35 Градиентный бустинг
Если Random Forest — это слаженный хор, где все голоса звучат одновременно, то градиентный бустинг — это опытный скульптор, который последовательно и терпеливо шлифует свою статую, с каждым движением устраняя всё новые неточности. Градиентный бустинг представляет собой мощный ансамблевый алгоритм машинного обучения, который строит деревья последовательно, а не параллельно. Каждое следующее дерево учится на ошибках предыдущих, создавая всё более точную модель. В гидробиологии он особенно ценен для работы со сложными нелинейными зависимостями, где факторы среды взаимодействуют друг с другом неочевидным образом. Представьте, что вы изучаете, как температура, кислород и кормовая база влияют на биомассу леща в водохранилище. Вы замечаете, что зависимость нелинейна: есть оптимальный температурный диапазон, пороговые значения кислорода, эффект насыщения от кормовой базы. Процесс обучения градиентного бустинга напоминает работу учёного-гидробиолога, который постепенно уточняет свои представления. Сначала строится первое дерево, которое даёт базовое предсказание — например, среднюю биомассу 120 кг/га. Затем приходит второе дерево и замечает, что в холодных водоёмах биомасса систематически занижена, поэтому оно учится вычитать 30 кг/га для температур ниже 10°C. Третье дерево обнаруживает проблему с кислородом и вносит поправку для гипоксийных условий. Четвёртое дерево учитывает эффект насыщения от кормовой базы. И так продолжается сотни раз, пока модель не станет учитывать все нюансы и взаимодействия факторов. В отличие от Random Forest, где деревья строятся независимо, в бустинге каждое новое дерево специально обучается предсказывать остаточные ошибки предыдущих деревьев. Алгоритм использует математический аппарат градиентного спуска для минимизации функции ошибки, двигаясь небольшими шагами в направлении наибольшего улучшения. Современные реализации вроде XGBoost включают сложные механизмы регуляризации, которые предотвращают переобучение и делают модель более обобщаемой. Градиентный бустинг особенно эффективен в экологических исследованиях благодаря своей способности работать со сложными нелинейностями. Модель прекрасно улавливает пороговые эффекты, взаимодействия переменных и насыщающие зависимости, которые часто встречаются в экологических системах. Благодаря последовательному обучению, бустинг может достигать высокой точности даже на относительно небольших выборках, что особенно важно в полевых исследованиях. Алгоритм учится постепенно, фокусируясь на самых сложных случаях, что делает его устойчивым к случайным выбросам в данных. При этом мы сохраняем возможность анализировать важность признаков и даже визуализировать отдельные деревья, чтобы понять логику принятия решений. В нашем практическом скрипте мы создаём реалистичную модель для прогнозирования биомассы леща в водохранилище по гидрологическим и кормовым показателям. Наши данные включают 15 лет наблюдений с ежемесячными замерами, что имитирует реальный гидробиологический мониторинг. Мы создаём синтетические данные с реалистичными зависимостями: сезонные колебания температуры и связанные с ними изменения кислорода, динамику кормовой базы с трендом и сезонностью, а также сложные нелинейные эффекты — оптимальный температурный диапазон 18-22°C, критический порог кислорода 4 мг/л, насыщение кормовой базы. При этом мы намеренно добавляем в данные пропуски, имитируя реальную ситуацию, когда некоторые измерения не удалось провести.
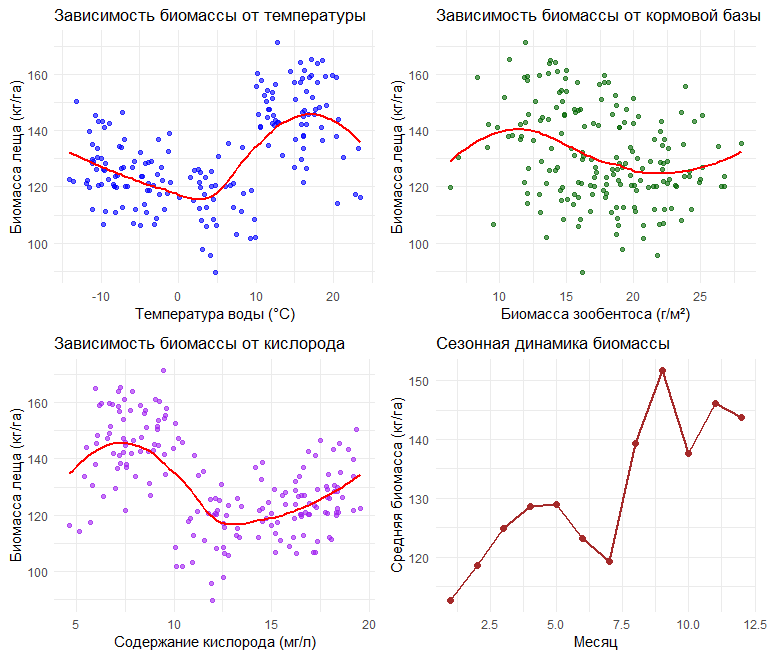
После визуализации данных мы видим чёткие нелинейные зависимости: оптимальный диапазон температур для биомассы леща, пороговый эффект содержания кислорода, насыщающую зависимость от кормовой базы и сезонную динамику биомассы. Затем мы обучаем модель XGBoost с 500 деревьями, скоростью обучения 0.1, максимальной глубиной деревьев 6 уровней и регуляризацией для предотвращения переобучения. Результаты модели впечатляют: она объясняет 47.1% вариации биомассы со средней ошибкой прогноза 12.9 кг/га. Наиболее важными признаками оказались температура, кислород и месяц наблюдений. Особенно показательно сравнение с линейной регрессией: линейная модель показывает точность 30.7%, в то время как XGBoost достигает 47.1%, что означает улучшение на 11.3% по точности. Это демонстрирует ключевое преимущество градиентного бустинга — способность улавливать сложные нелинейные зависимости, которые линейные модели просто не в состоянии описать.
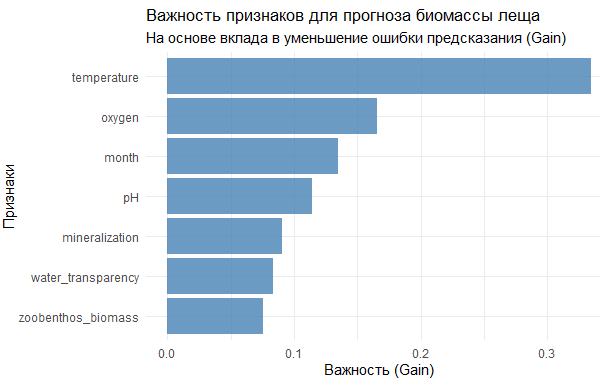
Мы также создали функцию прогнозирования, которая не только выдаёт точечную оценку биомассы, но и классифицирует условия среды как оптимальные, критические или удовлетворительные. Это превращает модель из чисто математического инструмента в практический помощник для гидробиологов. Анализ чувствительности показывает, как биомасса леща реагирует на изменение температуры при прочих равных условиях — это ценная информация для прогнозирования последствий климатических изменений. Таким образом, если Random Forest — это демократический совет экспертов, то градиентный бустинг — это команда специалистов, где каждый новый член учится на ошибках предыдущих, создавая всё более совершенный коллективный интеллект.