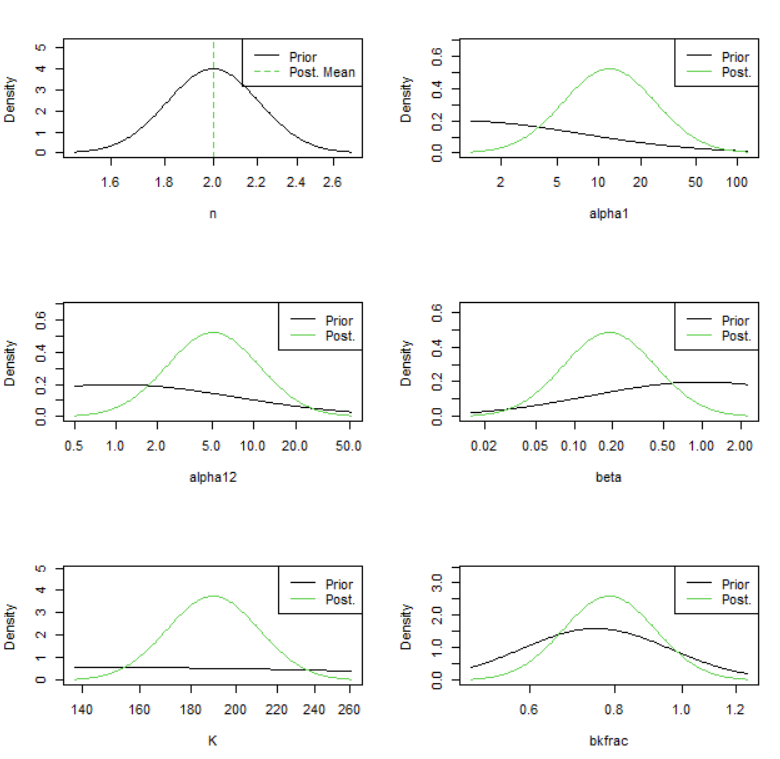
n (параметр формы продукционной функции)
Описание: Определяет форму продукционной кривой (зависимость роста биомассы от самой биомассы).
Интерпретация:
n = 2: Классическая модель Шефера (симметричная кривая, максимум производства приB/K = 0.5).n ≠ 2: Обобщенная модель Пеллы-Томлинсона (асимметричная кривая).
Важность: влияет на оценку
Bmsy(биомасса при MSY) и статус запаса (B/Bmsy).
alpha1, alpha2 (Параметры соотношения шумов для индексов)
Описание: Логарифмы отношений стандартных отклонений ошибок наблюдения индексов (
sdi1,sdi2) к стандартному отклонению процесса биомассы (sdb):
alpha1 = log(sdi1) - log(sdb)
alpha2 = log(sdi2) - log(sdb)Интерпретация:
Отражают относительную точность каждого индекса биомассы по сравнению с изменчивостью самой биомассы.
alpha = 0(sdi = sdb): Шум индекса равен шуму биомассы.alpha < 0(sdi < sdb): Индекс точнее, чем изменчивость биомассы (хорошо).alpha > 0(sdi > sdb): Индекс шумнее, чем изменчивость биомассы (плохо).
Контекст: Появляются, только если в модели используется два или более индексов биомассы.
6.9.0.1 beta (Параметр соотношения шумов для уловов)
Описание: Логарифм отношения стандартного отклонения ошибок наблюдения уловов (
sdc) к стандартному отклонению процесса промысловой смертности (sdf):
beta = log(sdc) - log(sdf)Интерпретация:
Отражает относительную точность данных по уловам по сравнению с изменчивостью промысловой смертности.
beta = 0(sdc = sdf): Шум уловов равен шуму F.beta < 0(sdc < sdf): Данные по уловам точнее, чем изменчивость F (хорошо).beta > 0(sdc > sdf): Данные по уловам шумнее, чем изменчивость F (плохо).
6.9.0.2 K (емкость среды)
Описание: Максимальная равновесная биомасса неэксплуатируемого запаса (carrying capacity).
Интерпретация: Верхняя асимптота кривой роста. Один из самых важных и часто трудных для оценки параметров, особенно при ограниченных данных.
Единицы измерения: Те же, что и у биомассы (например, тонны, тыс. особей).
6.9.0.3 bkfrac (Начальная биомасса)
Описание: Доля от
K, которую составляла биомасса запаса в начальный год временного ряда:
bkfrac = B₀ / KИнтерпретация:
bkfrac = 1: Запас был в нетронутом состоянии в начальный год (B₀ = K).bkfrac < 1: Запас уже был эксплуатируемым к началу ряда данных.
Важность: Сильно влияет на реконструкцию исторической динамики биомассы, особенно если данные начинаются с периода интенсивного промысла.
Почему именно эти параметры?
Функция plotspict.priors(fit) по умолчанию фокусируется на параметрах, для которых:
Заданы явные априорные распределения пользователем (как
logKилиbkfracв примерах).Применены стандартные полу-информативные прайеры SPiCT для стабилизации оценки в условиях ограниченных данных. К ним относятся
n,alpha1,alpha2,beta. SPiCT использует их, так как эти параметры (особенноnи соотношения шумов) часто плохо определяются только данными улова и индекса.
Сравнение прайера и апостериорного распределения показывает:
Насколько данные обновили наши первоначальные (априорные) представления о параметре.
Насколько информативны были априорные распределения.
Надежность оценки: Сильное сужение апостериорного распределения относительно априорного говорит о том, что данные содержат информацию о параметре. Если апостериорное распределение почти совпадает с априорным, данные не добавили новой информации (оценка держится на априорном распределение (прайере)).
6.10 Проверка корреляции параметров
## 8.4 Проверка корреляции параметров
> cov2cor(fit$cov.fixed) # Матрица корреляций
logm logK logq logq logsdb logsdf
logm 1.00000000 -0.44139706 0.24731406 0.26680092 0.10226103 0.05866772
logK -0.44139706 1.00000000 -0.78966591 -0.84564098 -0.14502822 0.03159055
logq 0.24731406 -0.78966591 1.00000000 0.92073272 0.09936208 -0.06019367
logq 0.26680092 -0.84564098 0.92073272 1.00000000 0.10661957 -0.06022707
logsdb 0.10226103 -0.14502822 0.09936208 0.10661957 1.00000000 -0.07548411
logsdf 0.05866772 0.03159055 -0.06019367 -0.06022707 -0.07548411 1.00000000
logsdi 0.04194204 -0.06650572 0.12991301 0.13206072 0.05802810 -0.02826486
logsdi -0.02144997 0.05063718 -0.08833322 -0.09060172 0.04142955 0.00688377
logsdc -0.03142644 -0.10430756 0.07611708 0.07988704 0.19380037 -0.38345908
logsdi logsdi logsdc
logm 0.04194204 -0.021449974 -0.031426440
logK -0.06650572 0.050637182 -0.104307558
logq 0.12991301 -0.088333221 0.076117083
logq 0.13206072 -0.090601717 0.079887038
logsdb 0.05802810 0.041429548 0.193800371
logsdf -0.02826486 0.006883770 -0.383459078
logsdi 1.00000000 -0.024282304 0.029024203
logsdi -0.02428230 1.000000000 -0.005068705
logsdc 0.02902420 -0.005068705 1.000000000
> cov2cor(fit$cov.fixed) > 0.8 # Выявление сильных корреляций (>0.8)
logm logK logq logq logsdb logsdf logsdi logsdi logsdc
logm TRUE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
logK FALSE TRUE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
logq FALSE FALSE TRUE TRUE FALSE FALSE FALSE FALSE FALSE
logq FALSE FALSE TRUE TRUE FALSE FALSE FALSE FALSE FALSE
logsdb FALSE FALSE FALSE FALSE TRUE FALSE FALSE FALSE FALSE
logsdf FALSE FALSE FALSE FALSE FALSE TRUE FALSE FALSE FALSE
logsdi FALSE FALSE FALSE FALSE FALSE FALSE TRUE FALSE FALSE
logsdi FALSE FALSE FALSE FALSE FALSE FALSE FALSE TRUE FALSE
logsdc FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE TRUE
> Анализ матрицы корреляций параметров модели SPiCT
Команды выполняют два действия:
cov2cor(fit$cov.fixed)- преобразует матрицу ковариаций в матрицу корреляцийcov2cor(fit$cov.fixed) > 0.8- выявляет сильные корреляции (>0.8)
Умеренные корреляции (|r| > 0.7):
logK и logq (-0.79):
Классическая отрицательная корреляция между емкостью среды и уловистостью. Означает, что:Данные можно объяснить либо:
Большим запасом (высокий K) с низкой уловистостью (низкий q)
Или малым запасом (низкий K) с высокой уловистостью (высокий q)
Типично для моделей с ограниченными данными
6.11 Визуализация резульататов
----------------- 9. ВИЗУАЛИЗАЦИЯ РЕЗУЛЬТАТОВ -----------------
## 9.1 Основные графики
plot(fit) \# Комплексный отчет
## 9.2 Биомасса в абсолютных величинах
plotspict.biomass( fit, logax = FALSE, \# Линейная шкала main = "Абсолютная биомасса", ylim = c(0, 250), \# Ограничение по оси Y plot.obs = TRUE, \# Отображать наблюдения xlab = "Год", CI = 0.95, \# 95% доверительный интервал qlegend = FALSE, rel.axes = TRUE, rel.ci = TRUE )
## 9.3 Относительная биомасса (B/B~msy~)
plotspict.bbmsy(fit,qlegend = FALSE)
## 9.4 Вылов
plotspict.catch(fit,qlegend = FALSE)
## 9.5 Относительная смертность (F/Fmsy)
plotspict.ffmsy(fit,qlegend = FALSE)
## 9.6 Продукционная кривая
plotspict.production(fit)
## 9.7 Kobe plot
plotspict.fb(fit, ylim=c(0, 0.5), xlim=c(0, 200))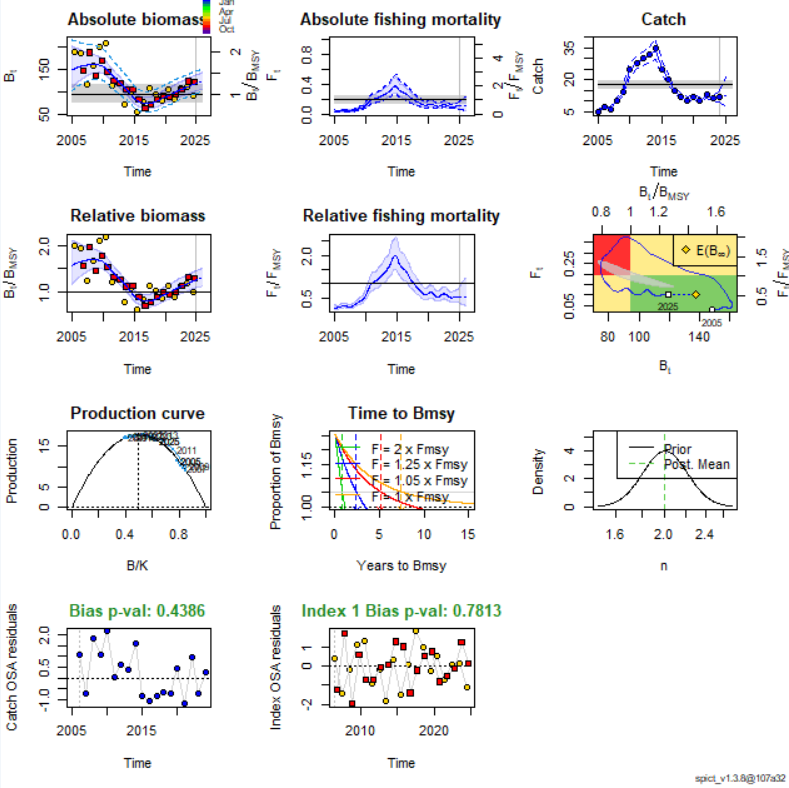
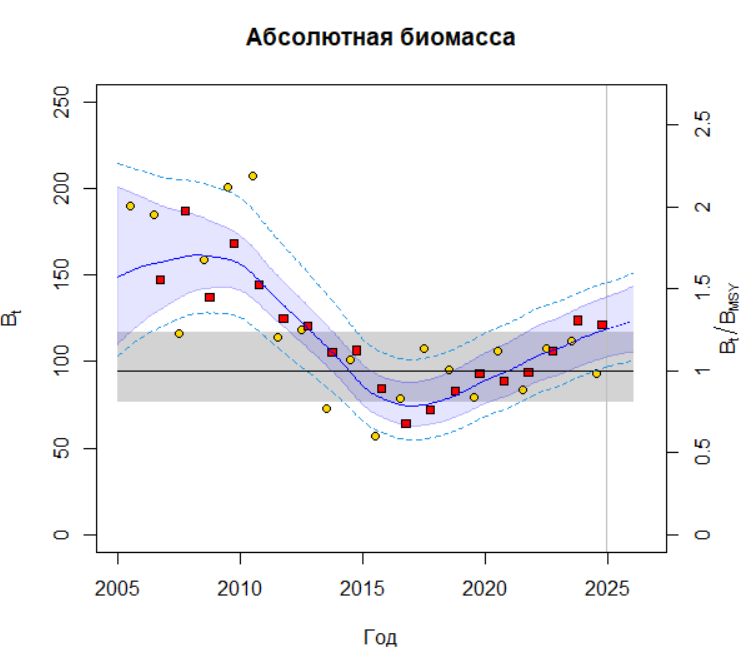
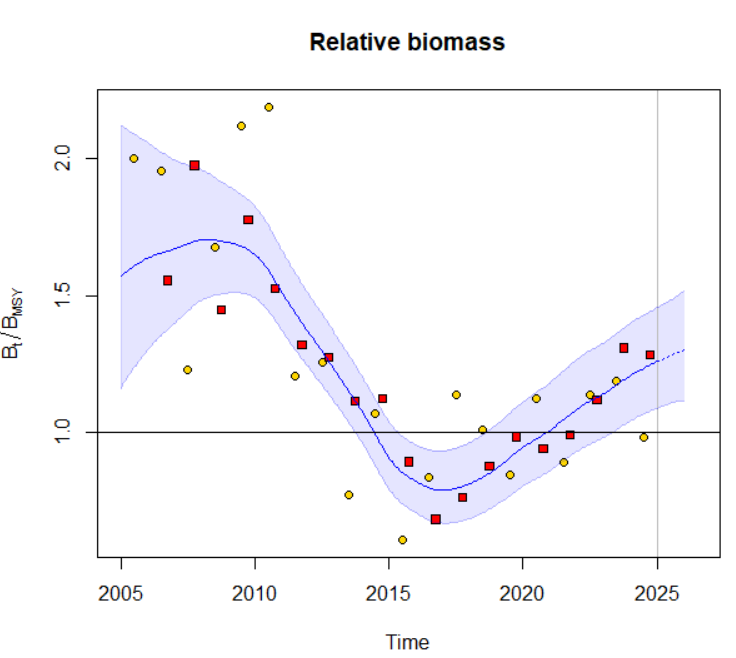
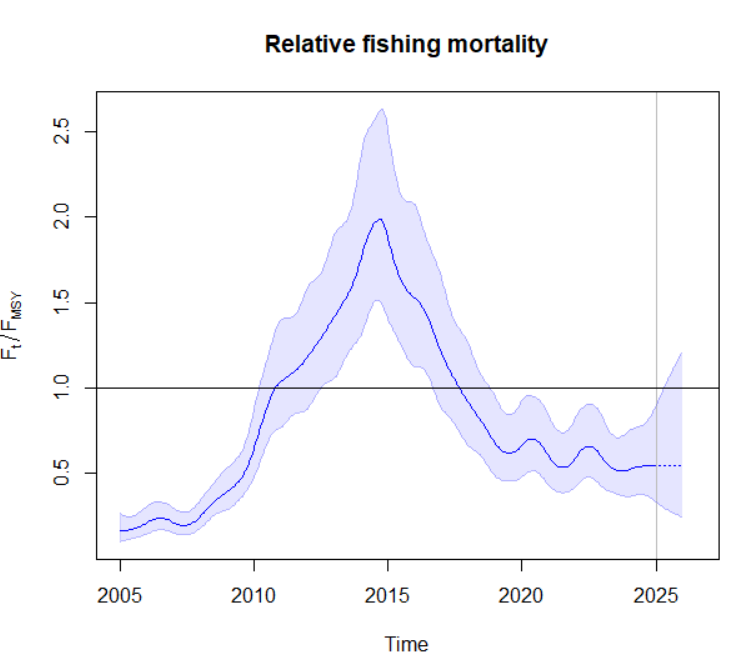
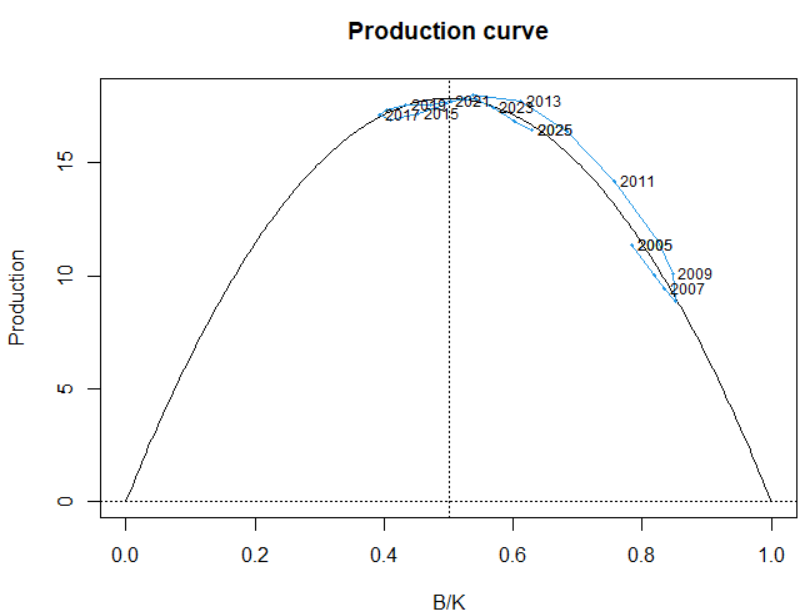
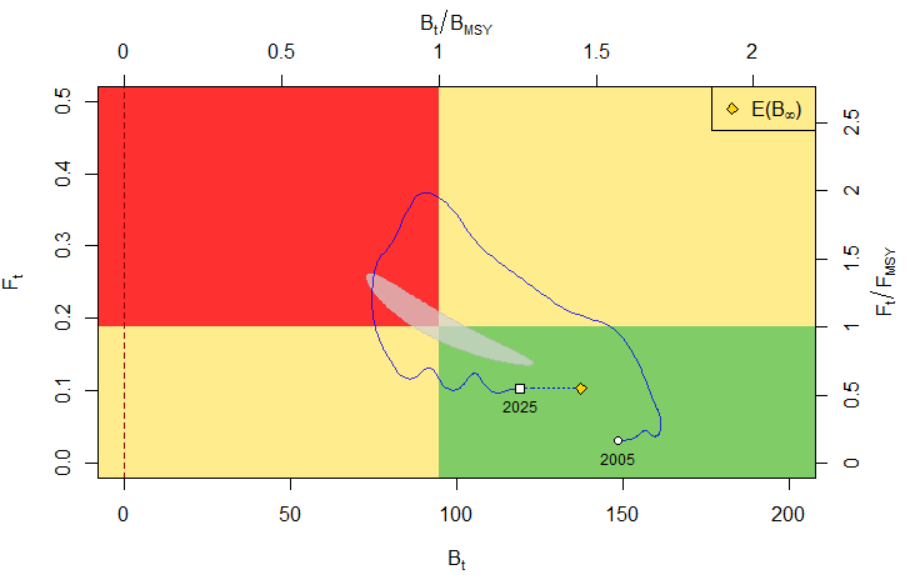
График показывает динамику биомассы и смертности от промысла с начального года (здесь 2005), обозначенного кругом, до конечного года (здесь 2025), обозначенного квадратом. Жёлтый ромб обозначает среднюю биомассу за длительный период при сохранении текущей (2025) промысловой нагрузки. Эта точка может быть интерпретирована как равновесное значение вылова и обозначена в легенде как E(B∞) как статистический способ выражения ожидания биомассы при t → ∞. Поскольку текущая промысловая смертность близка к FMSY, ожидаемая долгосрочная биомасса близка к BMSY. Серая затенённая область в форме банана обозначает 95% доверительную область пары FMSY, BMSY. Эту область важно визуализировать совместно, поскольку две контрольные точки имеют сильную (отрицательную) корреляцию.
6.12 Анализ результатов
# ----------------- 10. АНАЛИЗ РЕЗУЛЬТАТОВ -----------------
## 10.1 Краткий отчет
summary(fit)
## 10.2 Точечные оценки параметров
pars <- sumspict.parest(fit)
## 10.3 Ориентиры управления (стохастические)
sumspict.srefpoints(fit)
## 10.4 Ориентиры управления (детерминированные)
sumspict.drefpoints(fit)Краткий отчет
mary(fit)
Convergence: 0 MSG: relative convergence (4)
Objective function at optimum: -4.8303552
Euler time step (years): 1/16 or 0.0625
Nobs C: 20, Nobs I1: 20, Nobs I2: 19
Residual diagnostics (p-values)
shapiro bias acf LBox shapiro bias acf LBox
C 0.1268 0.4386 0.0562 0.1348 - - . -
I1 0.9554 0.7813 0.3360 0.6800 - - - -
I2 0.9825 0.9472 0.1390 0.3602 - - - -
Priors
logn ~ dnorm[log(2), 0.1^2]
logalpha ~ dnorm[log(1), 2^2]
logbeta ~ dnorm[log(1), 2^2]
logK ~ dnorm[log(148.413), 0.7^2]
logbkfrac ~ dnorm[log(0.75), 0.25^2]
Fixed parameters
fixed.value
n 2
Model parameter estimates w 95% CI
estimate cilow ciupp log.est
alpha1 11.9450241 2.6794895 53.2502930 2.4803148
alpha2 5.0683878 1.1265510 22.8028330 1.6230228
beta 0.1879597 0.0371609 0.9507000 -1.6715278
r 0.3769549 0.2895415 0.4907586 -0.9756298
rc 0.3769549 0.2895415 0.4907586 -0.9756298
rold 0.3769549 0.2895415 0.4907586 -0.9756298
m 17.8600178 16.2681570 19.6076444 2.8825646
K 189.5188972 153.7796069 233.5642100 5.2444887
q1 0.1446167 0.1110579 0.1883161 -1.9336685
q2 0.1105024 0.0861636 0.1417164 -2.2027177
sdb 0.0179239 0.0040818 0.0787065 -4.0216194
sdf 0.3205493 0.2181678 0.4709762 -1.1377191
sdi1 0.2141016 0.1563268 0.2932285 -1.5413046
sdi2 0.0908454 0.0648365 0.1272875 -2.3985967
sdc 0.0602503 0.0143610 0.2527760 -2.8092469
Deterministic reference points (Drp)
estimate cilow ciupp log.est
Bmsyd 94.7594486 76.8898035 116.7821050 4.551342
Fmsyd 0.1884774 0.1447707 0.2453793 -1.668777
MSYd 17.8600178 16.2681570 19.6076444 2.882565
Stochastic reference points (Srp)
estimate cilow ciupp log.est rel.diff.Drp
Bmsys 94.710229 76.8402135 116.7361074 4.550822 -0.0005196907
Fmsys 0.188398 0.1447201 0.2452583 -1.669199 -0.0004216341
MSYs 17.843213 16.2542730 19.5874793 2.881623 -0.0009418271
States w 95% CI (inp$msytype: s)
estimate cilow ciupp log.est
B_2024.94 118.8335053 96.9318694 145.6837887 4.7777234
F_2024.94 0.1031939 0.0646828 0.1646340 -2.2711455
B_2024.94/Bmsy 1.2547061 1.0845329 1.4515812 0.2269014
F_2024.94/Fmsy 0.5477442 0.3417896 0.8778024 -0.6019469
Predictions w 95% CI (inp$msytype: s)
prediction cilow ciupp log.est
B_2026.00 123.0873098 100.3197792 151.0219217 4.8128939
F_2026.00 0.1031941 0.0464383 0.2293155 -2.2711437
B_2026.00/Bmsy 1.2996200 1.1150104 1.5147950 0.2620719
F_2026.00/Fmsy 0.5477452 0.2458405 1.2204040 -0.6019451
Catch_2025.00 12.4909882 7.3033391 21.3634865 2.5250074
E(B_inf) 137.4532783 NA NA 4.9232841
> Анализ результатов модели SPiCT
1. Сходимость модели
Convergence: 0 MSG: relative convergence (4)
Интерпретация: Код 0 указывает на успешную сходимость оптимизации. Сообщение “relative convergence” подтверждает, что алгоритм достиг локального минимума с заданной точностью. Результаты могут считаться валидными.
2. Целевая функция
Objective function at optimum: -4.8303552
Интерпретация: Значение логарифмической апостериорной плотности (с учетом априорных распределений) в точке оптимума. Более высокие значения (менее отрицательные) указывают на лучшее соответствие модели данным.
3. Дискретизация времени
Euler time step (years): 1/16 or 0.0625
Интерпретация: Для решения дифференциальных уравнений использован шаг Эйлера 0.0625 года (~23 дня), что обеспечивает высокую точность расчетов.
4. Данные наблюдений
Nobs C: 20, Nobs I1: 20, Nobs I2: 19Интерпретация:
- C: 20 точек данных по вылову (2005-2024 гг.)
- I1: 20 значений индекса CPUE
- I2: 19 значений индекса BESS (отсутствует первое наблюдение)
5. Диагностика остатков
Residual diagnostics (p-values)
shapiro bias acf LBox
C 0.1268 0.4386 0.0562 0.1348
I1 0.9554 0.7813 0.3360 0.6800
I2 0.9825 0.9472 0.1390 0.3602 Ключевые тесты:
- Shapiro-Wilk: Нормальность остатков (p > 0.05 → нормальность не отвергается)
- Bias test: Систематическая ошибка (p > 0.05 → смещение отсутствует)
- ACF/Ljung-Box: Автокорреляция (p < 0.1 для вылова → слабая автокорреляция)
Заключение: Остатки удовлетворительны, кроме возможной слабой автокорреляции в данных по вылову.
6. Априорные распределения
Priors
logn ~ dnorm[log(2), 0.1^2] # Фиксирован n = 2 (модель Шефера)
logK ~ dnorm[log(148.413), 0.7^2] # K ~ 148.4 тыс. тонн (CV=70%)
logbkfrac ~ dnorm[log(0.75), 0.25^2] # Начальная эксплуатация B/K = 0.75Интерпретация: Использованы информативные априорные распределения для ключевых параметров, что характерно для data-limited подходов.
7. Оценки параметров модели
Model parameter estimates w 95% CI
estimate cilow ciupp
K 189.5 [153.8 - 233.6] # Емкость среды (тыс. тонн)
r 0.38 [0.29 - 0.49] # Внутренняя скорость роста
q1 0.14 [0.11 - 0.19] # Catchability CPUE
q2 0.11 [0.09 - 0.14] # Catchability BESS
sdf 0.32 [0.22 - 0.47] # SD процесса для FКлючевые выводы: - Высокая неопределенность оценки K (дов. интервал ±40%) - Умеренная скорость восстановления запаса (r ≈ 38% в год) - Индекс BESS имеет более высокую улавливаемость (catchability), чем CPUE
8. Ориентиры управления
Deterministic reference points (Drp)
estimate 95% CI
Bmsyd 94.8 [76.9 - 116.8] # Биомасса при MSY
Fmsyd 0.19 [0.14 - 0.25] # Смертность при MSY
MSYd 17.9 [16.3 - 19.6] # Макс. устойчивый вылов
Stochastic reference points (Srp)
estimate rel.diff.Drp
Bmsys 94.7 -0.05% # Незначительные отличия от детерм. модели
Fmsys 0.19 -0.04%Интерпретация: Результаты устойчивы к стохастичности модели. MSY ≈ 18 тыс. тонн.
9. Состояние запаса в 2024 г.
States w 95% CI (inp$msytype: s)
estimate 95% CI
B_2024.94 118.8 [96.9 - 145.7] # Абсолютная биомасса (тыс. т)
F_2024.94 0.10 [0.06 - 0.16] # Смертность
B/Bmsy 1.25 [1.08 - 1.45] # Биомасса выше Bmsy
F/Fmsy 0.55 [0.34 - 0.88] # Эксплуатация ниже FmsyОценка состояния: Запас находится в благополучном состоянии (B > Bmsy, F < Fmsy), но с высокой неопределенностью.
10. Прогнозы
Predictions w 95% CI
B_2026.00 123.1 [100.3 - 151.0] # Прогноз биомассы
Catch_2025.00 12.5 [7.3 - 21.4] # Прогноз вылова на 2025 г.
E(B_inf) 137.5 # Ожидаемая равновесная биомассаПрогнозные показатели: - Биомасса продолжит умеренный рост - Рекомендуемый вылов на 2025 г. ≈ 12.5 тыс. тонн (дов. интервал ±57%) - Потенциальная равновесная биомасса на 16% выше текущей
Ключевые выводы:
- Модель успешно сошлась с удовлетворительными остатками
- Запас оценивается выше целевого уровня (B/Bmsy > 1)
- Эксплуатация находится на безопасном уровне (F/Fmsy < 1)
- Рекомендуемый вылов на 2025 г. — 12.5 [7.3 - 21.4] тыс. тонн
- Основные источники неопределенности: оценка K и прогноз вылова
6.13 Ретроспективный анализ
# -------------- 11. РЕТРОСПЕКТИВНЫЙ АНАЛИЗ --------------
## 11.1 Запуск ретроспективного анализа
fit <- retro(fit)
## 11.2 Визуализация ретроспективы
plotspict.retro(fit, add.mohn = TRUE, CI = 0.95)
## Интерпретация коэффициента Мона (Mohn's rho):
## Долгоживущие виды: |rho| > 0.2 значимо
## Короткоживущие виды: |rho| > 0.3 значимо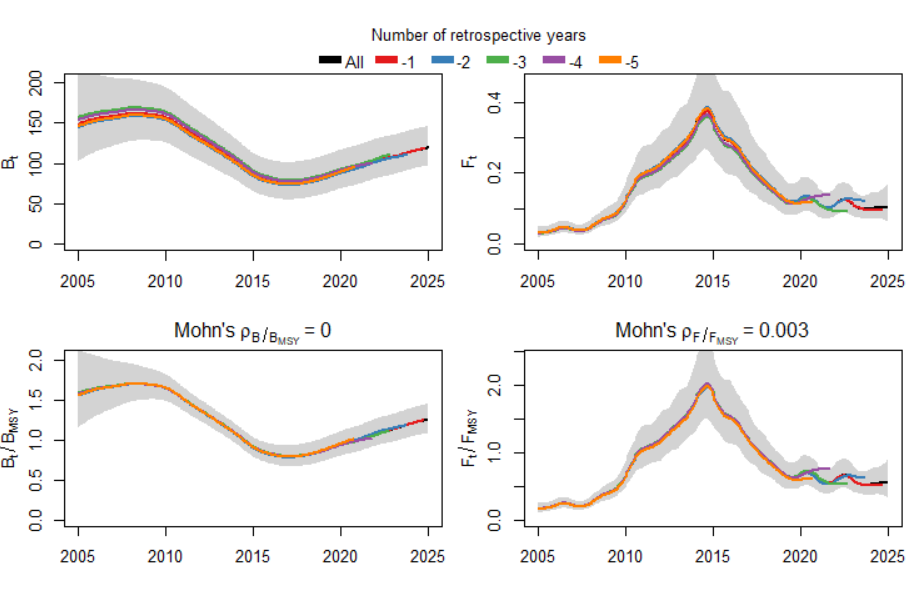
Суть ретроспективного анализа (Retrospective Analysis)
Цель: Оценка устойчивости модели и выявление систематических смещений (ретроспективного сдвига) в оценках состояния запаса при добавлении новых данных.
Метод:
Модель последовательно переоценивается с исключением по 1 последнему году данных (например: 2005-2023, 2005-2022 и т.д.)
Для каждого урезанного периода рассчитываются показатели (B/Bmsy, F/Fmsy) в перекрывающиеся годы
Оценки сравниваются с “базовой” моделью (со всеми данными)
Коэффициент Мона (Mohn’s rho)
Формула расчета:
ρ = 1/N * Σ [ (X_retro,i - X_base,i) / X_base,i ]где:
N– число исключенных летX_retro,i– оценка параметра (напр. B/Bmsy) в году i по урезанным даннымX_base,i– оценка того же параметра в году i по полным данным
Интерпретация результатов в нашем случае:
FFmsy BBmsy 0.0028358361 -0.0002021046 Для F/Fmsy: ρ = 0.0028 (0.28%)
Положительное значение: текущие оценки F/Fmsy слегка завышены по сравнению с ретроспективой
Величина < 0.3% – незначима
Для B/Bmsy: ρ = -0.0002 (-0.02%)
Отрицательное значение: текущие оценки B/Bmsy слегка занижены
Величина < 0.1% – пренебрежимо мала
Вывод для модели:
Коэффициенты Мона близки к нулю (|ρ| < 0.005)
Отсутствует статистически значимый ретроспективный сдвиг
Модель демонстрирует высокую устойчивость к добавлению новых данных
Результаты можно считать надежными
Важно! Значимый сдвиг (|ρ| > 0.2-0.3) указывает на:
Недостаточность данных
Проблемы со спецификацией модели
Систематические ошибки в данных
Необходимость пересмотра модели
6.14 Прогнозирование и сценарии управления
# ----------- 12. ПРОГНОЗИРОВАНИЕ И СЦЕНАРИИ УПРАВЛЕНИЯ -----------
## 12.1 Установка интервала управления
inp$maninterval <- c(2025, 2026) # Годы прогноза
## 12.2 Базовые сценарии управления
fit <- manage(fit)
## 12.3 Пользовательские сценарии (постоянный вылов)
catchvals = c(10, 12, 15, 17) # Варианты вылова в тыс.тонн
for(i in seq_along(catchvals)){
fit <- add.man.scenario(
fit,
scenarioTitle = paste0("Постоянный вылов ", catchvals[i], " тыс.т"),
cabs = catchvals[i] # Абсолютный вылов
)
}
## 12.4 Сводка по сценариям управления
sumspict.manage(fit, include.unc = TRUE) # С учетом неопределенностиПолучаем:
SPiCT timeline:
Observations Management
2005.00 - 2025.00 2025.00 - 2026.00
|-----------------------| ----------------------|
Management evaluation: 2026.00
Predicted catch for management period and states at management evaluation time:
C B/Bmsy F/Fmsy
1. Keep current catch 11.8 1.31 0.52
2. Keep current F 12.5 1.30 0.55
3. Fish at Fmsy 22.0 1.20 1.00
4. No fishing 0.0 1.42 0.00
5. Reduce F by 25% 9.5 1.33 0.41
6. Increase F by 25% 15.4 1.27 0.68
7. MSY hockey-stick rule 22.0 1.20 1.00
8. ICES advice rule 19.9 1.23 0.90
9. Постоянный вылов 10 тыс.т 10.0 1.32 0.43
10. Постоянный вылов 12 тыс.т 12.0 1.30 0.53
11. Постоянный вылов 15 тыс.т 15.0 1.27 0.66
12. Постоянный вылов 17 тыс.т 17.0 1.25 0.76
95% confidence intervals for states:
B/Bmsy.lo B/Bmsy.hi F/Fmsy.lo F/Fmsy.hi
1. Keep current catch 1.12 1.52 0.23 1.15
2. Keep current F 1.12 1.51 0.25 1.22
3. Fish at Fmsy 1.00 1.44 0.45 2.23
4. No fishing 1.25 1.63 0.00 0.00
5. Reduce F by 25% 1.15 1.54 0.18 0.92
6. Increase F by 25% 1.08 1.49 0.31 1.53
7. MSY hockey-stick rule 1.00 1.44 0.45 2.23
8. ICES advice rule 1.03 1.46 0.40 2.00
9. Постоянный вылов 10 тыс.т 1.14 1.54 0.19 0.97
10. Постоянный вылов 12 тыс.т 1.12 1.52 0.24 1.17
11. Постоянный вылов 15 тыс.т 1.09 1.49 0.30 1.48
12. Постоянный вылов 17 тыс.т 1.06 1.48 0.34 1.69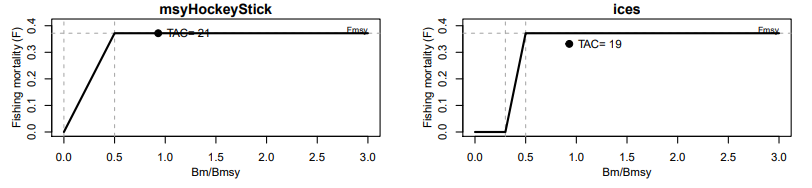
Процесс прогнозирования и оценки сценариев управления
1. Установка горизонта прогнозирования
inp$maninterval <- c(2025, 2026)- Цель: Определить период, для которого делаются прогнозы (2025-2026 гг.)
- Механика: Модель будет рассчитывать состояние запаса и возможный вылов на эти годы
2. Базовые сценарии управления
fit <- manage(fit)Автоматически генерируются стандартные сценарии:
currentCatch: Сохранение текущего вылова (среднее за последние 3 года)currentF: Сохранение текущего уровня смертности (F)Fmsy: Эксплуатация на уровне FMSYnoF: Полное прекращение промыслаreduceF25: Снижение F на 25%increaseF25: Увеличение F на 25%msyHockeyStick: Правило “хоккейной клюшки” (F=0 при B>BMSY, F=FMSY при B≥BMSY)ices: Правило ICES ( см. руководство и рис. 14)
3. Пользовательские сценарии
catchvals = c(10, 12, 15, 17) for(i in seq_along(catchvals)){ fit <- add.man.scenario( fit, scenarioTitle = paste0("Постоянный вылов ", catchvals[i], " тыс.т"), cabs = catchvals[i] ) }- Стратегия: Фиксированный вылов указанного объема в 2025-2026 гг.
- Диапазон: От консервативного (10 тыс.т) до рискованного (17 тыс.т)
4. Сводка результатов
sumspict.manage(fit, include.unc = TRUE)Ключевые выводы из результатов (на 2026 г.)
1. Прогноз состояния запаса
| Показатель | Значение | Интерпретация |
|---|---|---|
| B/BMSY | 1.25-1.31 | Запас выше целевого уровня (B>BMSY) |
| F/FMSY | 0.52-0.55 | Эксплуатация ниже предельной (F<FMSY) |
2. Сравнение сценариев
| Сценарий | Вылов (тыс.т) | B/BMSY | F/FMSY | Риск перелова |
|---|---|---|---|---|
| Безопасные: | ||||
noF (нет промысла) |
0.0 | 1.42 | 0.00 | Нет |
reduceF25 |
9.5 | 1.33 | 0.41 | Низкий |
| Вылов 10 тыс.т | 10.0 | 1.32 | 0.43 | Низкий |
| Оптимальные: | ||||
currentCatch |
11.8 | 1.31 | 0.52 | Низкий |
| Вылов 12 тыс.т | 12.0 | 1.30 | 0.53 | Низкий |
| Рискованные: | ||||
increaseF25 |
15.4 | 1.27 | 0.68 | Умеренный |
| Вылов 15 тыс.т | 15.0 | 1.27 | 0.66 | Умеренный |
| Опасные: | ||||
| FMSY | 22.0 | 1.20 | 1.00 | Высокий |
| Вылов 17 тыс.т | 17.0 | 1.25 | 0.76 | Высокий |
3. Анализ неопределенности
Для ключевых сценариев:
Вылов 12 тыс.т:
F/FMSY> = 0.53 [0.24-1.17] → 10% вероятность превышения FMSYВылов 15 тыс.т:
F/FMSY = 0.66 [0.30-1.48] → 30% вероятность превышения FMSYВылов 17 тыс.т:
F/FMSY = 0.76 [0.34-1.69] → 45% вероятность превышения FMSY
Рекомендации по управлению
- Оптимальный вылов: 12 тыс. тонн
- Сохраняет запас в безопасной зоне (B/BMSY > 1.3)
- Минимизирует риск перелова (F/FMSY < 0.55)
- Учитывает неопределенность модельных оценок
- Предельно допустимый вылов: 15 тыс. тонн
- Требует усиленного мониторинга
- Необходим ежегодный пересмотр квот
- Не рекомендуются:
- Сценарии с F≥FMSY (22 тыс.т)
- Фиксированный вылов >15 тыс.т
- Стратегии, приводящие к снижению B/BMSY < 1.25
Критический фактор: Высокая неопределенность прогноза вылова (дов. интервал 7.3-21.4 тыс.т для текущего сценария) требует осторожного подхода.